规模本身不是答案——机器人数据公司究竟做错了什么
作者:苏亮 · 全世萝卜 Panbotica · 2026年4月22日 · 约 15 分钟阅读
 π0.7 学习笔记封面
π0.7 学习笔记封面
文档类型:个人学习笔记
主题:π0.7 为什么重要,以及机器人数据公司究竟做错了什么
原始来源:Shreyas Gite 在 X 发布的长文《π0.7 and Everything Robot Data Companies Are Getting Wrong》
相关参考:Physical Intelligence 官方介绍;论文 PDF(pi.website/download/pi07.pdf)
整理目标:在尽量保持原作论证顺序与核心判断的前提下,整理成适合中文研究与反复查阅的图文学习笔记
一、先给出最核心的结论
这篇文章最重要的判断,不是单纯地夸奖 π0.7很强,而是借 π0.7 来反驳当前机器人数据行业里一种很流行、但作者认为过于粗糙的叙事:只要不断收集更多第一视角人类数据,再把这些数据喂给机器人模型,问题最终就会自己解决。
作者的观点恰恰相反。他认为,机器人学习的问题从来不只是"数据够不够多",而更是"数据有没有被正确组织、正确标注、正确条件化,以及是否能让模型在冲突策略中学到有用结构"。因此,π0.7 的关键进步并不是神秘的"涌现能力"突然降临,而是来自一系列完全可以点名的工程设计选择。
规模本身不是答案;没有上下文、没有元数据、没有条件化的规模,甚至可能是诅咒。
二、作者到底在反对什么
作者开篇就针对一种常见叙事开火:很多人看到机器人领域的 demo,会以为只要积累足够多的人类第一视角数据,模型最终就会获得类似大语言模型那样的泛化能力。文章特意点到了一个典型案例:如果你只看到某些 demo 宣称自己拥有数十万小时的人类数据,再加上很少量的任务特定数据,你很容易相信"数据量就是答案"。
但作者认为,这种理解危险地忽略了数据工程。原因很简单:机器人动作数据不是普通互联网文本。不同演示之间可能包含不同策略、不同速度、不同质量、不同控制方式、不同局部目标,甚至彼此冲突。如果你只是把它们一股脑混到一起训练,那么模型学到的很可能不是更强泛化,而是一个把冲突行为平均化之后的模糊策略。
换句话说,这篇文章反对的不是"多数据"本身,而是把数据规模当成唯一变量、把数据工程视为次要细节的行业思路。
三、作者对 π0.7 的总体判断
作者特意对标题中的 "Emergent Capabilities"做了一个保留。他认为,这个说法多少有些"卖大了"。因为在他看来,π0.7 的提升主要并不是无法解释的突现,而是几个明确可描述、可复现、可工程化的选择叠加出来的结果。
这些关键选择可以被整理成下面这张表:
| |
|---|
| |
| |
| |
| 引入 affordances / subgoal images / task breakdowns | |
| 训练中对 affordances 与 instructions 做 dropout | |
| |
π0.7 的本质不是"更大",而是"更会组织异质数据,并用条件化把这些数据从噪声变成结构"。
四、数据层:π0.7 到底用了什么数据
作者指出,π0.7 几乎使用了"除仿真之外的一切数据"。这些数据包括遥操作示范、自主 rollout、RL 专家轨迹、明显失败的样本、第一视角人类视频以及网页数据。
这个点非常重要,因为它代表了一个和许多"单一来源数据神话"完全不同的方向。官方介绍页也明确强调,π0.7 的广泛泛化能力来自广泛且多样的数据,包括不同机器人、不同控制模态、人类数据以及由不同策略跑出来的自主 episode。
| |
|---|
| |
| |
| RL specialist trajectories | |
| |
| |
| |
| |
这里最值得注意的一点是:异质数据本身并不会自动产生泛化,只有当这些数据被正确地对齐与注释时,它们才可能真正有用。这也是文章后面为什么反复强调 metadata 和 prompt conditioning。
五、真正的重活发生在哪里:Prompt 本身
作者有一句必须原样记住的话:
"The heavy lifting happens in the prompt itself."
这句话的意思不是"prompt engineering 万能",而是说,π0.7 的泛化能力在很大程度上不是来自某个神秘的模型内部变化,而是来自于输入条件本身被设计得足够丰富。作者点出的几个关键条件包括:subgoal images、subtask instructions、episode metadata。这些条件在训练过程中还会被随机 dropout,使模型学会在测试时面对条件不完整的情况。
官方介绍也给出了类似但更系统的说法:π0.7 的关键在于把多样上下文加入 prompt,让模型不仅知道"要做什么",还知道"要如何做",甚至知道任务应以怎样的速度、质量或策略完成。
机器人基础模型的泛化,不只是数据规模问题,更是条件化设计问题。
六、为什么 naive scaling 会失败
这是整篇文章最锋利、也是最值得反复研究的一部分。
作者认为,很多机器人数据团队的默认逻辑是:数据越多,模型越强。但问题在于,如果不同 episode 中包含了互相冲突的策略,而你又没有元数据去解释这些差异,那么训练就会把这些行为"平均"到一起。文章引用论文措辞,把这种现象描述为 **"averaging together different behaviors"**。
这会导致一个反直觉现象:你灌进更多数据,模型反而更差。因为它并没有学到更丰富的策略,而是把不同策略互相冲淡了。
"Scale without context is a curse."
七、元数据为什么是规模化的真正钥匙
作者认为,真正让规模化成立的,不是数据量本身,而是对 episode 如何进行、表现质量如何、策略风格如何的高密度标注。
尤其关键的是,文章提到可以在训练时给元数据加入 data-quality score。这样,模型就能区分:哪些样本应该被主动模仿,哪些样本更多只是帮助自己了解状态分布,而不一定值得照着学动作。
官方介绍页也明确提到,metadata 可以编码任务完成速度、质量等信息,使 suboptimal 的自主数据也能安全纳入训练,因为模型知道这些样本应该如何被解释。
metadata 在 π0.7 里不是附属信息,而是解除数据冲突、扩大数据适用范围、提升可扩展性的信号层。
八、子目标图像:为什么它比语言更强
作者对 subgoal image conditioning的评价非常高,甚至把它看作 π0.7 成功的关键支点之一。
其核心思路是:与其运行一个昂贵的世界模型去 rollout 完整未来轨迹,不如把连续未来离散化,预测一个单独的未来帧,也就是 subgoal,然后让策略以此为条件来预测动作。
这会把原本复杂的开放式动作规划问题,转化为一个更容易收敛的逆动力学问题:
"从当前观测出发,什么动作能把我带到这个未来观测?"
官方介绍也与此一致,指出视觉子目标可以为当前子步骤提供精确的空间布局定义,而这些视觉子目标甚至可以由一个轻量级 world model 在测试时生成。
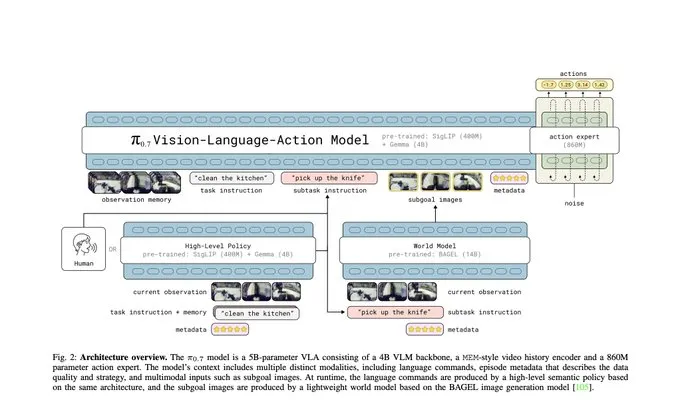 π0.7 架构总览图
π0.7 架构总览图π0.7 Vision-Language-Action Model 架构图:输入包含 observation memory、task instruction、subtask instruction、subgoal images、metadata,下方连接 High-Level Policy 与 World Model,右侧连接 action expert。图片来源:Physical Intelligence 论文
从这张图里可以看到,作者强调的那些条件化信号,并不是文字修饰,而是模型架构真正消费的输入部分。
九、为什么 π0.7 的指令跟随终于更像"听懂了"
作者提到,很多人抱怨 π0 和 π0.5 一旦把"drop x on the left"改成"drop x on the right",性能就会明显崩掉,因为训练数据在空间方向上本来就偏向某个分布。于是模型学到的不是语言,而是任务分布本身。
在这种情况下,简单增加更多语言多样性并不是完整答案。作者认为,π0.7 真正更有效的地方在于:subgoal image conditioning 比语言本身更强,更能压过原始训练分布带来的任务先验。
在机器人里,语言未必总是最高优先级的条件;在许多操作任务中,视觉化的未来状态描述比自然语言更能约束动作空间。
十、Cross-embodiment transfer:所谓"没有任务特定数据"到底是什么意思
作者非常小心地区分了一个容易被误解的概念:**"没有任务特定数据"并不等于"没有机器人本体相关数据"。**
也就是说,目标机器人仍然做过别的任务,模型对这个 embodiment 并不陌生;只是它没有见过"这个机器人执行这个具体任务"的演示而已。
这点很重要,因为它告诉我们:π0.7 证明的不是"完全零经验"神话,而是组合式泛化。也就是模型把过去在其他任务、其他说明、其他视觉状态中学到的能力重新拼接,去完成一个没见过的新任务。
十一、组合泛化为什么是北极星
作者明确说,compositional generalization is the north star。
这个判断的意义在于,它重新定义了机器人基础模型真正追求的目标。不是背会更多任务模板,也不是在一个固定机器人上做更多 task-specific fine-tuning,而是像大语言模型那样,把已经学过的技能进行新的组合与重组。
官方介绍页面同样把这一点当作 π0.7 的亮点,称其出现了机器人领域中早期的组合式泛化信号,能够把多个任务中的技能重新组合,去解决训练中没见过的问题,例如使用新型厨房电器,甚至在没有洗衣折叠数据的情况下让新机器人学会折衣服。
机器人基础模型真正的目标,不是会很多孤立技能,而是能把旧技能重新组合成新能力。
十二、这篇文章对机器人数据公司的产业判断
作者最后把讨论从模型方法上升到了产业层。
他认为,未来真正有价值的机器人数据公司,不能只出售"原始数据包",而必须自己去搭机器人、做训练、沉淀标注体系、掌握模型改进经验,然后把这些能力与 learnings 一起打包输出。
这背后的逻辑非常硬核:如果你只是一个纯数据供给方,而不真正理解这些数据如何进入训练、如何与条件化系统配合、如何影响泛化,那么你卖出的只是"素材",不是"学习系统"。真正愿意买单的机器人公司,最终想买的不会只是原始数据,而是经过验证的数据工程能力。
十三、最值得保留的三句原话
"Scale without context is a curse."
这句话几乎是全篇的中心结论。在机器人学习里,数据规模必须被上下文与条件化结构约束,否则规模只是把噪声和冲突放大。
"The heavy lifting happens in the prompt itself."
π0.7 的性能提升很大程度上发生在输入设计层,而不是神秘地发生在模型内部。
"It is that subgoal image conditioning has a stronger effect than language in overriding the task prior."
在机器人控制里,视觉条件对动作分布的约束,可能比自然语言条件更直接、更强。
十四、适合继续深入研究的问题
| |
|---|
| |
| data-quality score 如何定义才稳定 | |
| subgoal image 的生成质量对最终动作有多大影响 | |
| |
| |
| 决定 cross-embodiment generalization 的上限 |
十五、适合直接存入个人知识库的简版结论
- π0.7 的进步不是单纯靠更多数据,而是靠更好的条件化与更高密度的元数据。
- 异质数据要想真正有用,必须被 prompt、metadata 和子目标图像解释清楚。
- 没有上下文的信息型规模会把冲突策略平均掉,因此规模可能反而有害。
- 子目标图像条件化是 π0.7 的关键,它把开放式规划问题收缩成更可控的逆动力学问题。
- 无任务特定数据不等于无本体数据,π0.7 更准确展示的是组合式泛化。
- 未来有价值的机器人数据公司,卖的不是原始数据量,而是完整的数据工程与学习系统能力。
十六、我的总体评价
如果你说这篇对你"太重要了",我认为这个判断是对的。因为它并不是单纯在分析一个新模型,而是在重新定义机器人数据行业的价值来源。它真正重要的地方,不是"π0.7 又刷新了什么 demo",而是它把一个长期被讲得过于简单的问题——"数据越多越好吗?"——拆开成了一套更真实的技术命题:
- 子目标图像是否能把任务先验从语言分布拉回到空间状态分布;
- 模型是否真的在学习组合式泛化,而不是背诵任务分布。
从这个角度看,这篇文章的真正主题其实不是 π0.7,而是:机器人基础模型时代,数据公司必须升级成"数据 + 标注 + 训练 + 模型理解"的系统型公司。
参考文献
- Shreyas Gite on X: π0.7 and Everything Robot Data Companies Are Getting Wrong(x.com/shreyasgite)
- Physical Intelligence: π0.7: a Steerable Model with Emergent Capabilities(pi.website/blog/pi07)
- π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities(pi.website/download/pi07.pdf)
苏亮 · 全世萝卜 Panbotica · panbotica.net/pi07-notes

