今天,DeepSeek-V4的技术报告放出来,一组数据炸了。
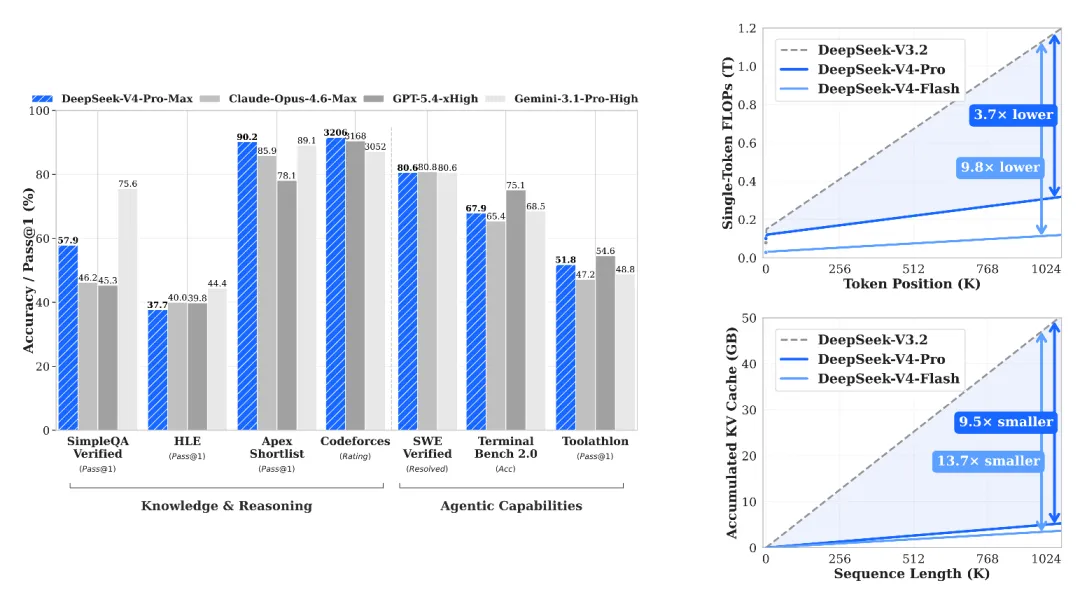
在100万Token的上下文窗口下,V4-Pro的单Token推理FLOPs只有上一代V3.2的27%,KV Cache占用更是直接砍到10%。更激进的是V4-Flash版本——推理FLOPs降到10%,KV Cache仅剩7%。
简单翻译一下:以前跑100万Token上下文,你需要一台装满显存的昂贵机器慢慢算。现在用V4,同样的任务,算力省掉九成,显存放飞。
这不是什么魔法,也不是“算法突破了Transformer的平方复杂度”。V4团队做了一件非常直接、甚至有点暴力的事:
既然显存放不下那么多Key-Value对,那就别存那么多了。
接下来我会把这套方案的技术逻辑、具体做法和它必然要付出的代价,一层层拆开说清楚。
一、为什么以前的模型搞不定100万Token?先搞清楚KV Cache这个罪魁祸首
Transformer做生成任务时,每预测一个新的Token,都要跟之前所有Token的Key和Value做注意力计算。为了避免每次都重算,这些Key和Value会被缓存起来——这就是KV Cache。
问题出在,这个Cache的大小跟上下文长度线性增长。
以DeepSeek-V3.2为例,一个BF16精度、GQA8(8组查询头)、头维度128的标准配置,100万Token的KV Cache大约要吃掉几百GB的显存。这还没算模型权重本身。更致命的是,每次推理都要对这些KV做全量注意力计算,FLOPs随序列长度平方级增长。
这就是过去即使最顶尖的闭源模型,也不敢轻易把上下文窗口开到100万的原因——不是架构不支持,是算力和显存根本撑不住。
V4解决这个问题的思路,不绕弯子:直接在KV Cache上做有损压缩。
二、CSA:先捏成块,再挑着看
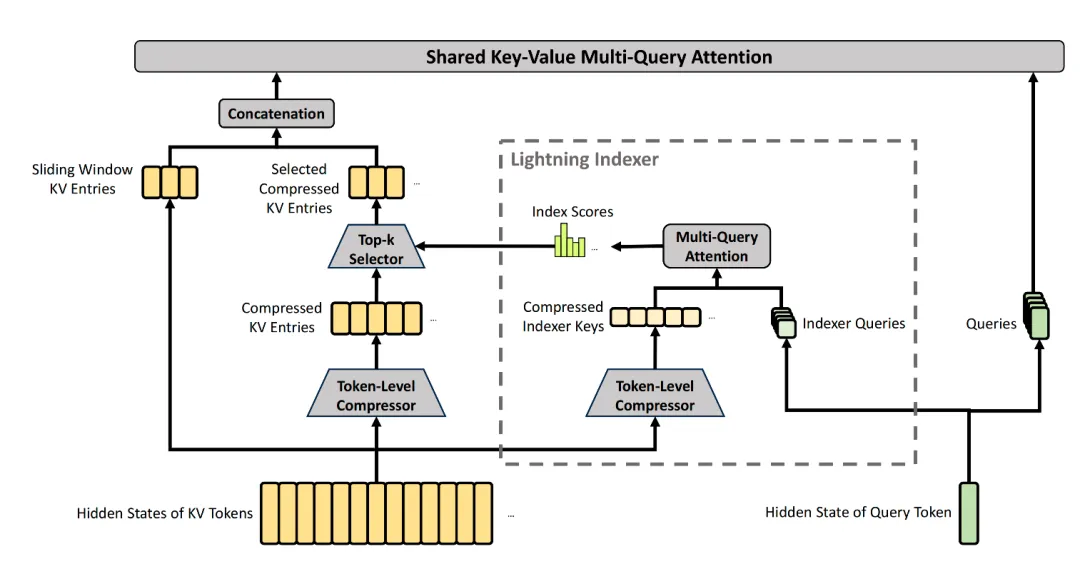
V4在大多数中间层用的是CSA,全称Compressed Sparse Attention(压缩稀疏注意力)。它由两步组成:压缩,然后稀疏筛选。
第一步:把KV条目捏成压缩块
CSA拿到原始输入的Hidden State后,先算出两组KV条目(和)以及对应的压缩权重(和)。然后,每个连续Token的KV条目,通过一个带可学习位置偏置的Softmax加权求和,捏成一个压缩后的KV条目。
在V4-Pro里,。也就是说,每4个Token才存1条KV。显存直接缩到原来的四分之一。
这里有个细节值得注意:CSA的压缩是有重叠的。计算第个压缩块时,它会同时用到中第到的元素,以及中第到的元素。也就是说,相邻两个压缩块之间,在上有半个窗口的交叉。这个设计是为了防止压缩边界处出现信息断裂。
第二步:用“闪电索引器”做粗筛,只挑最相关的
压缩之后,KV条目的数量降为原来的四分之一,但依然会随序列线性增长。如果全量做注意力,在百万Token下仍然扛不住。
所以CSA引入了第二步:稀疏筛选。
V4在CSA层里额外设了一个轻量级的“闪电索引器”。它不存完整的注意力Key,而是用更低维的压缩Key(头维度只有128,远小于主注意力的512)和更低精度(FP4)来做预筛选。
对于当前查询Token,索引器会快速扫一遍所有压缩KV块,计算相关性得分,然后用Top-k选择器只保留得分最高的那些块,送入后续的核心注意力计算。
k是多少?在V4-Pro里,k=1024。
也就是说,不管你上下文有多长,被压缩成多少块,最终每个查询Token真正做核心注意力的,最多只有1024个块。
这步筛选的计算量本身极低。索引器的Query是降维的(通过一个下投影矩阵映射到1024维,再上投影到64个索引头的128维空间),且计算时全程使用FP4精度,对整体FLOPs的贡献几乎可以忽略。
CSA到此完成了一个巧妙的组合拳:先压缩四倍,再只选1024块做精算。传统的平方级注意力,在这里被硬生生压到了一个可控的常数级。
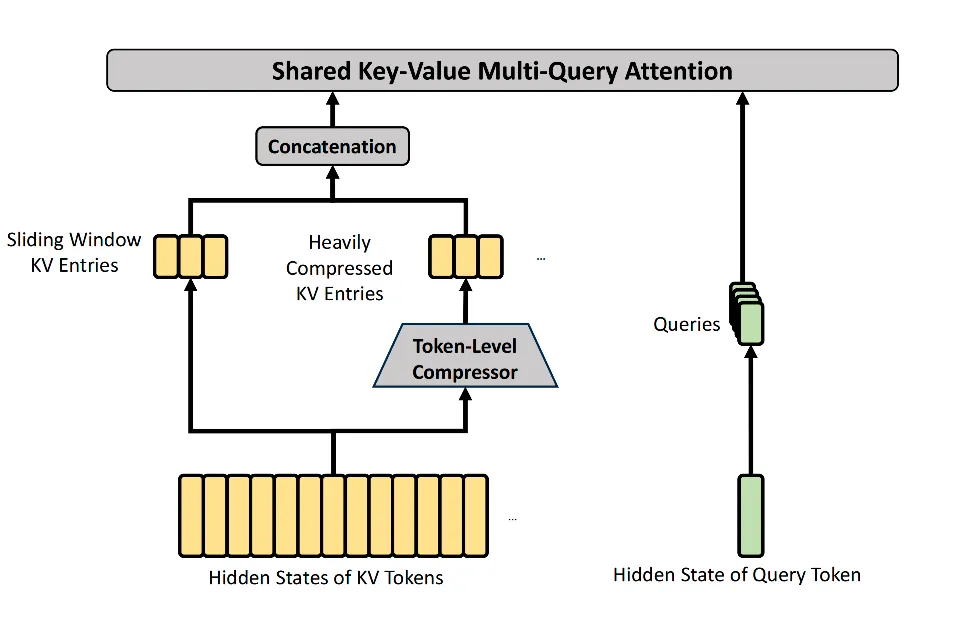
三、HCA:更暴力的压缩,但放弃稀疏
HCA(Heavily Compressed Attention)比CSA更极端。它的设计逻辑很简单:
如果CSA是每个Token压成一个,那HCA就把压缩比拉到极致——V4里的。
128个Token只存一个KV条目。这意味着,在HCA层里,100万Token的上下文,经过压缩后只剩不到八千个KV条目。全量做注意力也没压力,不需要再引入稀疏筛选那一步。
所以HCA的结构比CSA简单:输入做一次KV映射和权重计算,每128个Token软合并为一个压缩条目,所有查询Token都对这个全量的压缩KV做MQA(Multi-Query Attention)。
但它之所以能这么干,是因为它舍弃了细粒度的局部信息。128个Token浓缩成一个,里面必然丢失大量细节。这也是为什么V4不会在所有层都使用HCA——它只被放在特定位置,和CSA交替出现,各自负责不同粒度的信息捕捉。
四、那近期的细节怎么办?——滑动窗口这个“补丁”
CSA和HCA解决的是长程依赖问题,但它们有一个共同缺陷:压缩块内的Token之间,互相看不到。
比如,你在写代码的第99行时,第98行的信息对你极其重要。但在CSA层里,这两行很可能被捏到了同一个压缩块里。查询Token只能看到它所在块之前的压缩块,看不到同块内的兄弟。
V4的解法是直接加补丁:在每个CSA和HCA层上,多开一个独立的滑动窗口分支,保留最近个Token的原生(未压缩)KV条目。
这样,模型在查询时,既能看到被压缩的全局历史,也能看到窗口内精确的近期上下文。两个来源的KV在核心注意力里同时参与计算。
这个滑动窗口不参与压缩,所以它占用的KV Cache是独立的。但好在128个Token的量级很小(和百万级上下文相比几乎可忽略),对整体效率影响有限。
五、代价是什么?——把V4的报告数据和盘托出
上面这套方案看着漂亮,但“有损压缩”四个字本身就意味着代价。DeepSeek在报告里也没有回避这一点。
在MRCR(Multi-Round Coreference Resolution,一种严格的“大海捞针”式长文本检索任务)的评测中,V4系列的表现在128K以内极其稳定;但超过128K后,准确率开始出现肉眼可见的衰减。
对比Claude Opus 4.6,V4-Pro在MRCR 1M上确实落后。
这很好理解:一旦压缩比上来,那些被合并、被丢弃的KV条目中,总有一些细节是后续任务恰好需要的。稀疏选择那一步,Top-1024再聪明,也无法保证永远不会漏掉关键信息。
但有意思的是,在另一个长文本评测CorpusQA上,V4-Pro反而超过了Gemini 3.1 Pro。这说明,压缩带来的精度损失,对不同任务的影响是不同的。对于需要精确匹配、逐字比对的任务,压缩是隐患;但对于需要理解中心思想、提取核心逻辑的任务,压缩甚至可能起到去噪的作用。
六、这个公式,才是V4真正的设计灵魂
报告里有一个很多人可能会跳过的部分,但它是理解整套架构的钥匙。
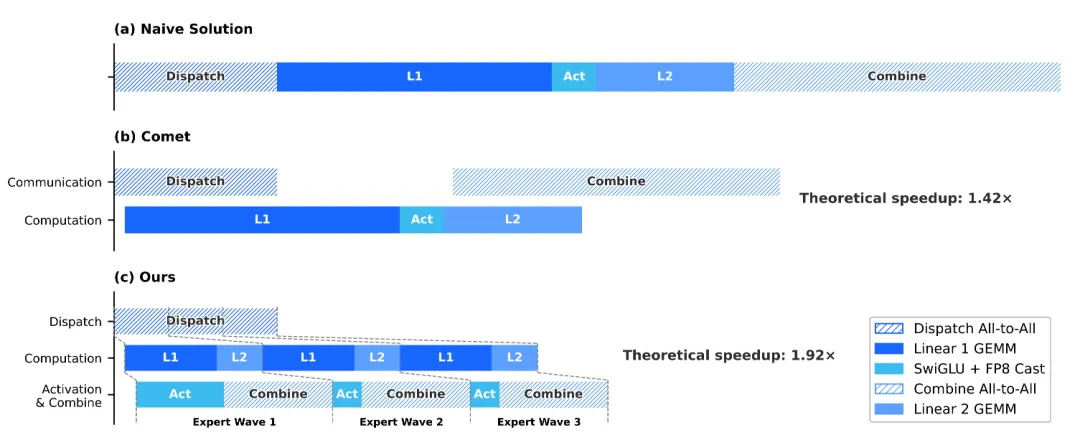
在3.1节讲专家并行的时候,V4团队列了一个公式:
解释一下:是GPU的峰值算力(FLOPs),是GPU之间的互联带宽(GB/s)。这个不等式意味着,只要你的带宽能满足这个关系,通信延迟就可以被计算完全掩盖。
6144这个数字是怎么来的?对于V4-Pro,每个Token-专家对的计算量是6hd次FLOPs,而通信量只有3h字节。,,乘出来就是6144。
翻译成人话:每GB/s的互联带宽,可以覆盖6.1 TFLOP/s的算力。
这个公式直接把V4的设计哲学暴露了——它根本不是为无限带宽的豪华集群设计的,而是为带宽受限、但算力充沛的硬件量身定制的。
传统观念里,MoE模型害怕低带宽,因为All-to-All通信是性能瓶颈。但V4通过这个精确的配比计算,告诉你:通信不是瓶颈,只要你的硬件配比达到这个阈值,再多带宽就是浪费。
这和它做KV压缩的逻辑完全一脉相承:不要在可以被容忍的损耗上投入资源,把省下来的每一分算力都砸到计算本身上去。
七、总结:2026年,大模型正在分叉
把V4这套技术方案放在2026年的大背景下看,你会发现一条清晰的路线分叉:
一条是“无损全家桶”路线。代表是Claude Opus 4.6和Gemini 3.1 Pro。它们追求在每项基准上的全面领先,包括极端长文本的精确检索。代价是单次推理成本高企,大规模Agent部署时成本不可控。
另一条是DeepSeek-V4的“工程效率”路线。它承认物理极限,承认有损压缩的副作用,然后通过精密的系统设计(CSA、HCA、滑动窗口、FP4量化、通信-计算重叠),把百万Token推理变成了一个在成本上真正可落地的方案。
这两种路线没有绝对的对错。如果你的场景是单次、高价值、零容错的深度分析(比如合同审查、安全审计),你仍然应该用前者。但如果你的场景是成百上千个Agent在后台同时跑代码理解、日志分析、长文档摘要——那你需要的是V4这样的效率怪物。
DeepSeek-V4的野心不在于跑分,在于把百万Token从实验室里的昂贵玩具,变成生产者手里真正能用的工具。这个定位,比任何单项指标的领先,都更值得被认真对待。
🔗 参考文献:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,