
一、蒙特卡洛(MC)方法
蒙特卡洛方法是一种无模型的强化学习算法,通过采样完整的轨迹来估计状态价值函数。
核心更新公式
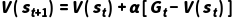
•符号说明:
○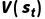 :状态
:状态 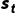 的当前价值估计
的当前价值估计
○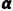 :学习率(步长),控制更新幅度
:学习率(步长),控制更新幅度
○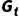 :从状态
:从状态 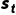 开始的折扣回报,定义为:
开始的折扣回报,定义为:
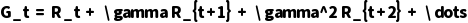
其中 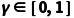 是折扣因子,
是折扣因子,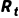 是时刻
是时刻 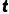 获得的即时奖励。
获得的即时奖励。
核心思想
•直接使用完整轨迹的实际回报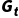 作为价值函数的目标值。
作为价值函数的目标值。
•无需依赖模型,仅通过与环境交互采样得到的经验数据进行学习。
•优点:无偏估计(期望等于真实价值);缺点:方差大,需要完整轨迹才能更新。
二、一步时间差分(TD(0))方法
一步时间差分是蒙特卡洛与动态规划的结合,通过**自举(Bootstrapping)**思想,利用下一状态的价值估计来更新当前状态价值。
核心推导与公式
用期望回报 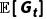 替换 MC 中的实际回报
替换 MC 中的实际回报 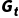 ,并递推一步:
,并递推一步:
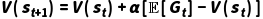
进一步展开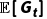 :
:
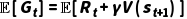
因此得到 TD(0) 更新公式:
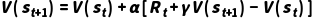
核心思想
•自举:用后续状态的价值估计 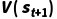 来近似未来回报,无需等待轨迹结束。
来近似未来回报,无需等待轨迹结束。
•偏差与方差:相比 MC,方差更小(仅依赖一步奖励),但存在偏差(依赖价值估计)。
•适用于非完整轨迹的在线学习,效率更高。
三、n 步时间差分(TD(n))方法
n 步时间差分是 TD(0) 的扩展,平衡了 MC(完整轨迹)与 TD(0)(单步)的偏差-方差权衡。
核心更新公式
用期望回报 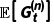 替换
替换 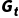 ,并递推
,并递推 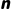 步:
步:
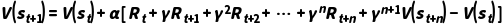
•n 步回报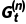 :
:
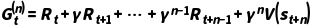
•当 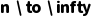 时,TD(n) 退化为 MC 方法;当
时,TD(n) 退化为 MC 方法;当 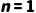 时,退化为 TD(0) 方法。
时,退化为 TD(0) 方法。
核心思想
•通过调整 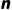 的大小,在偏差(依赖
的大小,在偏差(依赖 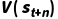 )和方差(依赖
)和方差(依赖 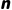 步奖励)之间取得平衡。
步奖励)之间取得平衡。
•结合了 MC 的低偏差和 TD 的高效性,是更通用的时间差分框架。
四、重要性采样(Importance Sampling)
重要性采样是**离策略(Off-policy)**学习的核心技术,用于在行为策略 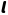 采集的数据上,估计目标策略
采集的数据上,估计目标策略 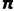 的期望。
的期望。
核心公式
设行为策略为 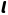 (用于与环境交互),目标策略为
(用于与环境交互),目标策略为 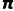 (待优化),则目标策略下函数
(待优化),则目标策略下函数 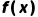 的期望可表示为:
的期望可表示为:
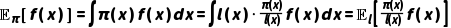
•重要性权重: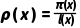 ,用于修正行为策略与目标策略的分布差异。
,用于修正行为策略与目标策略的分布差异。
•直观理解:通过对行为策略样本加权,使其等价于目标策略下的样本期望。
核心思想
•允许复用旧数据:无需每次都用目标策略与环境交互,可利用历史数据优化新策略。
•关键挑战:重要性权重可能导致方差爆炸,需结合截断、加权平均等技巧稳定训练。
•应用场景:离策略 Q-learning、Sarsa(λ)、策略梯度等算法。
五、方法对比总结
方法 | 核心思想 | 优点 | 缺点 |
MC | 完整轨迹回报估计 | 无偏估计 | 方差大,需完整轨迹 |
TD(0) | 单步自举,在线更新 | 方差小,效率高 | 存在偏差(依赖价值估计) |
TD(n) | n 步自举,平衡偏差与方差 | 灵活可调,兼顾效率与精度 | 超参数 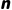 需调优 需调优 |
重要性采样 | 离策略数据复用,加权修正分布 | 支持离策略学习,数据高效 | 方差易失控,需稳定技巧 |
欢迎扫码关注

欢迎参观联合实验室


