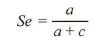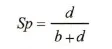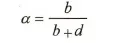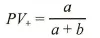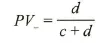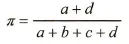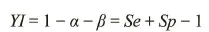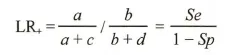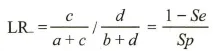| 昨天跟同事讨论了“驼背”的问题,她的说法很有趣。因为肌肉不舒服会“讲出来”,但是骨头不会,所以人们总是倾向于做一些肌肉“喜欢”的姿势。久而久之,肌肉被溺爱,越来越担不住劲儿;骨头承担了太多,失去了自己原本的挺拔姿态。故而……… |
mistake diagnostic rate, α 误诊率,假阳性率omission diagnostic rate, β 漏诊率,假阴性率positive predictive value, PV+ 阳性预测值negative predictive value, PV_ 阴性预测值Youden Index, YI Youden指数,约登指数,正确指数positive likelihood ratio, LR+ 阳性似然比negative likelihood ratio, LR_ 阴性似然比receiver operating characteristic, ROC ROC曲线area under curve, AUC 曲线下面积
关键内容摘要
诊断试验 评价某种疾病诊断方法的临床试验;评价该诊断是否足够准确
诊断试验的用途 ①诊断疾病;②筛选无症状患者;③判断疾病的严重程度;④对疾病临床过程预测和预后;⑤评估患者对治疗的反应;⑥判断治疗的疗效等。
| 诊断类研究:指研究不同诊断方法对于疾病诊断的价值。其研究目的在于:评估新的诊断模型、诊断靶标、诊断方法对于疾病诊断的准确性。 |
金标准 即标准诊断,指临床医学界公认的当前最客观、最真实、最可靠的疾病诊断标准。
【“金标准”这个词,笔者刚接触时总是觉得这个词怪怪的。
不同疾病的诊断标准不同,笔者随便找了一个诊疗指南,检索“金标准”,结果如下图所示。】
诊断常用的金标准
病理学诊断 尸体解剖 外科手术或诊断性操作 特殊影像学诊断 长期随访肯定的诊断 因缺乏特异性诊断方法而采用的权威机构颁布的综合诊断标准等
金标准的应用目的 准确区分“有病”“无病”
样本量估计
诊断试验样本量大小与以下三个参数有关: ①试验的灵敏度或试验的特异度( p ) ;②试验的检验水准α ; ③容许误差 δ, 一般取值为0.05 ~ 0.10 。
样本量计算公式: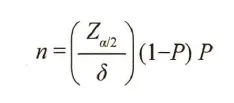
Zα/2为双侧概率为α或单侧概率为α/2的标准正态分布界值(Z0.05/2≈1.96)
举例如下:
研究对象分类
备注:原书中关于此处的论述与下文不一致,此处笔者进行了更改。
诊断试验四格表
常用评价指标
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | LR+>1说明诊断试验方法有效,越大诊断价值越高;LR+<越小,诊断价值越高 |
| 公式:除了似然比,笔者都算过了,感兴趣的也来算一下 |
ROC曲线
是什么?
以真假阳性率为横纵坐标绘制的曲线
返回上面表格看一下真假阳性率分别是什么来着,什么?不用看?那我换种说法
以灵敏度和1-特异度为横纵坐标
以sensitivity和False-Positive为横纵坐标
……还能明白吗
什么用?
评价二值分类器的优劣,即:评估模型预测的准确度
【也就是评估诊断方法诊断患者“有病”与“无病”的准确性】
怎么下结论?
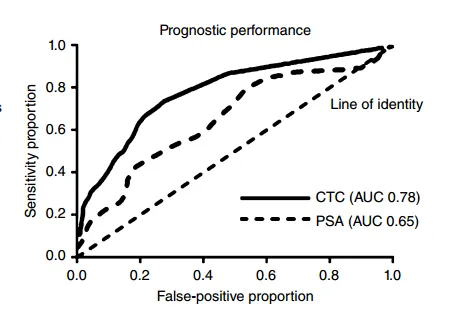
当然是越对越好,越靠近真阳性越好呗,显而易见了
例图摘自A concise guide to clinical trial 临床试验简明指南(好书相伴乃人生一大幸事!),评价CTC(基线时的循环肿瘤细胞)与PSA(前列腺特异性抗原)对于评价前列腺患者预后的有效性,换句话说,就是评价二者哪个更适合作为前列腺癌的预后标志物。
显而易见,CTC要更好些。
但是很显然,“显而易见”这几个字并不好使,终归要落到数据上面。请看一段我两年前划线的句子。我们需要一个指标来量化评价,这个指标就是ROC曲线下面积AUC。
0.5 ≤AUC ≤ l 。曲线下面积越接近于1 ,即曲线越靠近左上角,诊断试
验诊断得越可靠。
当AUC = 0.5 时,说明诊断结果与患者实际是否患病完全独立,该诊断试验无任何临床实际意义。
0.5 < AUC ≤ 0.7 诊断价值较低
0.7 < AUC ≤ 0.9 诊断价值中等
AUC>0.9 诊断价值较高
| 是我轻敌了。当时看完生存曲线就感觉感觉这书没什么好看的了,再一看这个章节就了了数页,简直小菜一碟(不是)当我开始看,就发现,怎么还挺不好理解的……于是再查资料学习,学了两三个晚上……自信光荣,轻敌可耻~ |
读书,为什么看不懂也要继续看? 或许你也曾在时光邮局给一年、两年后的自己写信吗? 其实当你再次翻开这本书,每一个划线、每一个批注,都留给未来自己的一封信。 想不想,对现在狼狈但努力的自己再次怦然心动? |