学习笔记 | 矩阵画像+Louvain社会发现算法
- 2026-05-08 18:28:24
为什么会写这篇?上周开组会的时候,梁老师建议我们低年级同学在上升期间多掌握一点扎实的技术,并吃透原理!张老师也跟我发消息建议我去多学习关于专利挖掘和分析的一些原理与方法。
正好,昨天在《情报学报》上看到一篇关于关键核心技术识别的文章,它的识别方法很新颖,是我之前没见过的组合——矩阵画像(MP)+ Louvain社区发现算法。
梁老师跟我们讲要多读文献、多输出,一方面有利于让自己吃透知识点,另一方面也能锻炼分享交流能力。所以,我把这篇文献的学习笔记和思考整理出来,作为一次学习打卡。
文中多为个人理解与学习,因学识有限,难免有疏漏,恳请各位前辈不吝指正。
基于矩阵画像和Louvain社区发现算法的关键核心技术识别研究
期刊:情报学报
发表时间:2025 年 7 月
卷期:第 44 卷 第 7 期
DOI:10.3772/j.issn.1000-0135.2025.07.009
这篇文章在干嘛?
这类“关键核心技术识别”的研究,绝大多数都遵循大体思路:
提出一个新的识别方法(一套工作流)
选一个热门领域(比如智能制造、新能源汽车、量子科技)
用该领域专利数据做实证分析,验证方法的有效性。
这篇文章也不例外,它提出了一种新的关键额核心技术识别的方法:
热点定位:用 IPC(国际专利分类)小类权重 + 词频分析,圈定目标领域的热点技术主题。
关联构建:拿高频 IPC 小类的时间序列数据,用矩阵画像(MP)算法计算技术间的“相似度”,构建出一个技术关联网络。
核心识别:在这个网络上,用Louvain 社区发现算法加上社会网络分析,把“初始的关键核心技术主题”给挖出来。
Key Point: 它和其他文章最大的区别在于,关注专利的时间维度。不再是静态地看专利数量,而是看技术主题随着时间演变的轨迹和模式。这个创新点,就引出了时间序列数据挖掘里的一个利器——矩阵画像(matrix profile)。
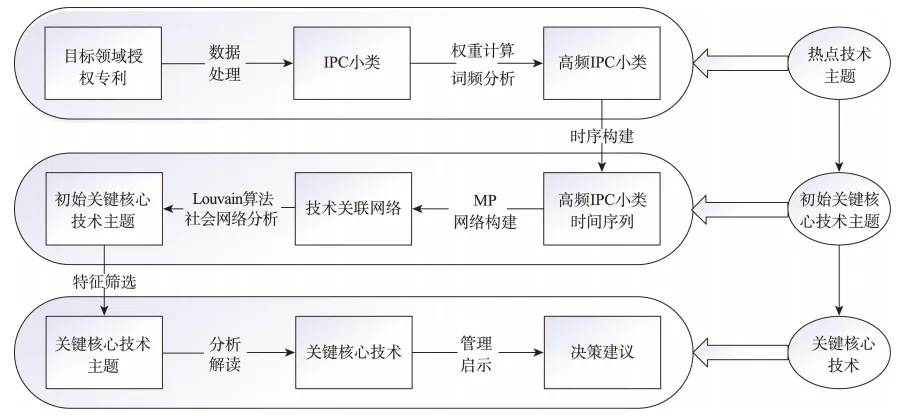
图1 文章的研究思路
矩阵画像是个什么工具???
矩阵画像(matrix profile)是时间序列数据挖掘中非常强大的一种工具,原理其实很简单。其解决的核心问题就是:在一个很长的时间序列中,找出所有“相似的子序列”和“不寻常的子序列”。
子序列,顾名思义,按照给定的窗口长度将完整的时间序列分为一个又一个的子序列。
Matrix Profile 由两部分组成:
1.距离曲线(Matrix Profile)
对于每一个子序列,找出在整条时间序列中(除了自身附近),与它最相似的其他子序列,并计算它们之间的欧几里得距离(就是两点之间的直线距离),从而可以表示其相似度,距离越短,相似度越高,反之,距离越长,相似度越低。
Matrix Profile就是所有这些最小距离组成的一条新序列,长度等于子序列的个数。
2.索引曲线(Matrix Profile Index)
同时记录下:与每个子序列最相似的那个子序列,在原始序列中的位置。
也就是说,Matrix Profile 把“每个局部片段与全局最相似片段之间的距离”按顺序排成一条新曲线,让你能直观看到时间序列中哪些部分是重复的、哪些是异常的、结构如何变化。
那么,矩阵画像有什么作用???
模式挖掘(自动找重复出现的模式)
异常检测(自动找最独特的地方)
状态分割(自动找变化点)
周期分析(看重复模式的规律)
Louvain社区发现算法是个什么算法???
Louvain社区发现算法是社会网络分析中的一种方法,原理比较复杂,就不展开讲了。
这个算法由比利时鲁汶大学(Université catholique de Louvain)的研究团队在2008年提出,因此以大学所在地“Louvain”(鲁汶/卢万)命名。它的全称是Louvain Method for Community Detection。
原始论文:《Fast unfolding of communities in large networks》
一句话总结就是:Louvain算法就是通过反复进行“节点移动优化”和“社区聚合”这两个步骤,来高效地让网络的模块度达到最大,从而发现清晰的社区结构。
方法有效性验证
上周组会的时候,张老师叮嘱我多注意一些方法可靠性验证的,这篇文章方法的可靠性验证也是有点意思,作者也是下了很大功夫,利用不同专利的数据用几种方法全部跑了一遍。
表1 此文的方法代号
表2 不同专利类型下不同方法的识别结果
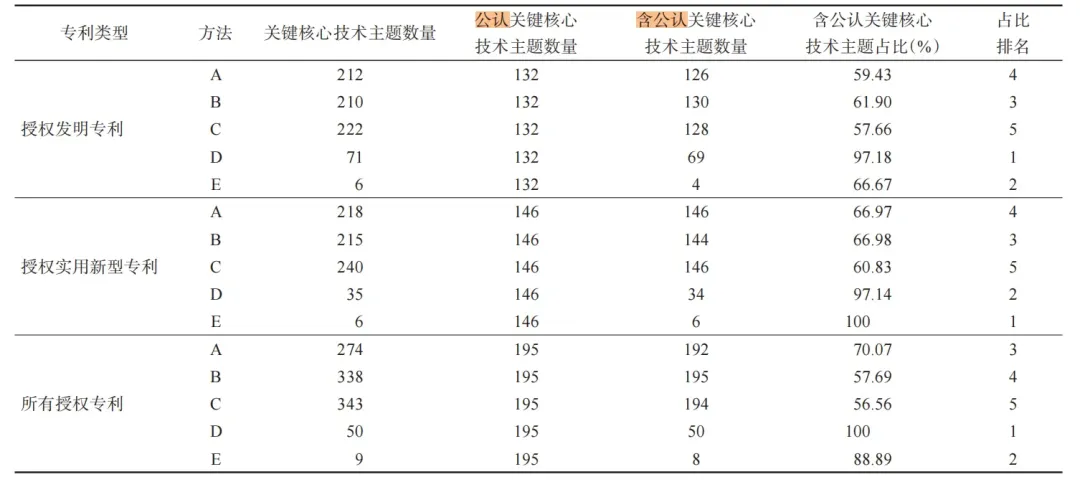
这篇文章的方法验证思路大致:首先,找出方法 A、 B、C 和 D 中任意三种方法的关键核心技术主题结果的交集,即A∩B∩C、A∩B∩D、A∩C∩D、B∩C∩D; 其次,对这些交集结果进行并集计算,得到该领域公认的关键核心技术主题;最后,计算各方法结果中含公认关键核心技术主题占比。
我一开始心想,把这五种方法所识别的关键核心技术出现的数量做一个频次排名,这样不就好了,后来仔细了解到这个“交集并集”验证方法,确实是我肤浅了~
为什么用“交集并集”作为基准?
1.避免过度严苛的共识标准
如果直接取四种方法的全集交集 A∩B∩C∩D,往往结果过小甚至为空,因为四种方法完全一致的要求太高。而采用任意三种的交集再并集,既保留了多数方法共同支持的主题,又允许某一种方法存在一定偏离,体现了稳健共识而非绝对共识。
2. 解决领域缺乏标准的问题
在核心专利识别领域,最大的难题是:没有一个公认的、绝对正确的“核心专利清单”来做对比。包括关键核心技术的定义,也是在学界没有一个统一的标准。
这种方法本质上是一种数学化的“专家共识”模拟。它的逻辑是:如果一种技术主题能被三种不同路径的方法同时识别出来,那它就极大概率是关键核心技术,其方法较为客观。
3. “交叉验证”思想的体现
这种设计也体现了学术研究中经典的交叉验证思想。在缺乏外部验证标准时,我们利用多种方法之间的内部一致性来构建一个可信的基准。
简单来说,使用“交集” 操作保证了精确性,使用“并集” 操作保证了覆盖度。

