很多 Web 安全问题并不“玄学”:你在浏览器里点一次登录按钮,本质上就是发出了一条(或多条)HTTP 请求;服务端回你一个响应;浏览器再根据响应渲染页面、设置 Cookie、跳转地址。漏洞往往就藏在这些细节里——参数放在哪、头字段怎么写、状态码为什么变成 302/403/500。
这篇文章从安全与排障的角度,把 HTTP 的来龙去脉、报文结构、常见字段与抓包方法串起来,读完你至少能做到两件事:
- 1. 看到一段原始 HTTP 报文不慌,能快速定位关键点
- 2. 做 Web 渗透/排障时知道该抓什么、该看什么、该怀疑什么
1)HTTP 之前,网络世界已经很热闹了
- • 1946 年,第一台通用电子计算机 ENIAC 诞生
- • 1969 年,美国出现了早期计算机网络 ARPANET(阿帕网),最初服务于科研与军事通信
- • 在 Web(HTTP)出现之前,网络上已经有不少“能用”的协议,例如:
到 1991 年,Tim Berners‑Lee(蒂姆·伯纳斯‑李)提出 HTTP,并同时给出 URL、HTML、浏览器与 Web 服务器这套组合拳,Web 才真正把“信息链接”这件事做成了全球基础设施。
2)HTTP 到底解决了什么:让资源“可链接、可定位、可传输”
HTTP 的全称是 Hypertext Transfer Protocol,直译是“超文本传输协议”。这里的“超文本”关键在 超链接:一个页面可以指向另一个页面/图片/脚本/接口,让信息从孤立文件变成互相引用的网络。
从架构上看,HTTP 是典型的 客户端—服务器(Client/Server) 模式:
对安全人员来说,这意味着:每一个请求都是攻击面。你看到的一个页面,可能背后要发几十个请求(HTML、CSS、JS、图片、接口数据……),每个请求都可能出现参数注入、鉴权绕过、越权访问、信息泄露。
3)HTTP 报文长什么样:三段式结构 + “空行”是分界线
HTTP 无论请求还是响应,都可以理解为:
- • 头部和正文之间必须有一个 空行(也就是 CRLF 分隔)
3.1 请求报文(Request)示例
POST/loginHTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Content-Type: application/x-www-form-urlencoded
Cookie: SESSIONID=abc123
Content-Length: 27
username=alice&pwd=123
你做安全测试时,一般先盯住这几个点:
- • 方法 + 路径:是不是该用 GET 却用 POST?路径是否可枚举?
- • Host:HTTP/1.1 强制要求,缺失可能导致服务端/代理行为异常
- • Content-Type:决定服务端如何解析 Body(注入与绕过常发生在这里)
- • Cookie:会话身份核心,XSS/会话固定/越权都围着它转
- • 空行:很多自研网关/不严谨解析器会在“空行/换行”上出兼容性与安全问题
3.2 响应报文(Response)示例
HTTP/1.1200 OK
Server: nginx/1.18.0
Content-Type: application/json
Set-Cookie: SESSIONID=def456; HttpOnly; Secure
Content-Length: 38
{"user":"alice","role":"user"}
安全角度重点关注:
- • Set-Cookie:是否带
HttpOnly/Secure/SameSite(直接影响抗 XSS/CSRF 能力) - • Content-Type:是否正确(错误类型可能触发浏览器“内容嗅探”风险)
4)方法(Method):GET/POST 常用,但别忽视 PUT/DELETE
HTTP 方法很多,日常最常见的是:
- • GET:获取资源(参数通常在 URL Query)
还有一些你在 API/网关里经常能见到:
- • HEAD:像 GET,但只要响应头(用于探测、缓存校验)
- • TRACE:链路诊断(历史上曾被滥用,很多环境会禁用)
现实开发里,“用 POST 干一切”的情况很常见;但在做安全测试时,看到 PUT/DELETE 反而要敏感:它们往往对应“改数据/删数据”的高危操作,鉴权一旦松动,后果比读接口严重得多。
5)状态码(Status Code):一眼判断“问题在谁家”
状态码不是背书用的,它是排障与研判的捷径。常用的记住几个就够了:
- • 200:成功(但也可能返回“业务失败”,要看响应体)
- • 302:重定向(常见于未登录跳转登录页;也可能藏开放重定向)
- • 403:禁止访问(鉴权/白名单/权限/目录权限)
- • 404:资源不存在(路径错、路由没配、文件被删、被 WAF 隐藏)
- • 500:服务端异常(代码错误、未捕获异常、依赖挂了)
一个实用经验:
- • 4xx 先查你的请求(URL、方法、参数、Cookie、权限、Referer/Origin)
- • 5xx 重点查服务端(日志、依赖、资源、异常堆栈、限流熔断)
6)头字段(Header):Web 漏洞的“主战场”
下面这些字段,在安全测试里出现频率极高:
6.1 Cookie:身份凭证,不要当普通参数看
- • 会话标识(Session)经常放在 Cookie
- • Cookie 未设置
HttpOnly 时尤其危险 - • Cookie 未设置
Secure 时,HTTP 明文环境可能被抓到
6.2 Referer / Origin:CSRF 防护常用,但也会泄露隐私
- • 很多站点用 Referer/Origin 做 CSRF 校验
- • Referer 可能携带敏感路径或参数(例如带 token 的链接)
- • 依赖 Referer 做安全判断不够稳(可能被某些环境裁剪、缺失)
6.3 User-Agent:爬虫/风控/反作弊常用,安全测试可被你“伪装”
- • 风控如果只靠 UA 判断“是不是浏览器”,强度很有限
6.4 Content-Type:文件上传与接口解析绕过的关键
- •
application/x-www-form-urlencoded
- • 上传绕过、解析差异(例如网关按 JSON 解析、后端按表单解析)经常在这里出坑
7)明文 HTTP 到 HTTPS:安全传输的分水岭
HTTP 默认是明文传输:账号、密码、Cookie、身份证号,只要链路上有人能抓包,就可能被看见。
HTTPS 本质是 HTTP + TLS(历史上也叫 SSL),把传输加密、身份认证、完整性校验都补齐。抓包时你仍能看到“访问了哪个域名、建立了连接”,但看不到具体内容(除非你在客户端安装了代理证书做中间人解密,或拿到服务端密钥/控制终端)。
8)怎么把 HTTP “看见”:浏览器 F12 与 Burp Suite
8.1 浏览器开发者工具(适合快速定位)
步骤很简单:
- 4. 点开某条请求,查看 Request/Response Headers、Query、Form Data、Response
适合做:
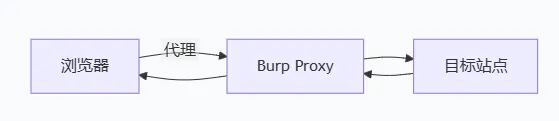
8.2 Burp Suite(适合安全测试与重放)
Burp 的价值在于:拦截、修改、重放。
简单流程可以理解为:
常用动作:
- • Proxy 开启拦截(Intercept On)
- • 把请求发到 Repeater 重放、逐字节改参数
- • 需要拦截响应时,手动开启 “Intercept Response”(不同版本菜单略有差异)
- • 测 HTTPS 时通常要在浏览器安装 Burp 的 CA 证书,否则会提示证书不受信任
安全提醒:在真实环境操作证书、代理、抓包要遵守授权范围与合规要求,别把测试习惯带进生产网。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
