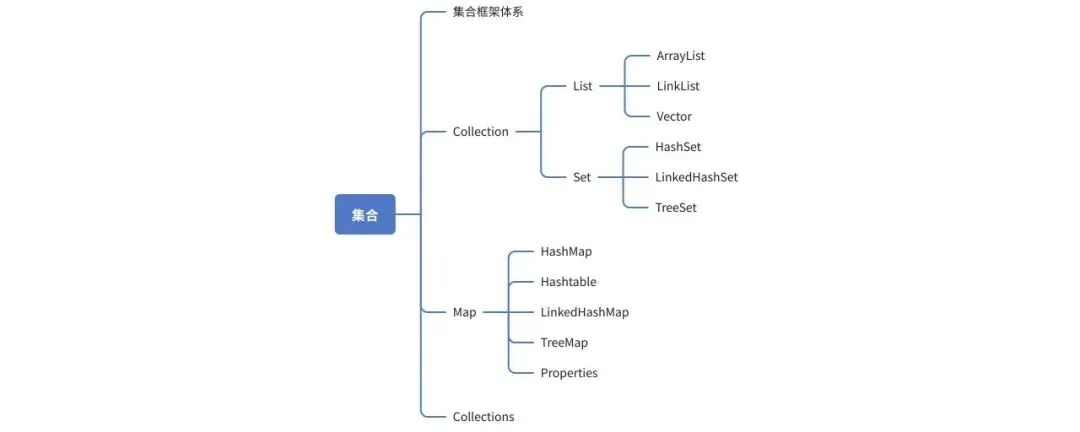
集合
思维导图
•数组(灵活性不足)
a.长度开始时必须指定,而且一旦指定,不能更改
b.保存的必须为同一类型的元素
c.使用数组进行增加元素的示意代码 - 比较麻烦写出 Person 数组扩容示意代码。(数组添加元素麻烦)
Java Person [] pers = new Person [1]; per [0]=new Person (); |
d.增加新的 Person 对象?
Java Person [] pers2 = new Person [pers.length+1]; // 新创建数组 for (){} // for循环拷贝 pers 数组的元素pers2 pers2 [pers2.length-1]=new Person ();// 添加新的对象 |
集合的引出
1.好处:可以动态的保存任意多个对象
2.提供简单造作对象的方法,如add,remove,set,,get等
3.使用集合增删改新元素的代码简介明了
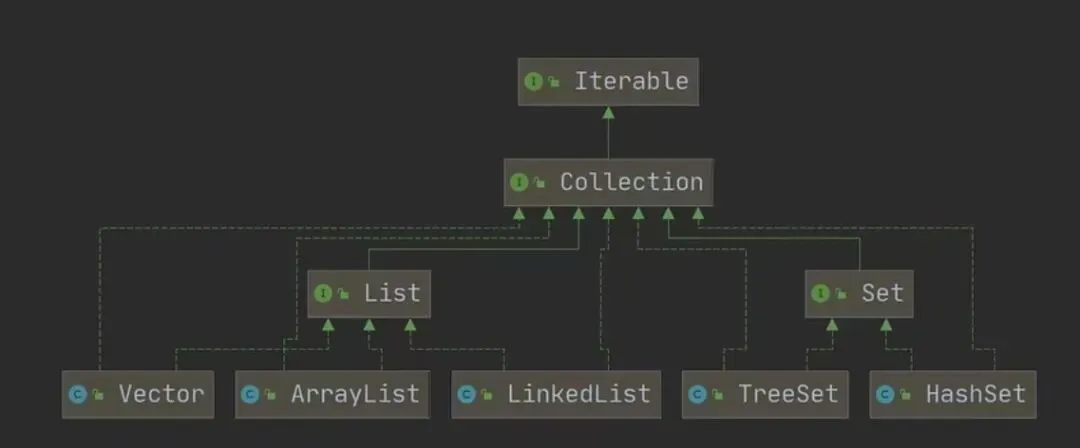
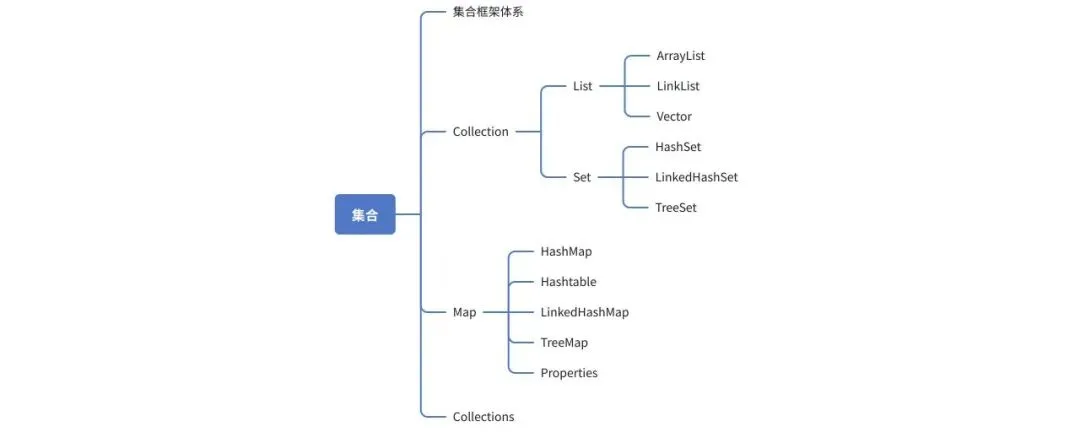
集合体系图(两种,单列(Collection)和双列(Map)集合)
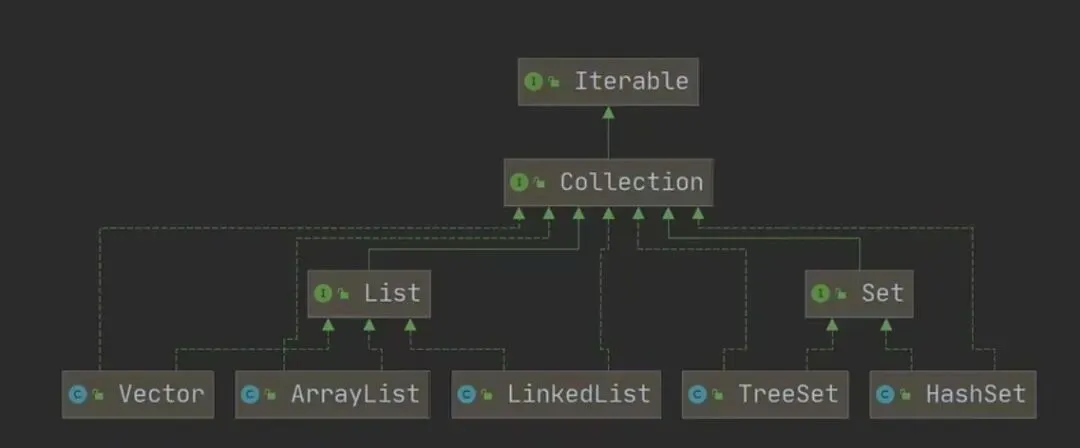
单列集合(Collection有两类:List和Set),存储单个数据元素
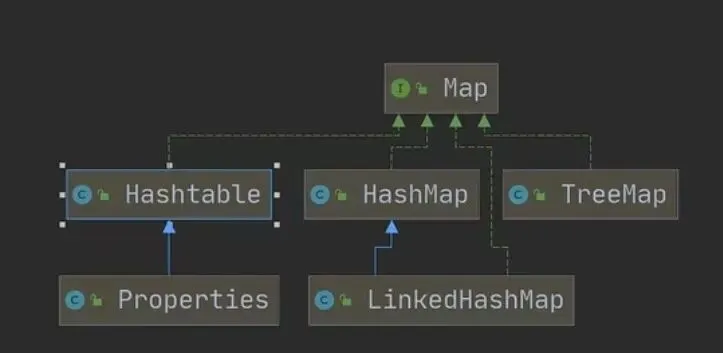
双列集合(又细分为三类),存储键值对元素
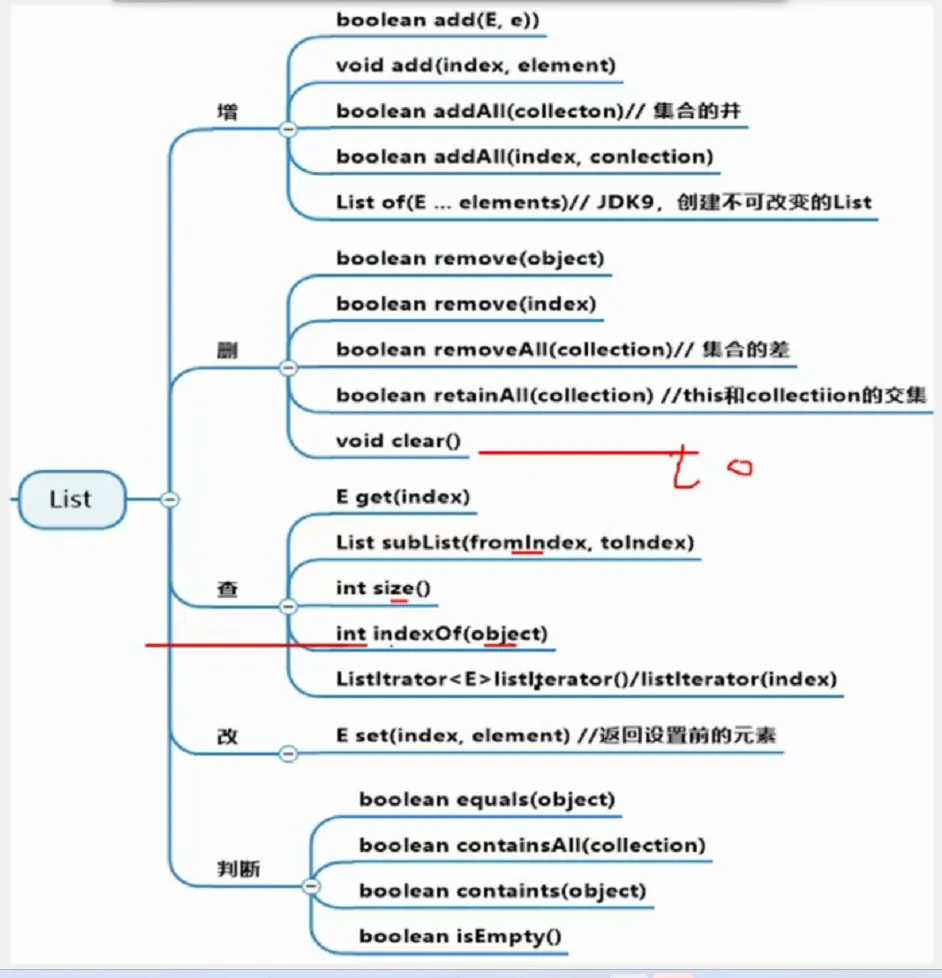
collection接口和常用方法
集合元素遍历

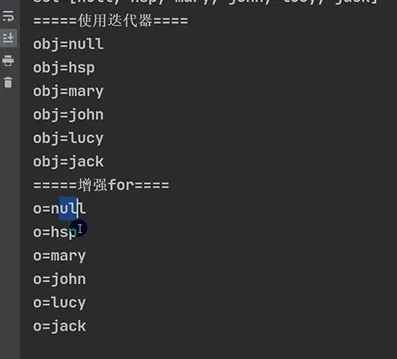
1.迭代器(Iterator)遍历
这是最通用的遍历方式,适用于所有实现了Iterable接口的集合(几乎所有集合都实现了),支持在遍历中安全删除元素。主要用于遍历collection集合中的元素
Java import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class Test{ public static void main(String[] args) { Collectionlist = new ArrayList<>(); list.add("A"); list.add("B"); list.add("C"); // 获取迭代器 Iteratoriterator = list.iterator(); //使用while遍历 while (iterator.hasNext()) {// 判断是否有下一个元素,iterator.next之前必须先进行//iterator.hashNext()检查;String element = iterator.next(); // 获取下一个元素 System.out.println(element); // 若需要删除元素,使用iterator.remove(),而非集合的remove() // if (element.equals("B")) iterator.remove(); } } } |
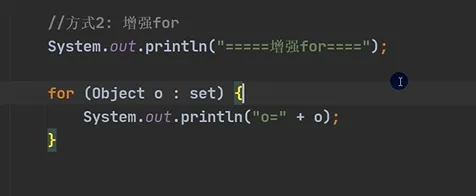
2.增强for循环遍历:
Java import java.util.List; import java.util.ArrayList; ... List list=new ArrayList for(Object obj:list){ sout(obj); } |
3.普通for循环遍历
Java for(int i=0;i <list.size();i++){ </list.size();i++){ sout("对象="+list.get(i));} |
快捷键
1.快速写出Iterator的while循环:itit+Enter键
Java while (iterator.hasNext()) { Object next =iterator.next(); } |
2.显示所有快捷键的快捷键:ctrl+j
以子类实现ArrayList演示。
List接口介绍
单列集合(Collection有两类:List和Set),存储单个数据元素
List接口是Collection接口的子接口
1.元素有序且可重复:元素的添加顺序与取出顺序一致,允许存入重复元素。
2.支持索引访问:每个元素都对应一个整数型顺序索引,可通过索引直接存取元素。
3.常用的有:Vector, ArrayList, LinkedList等
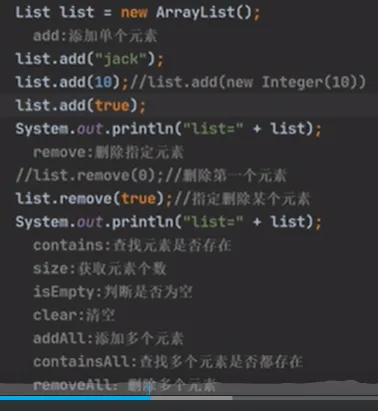
List常用方法(以ArrayList为例)
1.添加元素
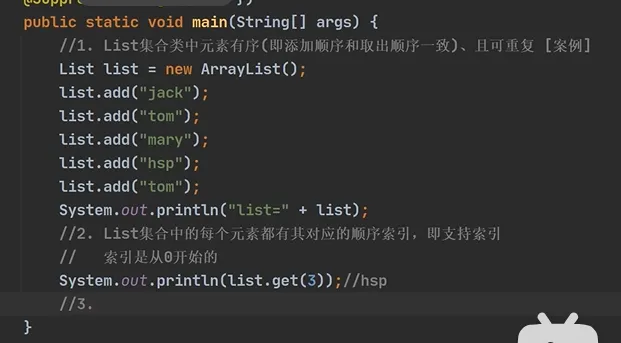
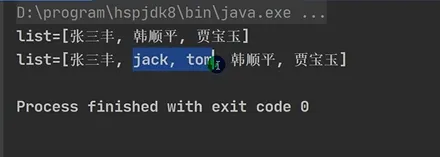
Java ... import java.util.Arrays; import java.util.List; ... List list=new ArrayList(); list.add("张三丰"); list.add("贾宝玉"); list.add(1,"韩顺平");//在1的位置加入字符串sout("list="+list);List list2=new ArrayList(); list2.add("Jack"); list.add("Tom"); list.addAll(1,list2);//在list的1的位置插入list的元素,其他字符串后移动sout("list="+list); // 方式3.2:ArrayList 包装(可修改的 List,推荐) ListmutableList = new ArrayList<>(Arrays.asList("北京", "上海", "广州", "深圳")); mutableList.add("杭州"); // 可以正常添加 // 输出:[北京, 上海, 广州, 深圳, 杭州] System.out.println(mutableList); |
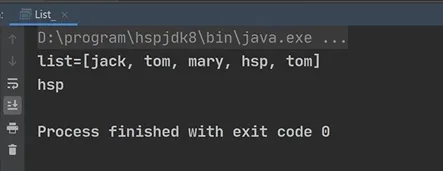
2.找索引
返回obj对象首次出现的位置
Java sout(list.indexOf("Tom"));//返回2 |
返回obj对象在当前集合中末次出现的位置
Java list.add("韩顺平"); sout(list.lastIndexOf("韩顺平");//返回5 |
3.remove删除在指定下标位置的元素,并返回此元素
Java list.remove(0); sout(list);//[jack,tom,韩顺平,贾宝玉,韩顺平] |
4.set设置指定位置元素,相当于替换
Java list.set(1,"玛丽");、、[jack,玛丽,韩顺平,贾宝玉,韩顺平] |
5.list返回指定区间(左闭右开)的集合元素
Java List returnList=list.subList(0,2);sout(returnList); //[jack,玛丽] |
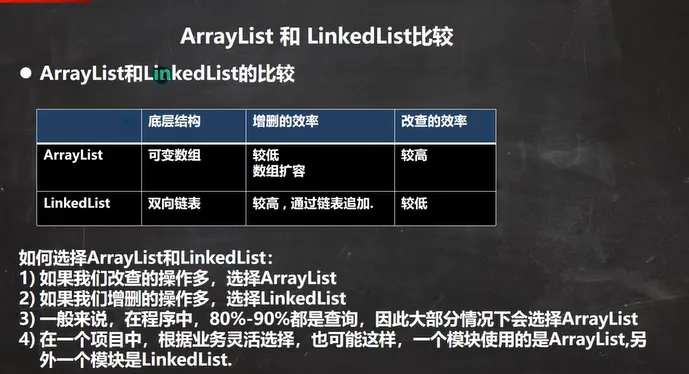
ArrayList底层结构和源码分析
ArrayList的注意事项
1.ArrayList可以存放一个甚至多个null对象
Java ArrayList arrayList=new ArrayList(); arrayList.add(null); arrayList("jack"); arrayList(null);//[null,jack,null] |
2.ArrayList是线程不安全的,底层代码没有synchronized修饰,但是执行效率高
3.ArrayList是由数组实现数据存储的
4.ArrayList基本等同于Vector, 除了ArrayList是线程不安全(执行效率高),在多线程情况下,不建议使用ArrayList
ArrayList底层结构和源码分析
省略此部分
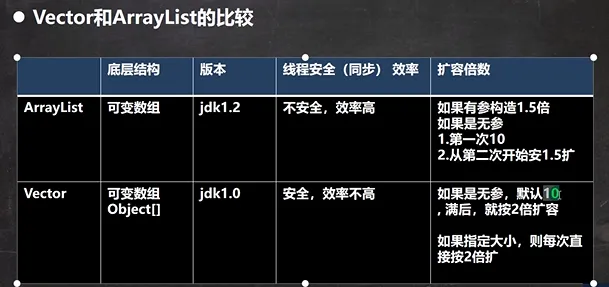
Vector底层结构和源码分析
Vector注意事项
1.Vector底层也是一个对象数组,protected Object[] elementData;
2.Vector是线程同步的,即线程安全的;Vector类的操作方法带有sychronized
Java @SuppressWarnings({"all"}) public class Vector_ { public static void main(String[] args) { Vector vector = new Vector(); for (int i = 0; i < 10; i++) { vector.add(i); } } } |
底层代码——扩容机制(省略)
LinkedList底层结构
一. LinkedList 核心说明提取
1.底层实现:LinkedList 底层实现了双向链表和双端队列的特点。
2.元素特性:可以添加任意元素(元素可重复),包括 null。
3.线程安全:线程不安全,没有实现同步。
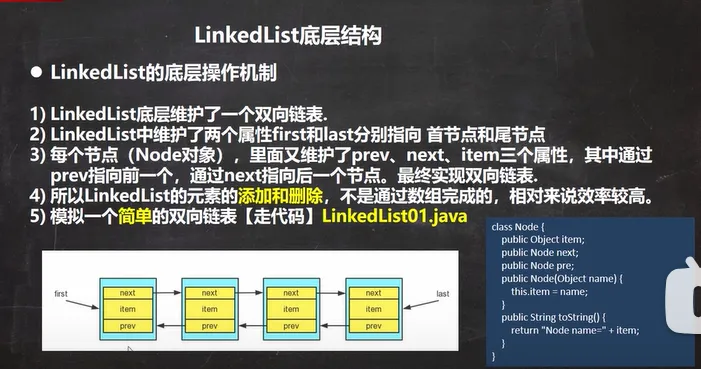
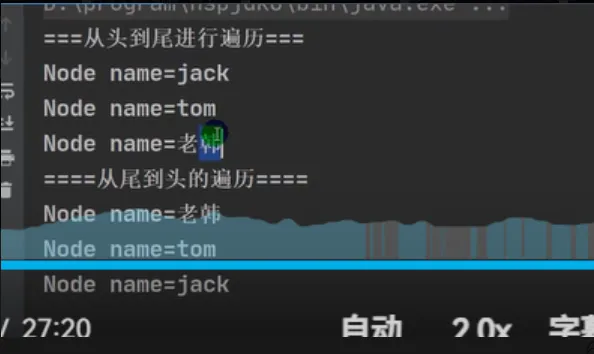
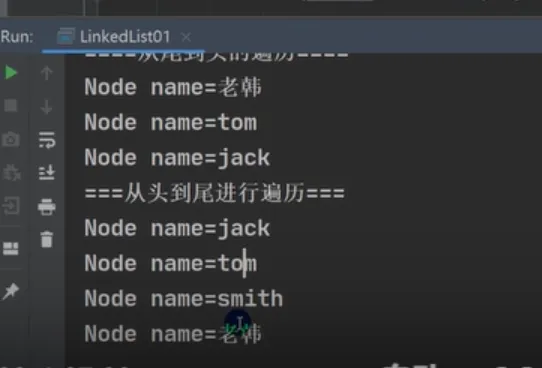
Java public class LinkedList01 { public static void main(String[] args) { //模拟一个简单的双向链表 Node jack = new Node("jack"); Node tom = new Node("tom"); Node hsp = new Node("老韩"); //连接三个结点,形成双向链表 //jack -> tom -> hsp jack.next = tom; tom.next = hsp; //hsp -> tom -> jack hsp.pre = tom; tom.pre = jack; Node first = jack; //让first引用指向jack,就是双向链表的头结点 Node last = hsp;//让last引用指向hsp,就是双向链表的尾结点 //演示,从头到尾进行遍历 System.out.println("===从头到尾进行遍历==="); while (true) { if (first == null) { break; } //输出first信息 System.out.println(first); first = first.next; } //演示,从尾到头的遍历 System.out.println("====从尾到头的遍历===="); while (true) { if (last == null) { break; } //输出last信息 System.out.println(last); last = last.pre; } //演示链表的添加对象/数据,是多么的方便 //要求:是在 tom -------- 老韩之间,插入一个对象 smith //1. 先创建一个Node结点,name就是smith Node smith = new Node("smith"); //下面就把smith加入到双向链表了 smith.next = hsp; smith.pre = tom; hsp.pre = smith; tom.next = smith; //让first再次指向jack first = jack; //让first引用指向jack,就是双向链表的头结点 System.out.println("===从头到尾进行遍历==="); while (true) { if (first == null) { break; } //输出first信息 System.out.println(first); first = first.next; } } } //定义一个Node类,Node对象表示双向链表的一个结点 class Node { public Object item; //真正存放数据 public Node next;//指向后一个结点 public Node pre;//指向前一个结点 public Node(Object name) { this.item = name; } public String toString() { return "Node name=" + item; } } |
LinkList的使用
1.增: add()添加元素
2.删:remove()删除头结点或者指定索引结点
3.改: set() 修改指定索引结点的值
4.查:get()获取指定索引结点的值
5.遍历:迭代器、增强for循环,普通for循环
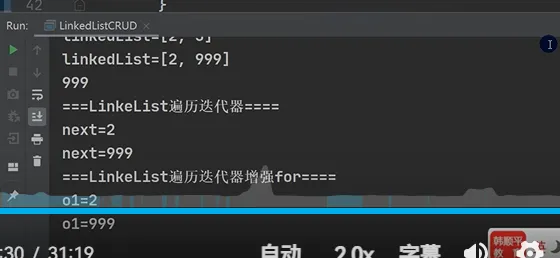
Java import java.util.Iterator; import java.util.LinkedList; public class LinkedListCRUD { public static void main(String[] args) { LinkedList linkedList = new LinkedList();linkedList.add(1); linkedList.add(2); linkedList.add(3); System.out.println("linkedList=" + linkedList); // 演示删除结点(默认删除第一个结点) linkedList.remove();// linkedList.remove(2); // 按索引删除 System.out.println("linkedList=" + linkedList); // 修改某个结点对象 linkedList.set(1, 999);System.out.println("linkedList=" + linkedList); // 得到某个结点对象(get(1) 获取双向链表的第二个对象) Object o = linkedList.get(1);System.out.println(o); // 999 // 因为LinkedList实现了List接口,遍历方式 // 1. 迭代器遍历 System.out.println("===LinkedList遍历迭代器==="); Iterator iterator = linkedList.iterator();while (iterator.hasNext()) {//先判断是否存在下一个再继续Object next = iterator.next(); System.out.println("next=" + next); } // 2. 增强for循环遍历 System.out.println("===LinkedList遍历迭代器增强for==="); for (Object o1 : linkedList) { System.out.println("o1=" + o1); } // 3. 普通for循环遍历 System.out.println("===LinkedList遍历普通for==="); for (int i = 0; i < linkedList.size(); i++) { System.out.println(linkedList.get(i)); } } } |
ArrayList和LinkedList的比较总结
Set接口介绍(继承Collection接口)
基本介绍:
核心特性:
•无序:元素添加顺序与取出顺序不一致,不支持索引访问。
•不允许重复:集合中不能存在重复元素,因此最多只能包含一个 null。
继承与实现:
•继承自 Collection 和 Iterable 接口。
•已知子接口:NavigableSet、SortedSet。
•已知实现类:AbstractSet、ConcurrentSkipListSet、CopyOnWriteArraySet、EnumSet、HashSet、JobStateReasons、LinkedHashSet、TreeSet 等。
•常用实现类:HashSet、LinkedHashSet、TreeSet。
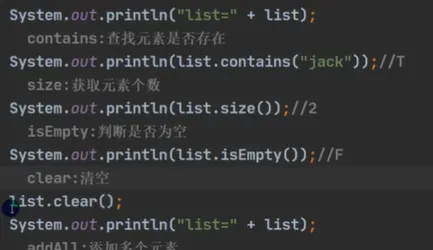
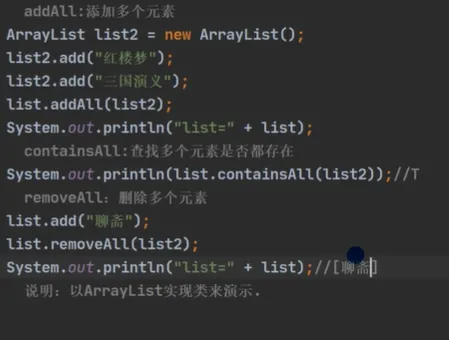
常用方法
•Set 接口是 Collection 接口的子接口,因此常用方法与 Collection 接口完全一致。
•导入包:
Java import java.util.Set;//或者万能包 |
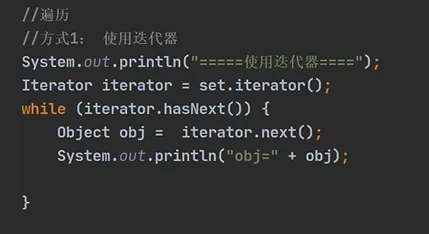
1.迭代器遍历:
2.增强for循环遍历
3.Set接口对象,不能通过索引获取,所以不能使用普通for循环遍历
遍历方式(以上)
•与 Collection 接口的遍历方式一致:
a.迭代器(Iterator)
b.增强 for 循环(foreach)
c.不支持通过索引的方式遍历 / 获取元素(因为 Set 无序且无索引)。
分类:HashSet和TreeSet,继承Set接口,Set又继承collection接口
HashSet
一.基本介绍
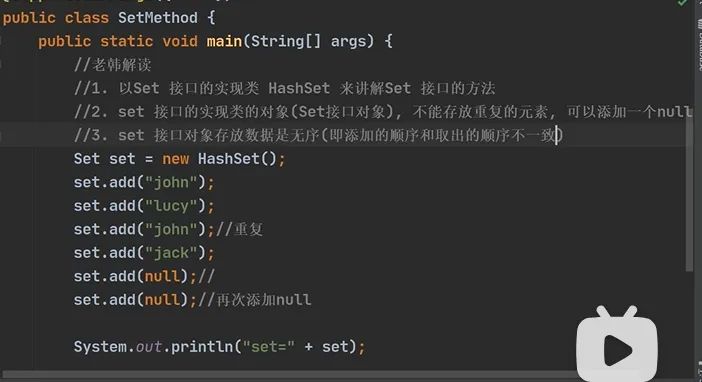
TypeScript @SuppressWarnings({"all"}) public class HashSet_ { public static void main(String[] args) { //1. 构造器HashSet走的源码(底层源码) /* public HashSet() { //HashSet实际上是HashMapmap = new HashMap<>(); } 2. HashSet可以存放一个null,但只能有一个null*/ Set hashSet = new HashSet(); hashSet.add(null); hashSet.add(null); System.out.println("hashSet="+hashSet); } } |
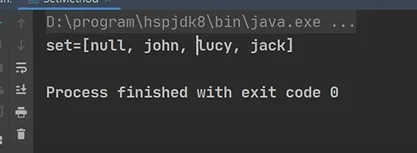
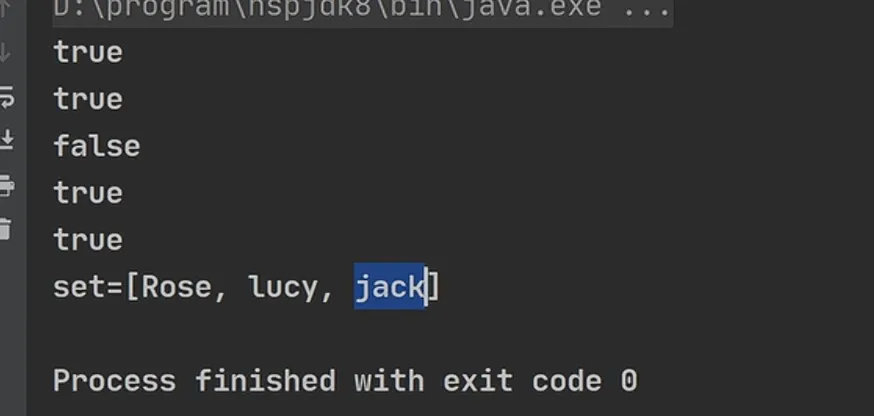
1.验证HashSet不允许有重复元素
C++ import java.util.HashSet; public class HashSet01 { public static void main(String[] args) { HashSet set = new HashSet(); // 说明 // 1. 在执行add方法后,会返回一个boolean值 // 2. 如果添加成功,返回 true,否则返回false System.out.println(set.add("john"));// T System.out.println(set.add("lucy"));// T System.out.println(set.add("john"));// F(重复元素,添加失败) System.out.println(set.add("jack"));// T System.out.println(set.add("Rose"));// T set.remove("john"); System.out.println("set=" + set); } } |
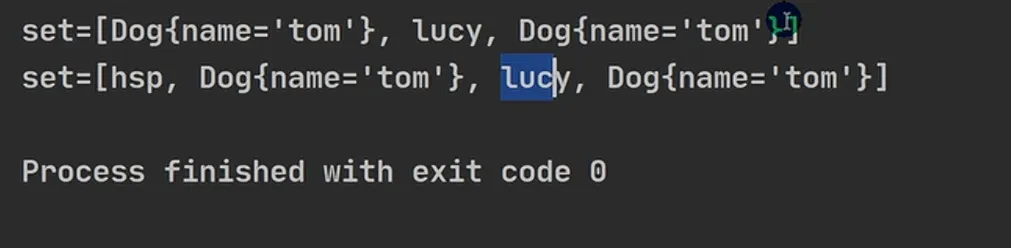
2.HashSet不允许有重复元素,为什么直接new一个Dog对象就可以重复呢?而new一个String对象却不可以重复
TypeScript import java.util.HashSet; // 定义了Dog类 class Dog { private String name; public Dog(String name) { this.name = name; } // 为了打印美观,补充toString方法 @Override public String toString() { return "Dog{name='" + name + "'}"; } } public class HashSetDemo { public static void main(String[] args) { HashSet set = new HashSet(); System.out.println("set=" + set); // 0 // 4 HashSet 不能添加相同的元素/数据? set.add("lucy"); // 添加成功 set.add("lucy"); // 加入不了(重复元素) set.add(new Dog("tom")); // OK set.add(new Dog("tom")); // OK(未重写equals和hashCode,视为不同对象) System.out.println("set=" + set); // 再加深一下。非常经典的面试题。 // 看源码,做分析 set.add(new String("hsp")); // ok set.add(new String("hsp")); // 加入不了(String重写了equals和hashCode,视为相同对象) System.out.println("set=" + set); } } |
二.HashSet底层机制说明
1.HashSet底层是HashMap,HashMap底层是(数组+链表+红黑树)
想像模拟一下哈希表:有一个数组,每个数组元素都单独带有一条链表,数组的大小就是链表的条数
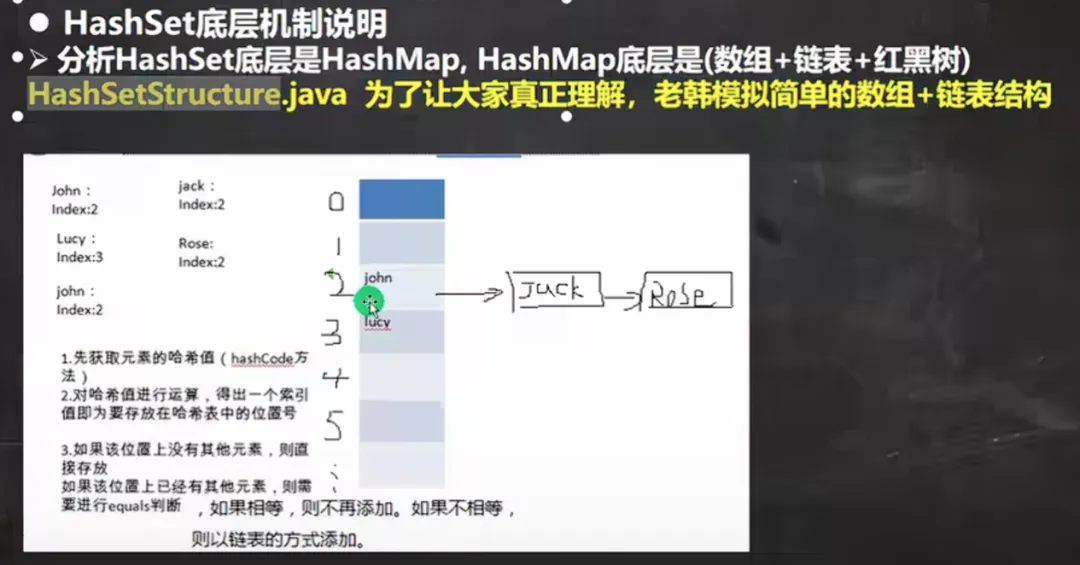
构造器快捷键:
Alt + Insert(Windows/Linux)
2.代码演示(哈希表数据存储效率高效)
Java @SuppressWarnings({"all"}) // 结点类:存储数据并指向下一个结点,用于形成链表 class Node { Object item; // 存放数据 Node next;// 指向下一个结点 // 带参构造器,初始化结点数据和下一个结点引用 public Node(Object item, Node next) { this.item = item; this.next = next; } } public class HashSetStructure { public static void main(String[] args) { // 模拟HashSet/HashMap的底层结构:数组+链表 // 1. 创建Node类型的数组(也称为"表"),初始容量为16 Node[] table = new Node[16]; System.out.println("table=" + table); // 3. 创建结点并挂载到数组 // 创建john结点,挂载到数组索引2的位置 Node john = new Node("john", null); table[2] = john; // 创建jack结点,挂载到john结点之后 Node jack = new Node("jack", null); john.next = jack; // 创建Rose结点,挂载到jack结点之后 Node rose = new Node("Rose", null); jack.next = rose; // 创建lucy结点,挂载到数组索引3的位置 Node lucy = new Node("lucy", null); table[3] = lucy; System.out.println("table=" + table); } } |
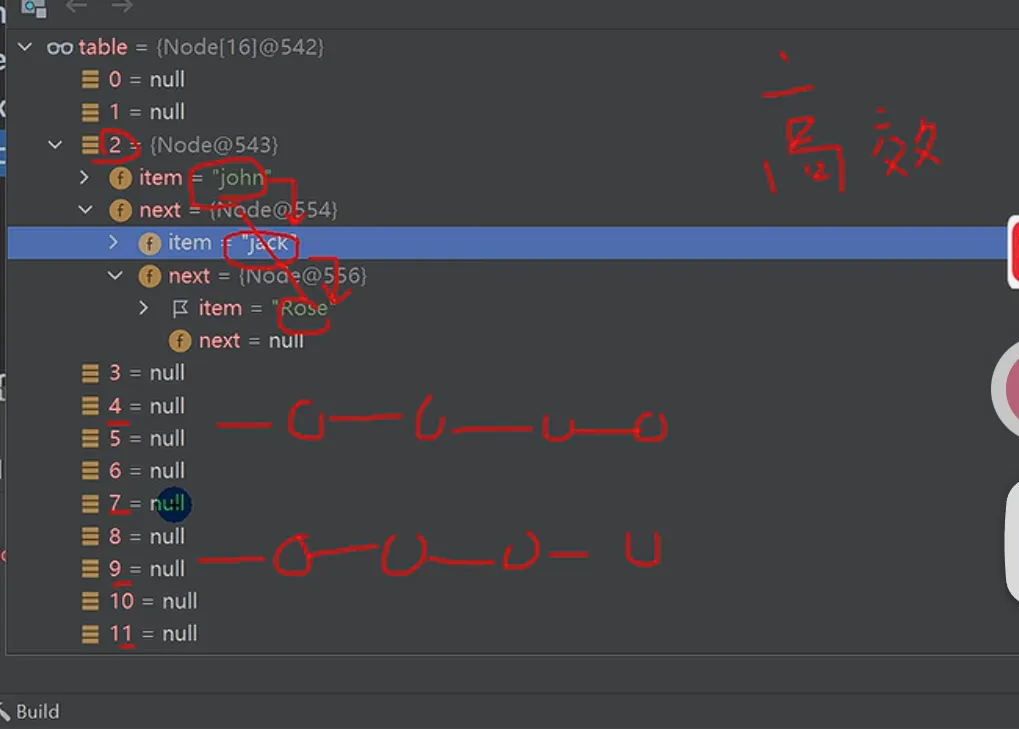
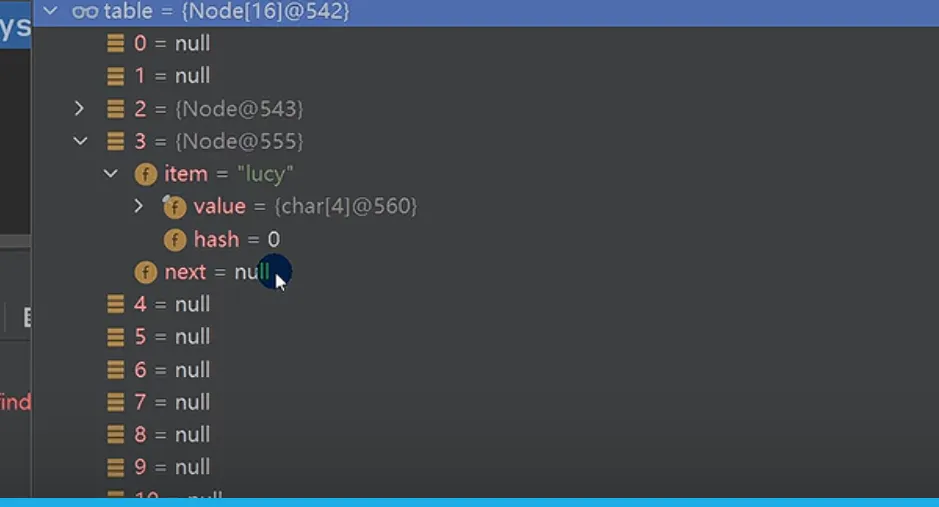
3.为什么new一个重复Dog对象可以插入,而new一个新的String对象却不可以(面试题)
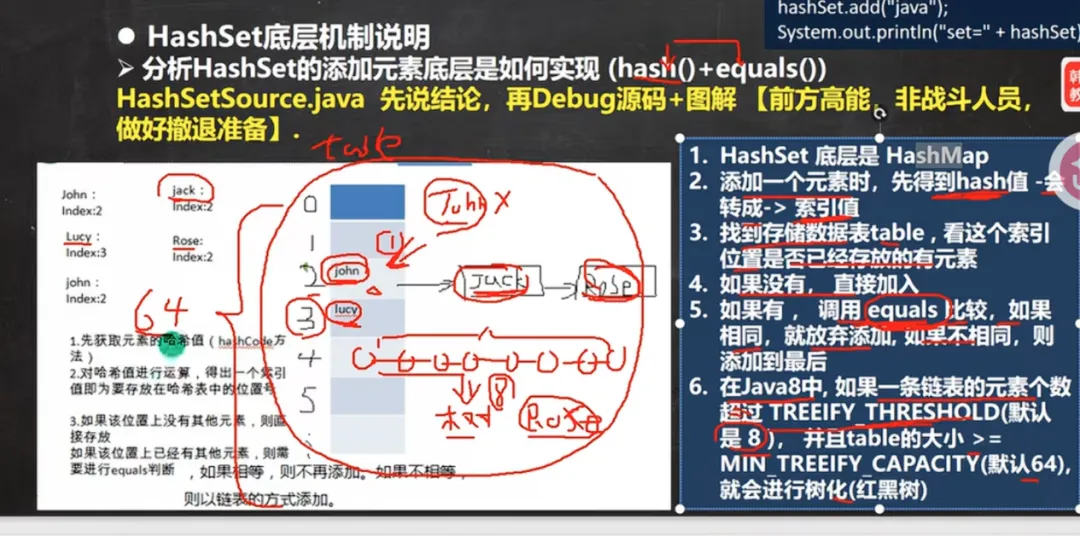
HashSet 底层是 HashMap
1)添加一个元素时,先得到 hash 值 → 转换成索引值
2)找到存储数据表 table,检查该索引位置是否已存在元素
3)如果没有元素,直接将新元素加入(插入元素到链表中)
5)如果已有元素:
•调用 equals() 进行比较
•若 equals 返回 true(元素相同),则放弃添加
•若 equals 返回 false(元素不同),则将新元素添加到链表末尾
6) Java 8 树化规则(面试重点):
○当一条链表的元素个数超过 TREEIFY_THRESHOLD(默认值为 8)
○并且数组 table 的大小 ≥ MIN_TREEIFY_CAPACITY(默认值为 64)
○满足以上两个条件时,该链表会被转换为红黑树(树化),以提升查询效率
关键补充说明
•hash → 索引:hash 值并非直接作为索引,而是通过 (n - 1) & hash(n 为数组长度)计算得到数组下标,保证索引落在数组范围内。
•equals 比较:先比较 hashCode(),再比较 equals(),只有两者都相同时,才判定为重复元素。
•树化目的:链表过长时查询效率会退化到 O (n),红黑树可将查询效率优化到 O (log n)。
三. HashSet底层源码
靠理解,这里省略,请前往韩顺平java基础视频521~524理解
四.课堂练习:灵活使用HashSet
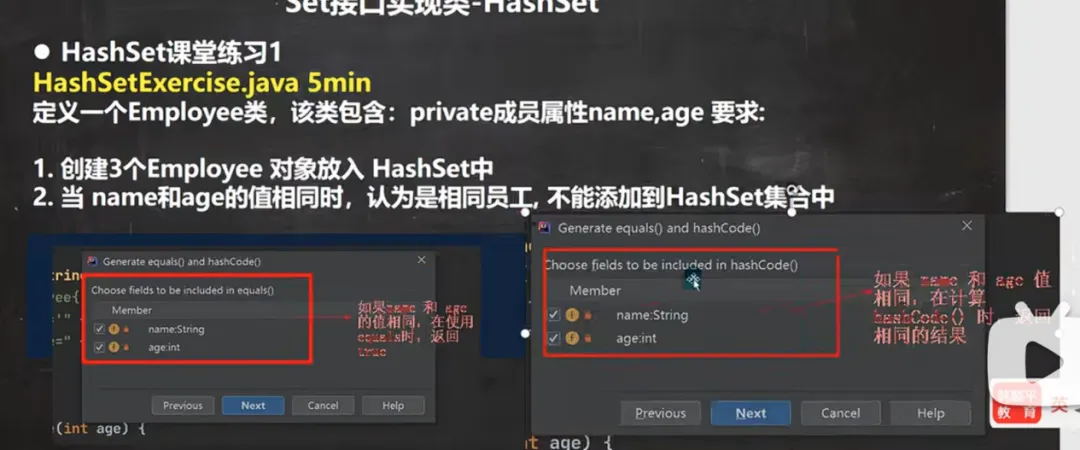
TypeScript import java.util.HashSet; import java.util.Objects; class Employee { private String name; private int age; // 构造器 public Employee(String name, int age) { this.name = name; this.age = age; } // Getter & Setter public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } // 重写equals:name和age都相同时视为同一员工 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return age == employee.age && Objects.equals(name, employee.name); } // 重写hashCode:基于name和age生成哈希值,保证相同员工哈希值一致 @Override public int hashCode() { return Objects.hash(name, age); } // 重写toString:方便打印查看 @Override public String toString() { return "Employee{name='" + name + "', age=" + age + "}"; } } public class HashSetExercise { public static void main(String[] args) { HashSethashSet = new HashSet<>(); // 添加员工对象 hashSet.add(new Employee("milan", 18)); // 添加成功 hashSet.add(new Employee("smith", 28)); // 添加成功 hashSet.add(new Employee("milan", 18)); // 添加失败(与第一个对象name和age相同) // 打印集合,验证去重效果 System.out.println("hashSet=" + hashSet); } } |

1.最终集合中只包含 2 个 员工对象,第三个 new Employee("milan", 18) 因与第一个对象 name 和 age 完全相同,被 HashSet 判定为重复元素而拒绝添加。
2.去重关键:HashSet 去重依赖 hashCode() 和 equals() 方法,必须同时重写才能实现自定义对象的去重逻辑。
3.哈希计算:Objects.hash(name, age) 会根据 name 和 age 生成哈希值,保证相同属性的对象哈希值一致。
4.相等判断:equals() 方法中同时比较 age 和 name,只有两者都相等时才认为是同一个员工。

TypeScript import java.util.HashSet; import java.util.Objects; /** * 自定义日期类 */ class MyDate { private int year; private int month; private int day; public MyDate(int year, int month, int day) { this.year = year; this.month = month; this.day = day; } // Getter public int getYear() { return year; } public int getMonth() { return month; } public int getDay() { return day; } // 重写equals:年月日都相同视为同一日期 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MyDate myDate = (MyDate) o; return year == myDate.year && month == myDate.month && day == myDate.day; } // 重写hashCode:基于年月日生成哈希值 @Override public int hashCode() { return Objects.hash(year, month, day); } // 重写toString,方便打印 @Override public String toString() { return year + "年" + month + "月" + day + "日"; } } /** * 员工类 */ class Employee { private String name;// 姓名 private double sal;// 薪资 private MyDate birthday; // 生日 // 构造器 public Employee(String name, double sal, MyDate birthday) { this.name = name; this.sal = sal; this.birthday = birthday; } // Getter & Setter public String getName() { return name; } public void setName(String name) { this.name = name; } public double getSal() { return sal; } public void setSal(double sal) { this.sal = sal; } public MyDate getBirthday() { return birthday; } public void setBirthday(MyDate birthday) { this.birthday = birthday; } // 重写equals:name和birthday都相同时,视为同一员工 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return Objects.equals(name, employee.name) && Objects.equals(birthday, employee.birthday); } // 重写hashCode:基于name和birthday生成哈希值 @Override public int hashCode() { return Objects.hash(name, birthday); } // 重写toString:方便打印查看集合内容 @Override public String toString() { return "Employee{name='" + name + "', sal=" + sal + ", birthday=" + birthday + "}"; } } /** * 测试类 */ public class HashSetExercise2 { public static void main(String[] args) { HashSethashSet = new HashSet<>(); // 创建日期对象 MyDate date1 = new MyDate(1990, 1, 1); MyDate date2 = new MyDate(1995, 5, 20); MyDate date3 = new MyDate(1990, 1, 1); // 与date1日期相同 // 添加员工对象 hashSet.add(new Employee("milan", 5000, date1));// 添加成功 hashSet.add(new Employee("smith", 8000, date2));// 添加成功 hashSet.add(new Employee("milan", 6000, date3));// 添加失败(name和birthday与第一个一致) // 打印集合,验证去重效果 System.out.println("hashSet=" + hashSet); } } |
运行:
Java hashSet=[Employee{name='milan', sal=5000.0, birthday=1990年1月1日}, Employee{name='smith', sal=8000.0, birthday=1995年5月20日}] |
LinkedHashSet:
LinkedHashSet接口继承HashSet接口,它和HashSet最大的区别就在它是双向的,而HashSet是单向的
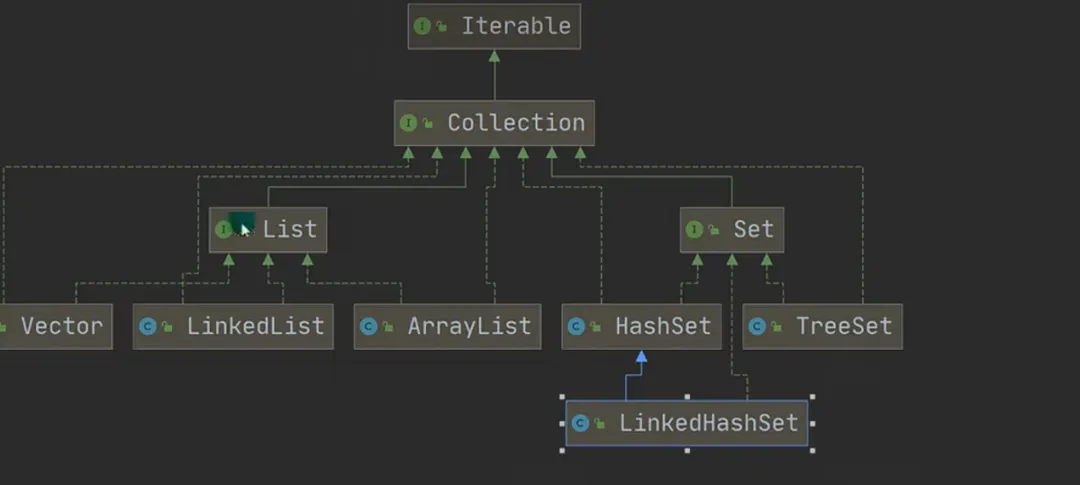
1.继承关系:LinkedHashSet 是 HashSet 的子类。
2.底层结构:底层基于 LinkedHashMap 实现,维护 数组 + 双向链表 的数据结构。哈希表(数组 + 链表 / 红黑树)+ 双向链表
双向链表有 head(头节点)和 tail(尾节点)指针,每个节点包含 pre(前驱)和 next(后继)属性
3.存储与顺序:
○根据元素的 hashCode 值决定存储位置。
○用链表维护元素次序(图),保证元素以插入顺序保存。即取出和存储进去的顺序是一样的
C++ Set set = new LinkedHashSet(); set.add(new String("AA")); set.add(456); set.add(456); // 重复元素,不会被添加 set.add(new Customer("刘", 1001)); set.add(123); set.add("HSP"); |
遍历顺序:严格按照插入顺序输出 → AA → 456 → Customer(刘,1001) → 123 → HSP
重复元素 456 只会保留一份,符合 Set 集合 “不允许重复” 的特性。
4.元素特性:不允许添加重复元素。
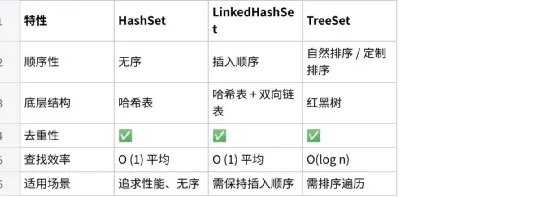
点击图片可查看完整电子表格
Map接口(存储key-value键值对),与Collection接口并列
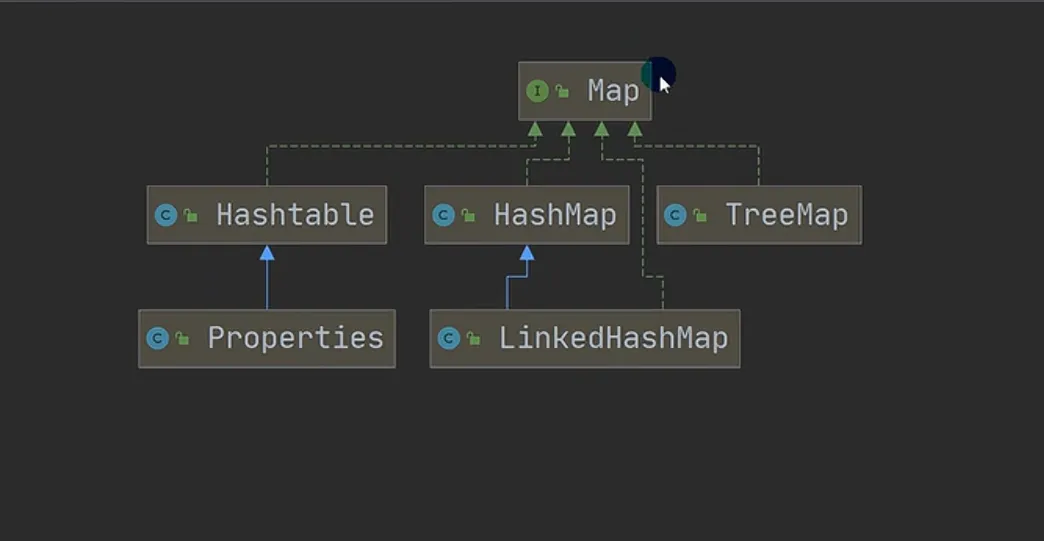
Map接口和常用方法(Map接口实现类——HashMap)
Map 接口实现类的特点,使用实现类 HashMap举例
1.Map 与 Collection 并列存在。用于保存具有映射关系的数据:Key-Value (双列元素)
2.Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中
3.Map 中的 key 不允许重复,原因和 HashSet 一样,前面分析过源码。
4.Map 中的 value 可以重复
5.Map 的 key 可以为 null, value 也可以为 null ,注意 key 为 null, 只能有一个,value 为 null , 可以多个。
6.常用 String 类作为 Map 的 key
7.key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
TypeScript import java.util.HashMap; import java.util.Map; /** * 演示JDK8中HashMap的核心特点 * 对应Map接口实现类的核心特性 */ public class HashMapFeaturesDemo { public static void main(String[] args) { // 创建HashMap对象,Key为String类型,Value为Integer类型 Map<String, Integer> hashMap = new HashMap<>(); //常用String类作为Map的key// 1. 向Map中添加键值对(Key-Value映射关系)hashMap.put("张三", 20); hashMap.put("李四", 22); hashMap.put("王五", 20); // value可以重复hashMap.put("赵六", null); // value可以为null hashMap.put(null, 30); // key可以为null hashMap.put(null, 35); // key为null只能有一个(后面的会覆盖前面的)hashMap.put("孙七", null); // 可以有多个value为null //hashMap.put("张三", 100); //当key值相等时,就等价于替换,将前面的20改为100// 打印整个HashMap,查看结果 System.out.println("1. 完整的HashMap内容:" + hashMap); // 输出:{null=35, 张三=20, 李四=22, 王五=20, 赵六=null, 孙七=null} // 2. 验证key不允许重复(重复添加会覆盖原有value)hashMap.put("张三", 25); // 重复的key,覆盖原有value System.out.println("2. 重复添加key'张三'后的结果:" + hashMap.get("张三")); // 输出:25(原20被覆盖) // 3. 验证value可以重复 System.out.println("3. 验证value可以重复:"); System.out.println("'张三'的value:" + hashMap.get("张三")); // 20 System.out.println("'李四'的value:" + hashMap.get("李四")); // 22 System.out.println("'王五'的value:" + hashMap.get("王五")); // 20 // 可以看到value=20出现了多次// 4. 验证key为null只能有一个 System.out.println("4. key为null的value值:" + hashMap.get(null)); // 输出:35(最后一次添加的null key对应的value) // 5. 验证value为null可以有多个 System.out.println("5. 多个value为null的验证:"); System.out.println("'赵六'的value:" + hashMap.get("赵六")); // null System.out.println("'孙七'的value:" + hashMap.get("孙七")); // null // 6. 验证key和value的单向一对一关系(通过key总能找到唯一的value) String targetKey = "李四"; Integer targetValue = hashMap.get(targetKey); System.out.println("6. 通过key'" + targetKey + "'找到的value:" + targetValue); // 输出:22(唯一对应) // 7. 常用操作:遍历Map System.out.println("\n7. 遍历HashMap的所有键值对:"); for (Map.Entryentry : hashMap.entrySet()) { System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue()); } } } |
8.
Entry 映射关系:每一对 key-value 本质上是一个 Map.Entry 对象,HashMap 中用内部类 Node 实现了 Entry 接口。
HashMap$Node 与 Entry 的关系
•HashMap$Node 是 HashMap 的静态内部类,它实现了 Map.Entry 接口。
•因此,一个 Node 对象就代表了一个完整的 key-value 映射,所以很多资料会直接说 “一对 k-v 就是一个 Entry”(不严谨)。
•node内部代码简化:
Java static class Nodeimplements Map.Entry{ final int hash; final K key; V value; Nodenext; // 用于链表解决哈希冲突 } |
•代码演示(为了方便程序员遍历,会创建EntrySet集合,该集合存放的元素的类型Entry对象,而一个Entry对象就有key-value对象,提供getKey()和getValue方法获取):
TypeScript import java.util.HashMap; import java.util.Map; public class MapEntryDemo { public static void main(String[] args) { Mapmap = new HashMap<>(); map.put("Java", 100); map.put("Python", 90); Set set=map.entrySet(); sout(set.getClass());//输出HashMap$EntrySet集合(即HashMap中的EntrySet集合 ) //entrySet中定义的类型是Map.Entry,但实际上存放的还是HashMap$Node(即HashMap中的Node类) //因为static class Nodeimplements Map.Entry类,方便遍历(多态:A类实现B接口类,则A类对象实例(Node)可以赋值给B类的接口类型(Entry))//Map.Entry提供K:getKey();V: getVakue()方法 // 遍历 Entry 集合,本质上就是遍历 Node,为了遍历方便而创建EntrySet集合for (Map.Entryentry: map.entrySet()) { System.out.println("key: " + entry.getKey() + ", value: " + entry.getValue()); } } } |
Map接口常用方法
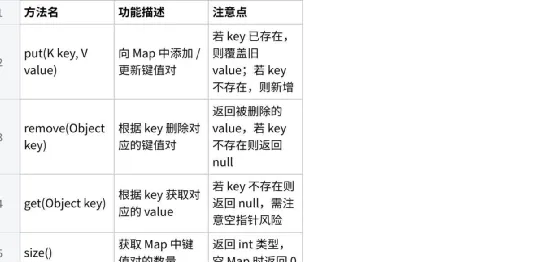
点击图片可查看完整电子表格
代码示例:
Go import java.util.HashMap; import java.util.Map; public class MapMethod { public static void main(String[] args) { Mapmap = new HashMap<>(); // 1. put:添加元素 map.put("Java", 100); map.put("Python", 90); map.put("Java", 95); // 覆盖旧值 // 2. size:获取元素个数 System.out.println("元素个数:" + map.size()); // 输出 2 // 3. isEmpty:判断是否为空 System.out.println("是否为空:" + map.isEmpty()); // 输出 false // 4. get:根据 key 获取 value System.out.println("Java 的分数:" + map.get("Java")); // 输出 95 // 5. containsKey:判断 key 是否存在 System.out.println("是否包含 C++:" + map.containsKey("C++")); // 输出 false // 6. remove:根据 key 删除元素 Integer removed = map.remove("Python"); System.out.println("被删除的 value:" + removed); // 输出 90 // 7. clear:清空所有元素 map.clear(); System.out.println("清空后元素个数:" + map.size()); // 输出 0 } } |
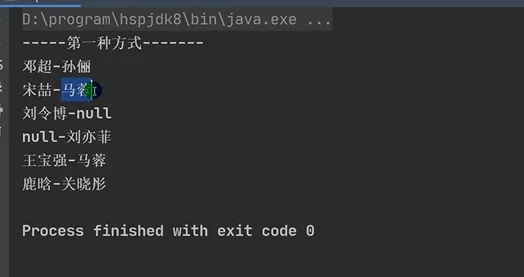
Map六大遍历方法
遍历方式分类:
•第一组:通过 keySet() 获取所有 key,再遍历 key 得到 value。
•第二组:通过 values() 直接获取所有 value,仅遍历值。
•第三组:通过 entrySet() 获取键值对 Entry 对象,一次遍历得到 key 和 value,效率最高(推荐使用)。
代码示例:
Java import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; @SuppressWarnings({"all"}) public class MapFor { public static void main(String[] args) { Map map = new HashMap(); map.put("邓超", "孙俪"); map.put("王宝强", "马蓉"); map.put("宋喆", "马蓉"); map.put("刘令博", null); map.put(null, "刘亦菲"); map.put("鹿晗", "关晓彤"); // 第一组:先取出所有的Key,通过Key取出对应的Value Set keySet = map.keySet(); // (1) 增强for System.out.println("-----第一种方式-----"); for (Object key : keySet) { System.out.println(key + "-" + map.get(key)); } // (2) 迭代器 System.out.println("-----第二种方式-----"); Iterator iterator = keySet.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(key + "-" + map.get(key)); } // 第二组:把所有的values取出 Collection values = map.values(); // (1) 增强for System.out.println("---取出所有的value 增强for---"); for (Object value : values) { System.out.println(value); } // (2) 迭代器 System.out.println("---取出所有的value 迭代器---"); Iterator iterator2 = values.iterator(); while (iterator2.hasNext()) { Object value = iterator2.next(); System.out.println(value); } // 第三组:通过EntrySet来获取k-v Set entrySet = map.entrySet(); // (1) 增强for System.out.println("---使用EntrySet的for增强(第3种)---"); for (Object entry : entrySet) { // 将entry转成Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); } // (2) 迭代器 System.out.println("---使用EntrySet的迭代器(第4种)---"); Iterator iterator3 = entrySet.iterator(); while (iterator3.hasNext()) { Object entry = iterator3.next(); // 向下转型 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); } } } |
泛型优化提示:实际开发中建议使用泛型(如 Map),避免强制类型转换,代码更安全简洁:
JavaScript Mapmap = new HashMap<>(); // ... for (Map.Entryentry : map.entrySet()) { System.out.println(entry.getKey() + "-" + entry.getValue()); } |
练习
题目:

代码:
Java import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; // 员工类:封装属性,提供getter/setter和toString class Emp { private String name; private double sal; private int id; // 构造器 public Emp(String name, double sal, int id) { this.name = name; this.sal = sal; this.id = id; } // getter/setter 封装方法,实现数据封装与安全访问public String getName() { return name; } public void setName(String name) { this.name = name; } public double getSal() { return sal; } public void setSal(double sal) { this.sal = sal; } public int getId() { return id; } public void setId(int id) { this.id = id; } // 重写toString,方便打印对象信息 @Override public String toString() { return "Emp{" + "name='" + name + '\'' + ", sal=" + sal + ", id=" + id + '}'; } } // 主类:Map练习 @SuppressWarnings({"all"}) public class MapExercise { public static void main(String[] args) { Map hashMap = new HashMap(); // 添加员工对象(键:员工id,值:Emp对象) hashMap.put(1, new Emp("jack", 300000, 1)); hashMap.put(2, new Emp("tom", 1000, 2)); hashMap.put(3, new Emp("milan", 12000, 3)); // 遍历方式1:keySet + 增强for //方式 1:通过 keySet() 获取所有键,遍历键后用 get(key) //获取对应 Emp 对象,再筛选工资。 System.out.println("=====第一种遍历方式(keySet+增强for)====="); Set keySet = hashMap.keySet(); for (Object key : keySet) { Emp emp = (Emp) hashMap.get(key); // 筛选工资>18000的员工 if (emp.getSal() > 18000) { System.out.println(emp); } } // 遍历方式2:entrySet + 迭代器 //方式 2:通过 entrySet() 获取键值对 Entry 集合, //用迭代器遍历,直接从 Entry 中取出 value(即 Emp 对象),效率更高(推荐)。 System.out.println("=====第二种遍历方式(entrySet+迭代器)====="); Set entrySet = hashMap.entrySet(); Iterator iterator = entrySet.iterator(); while (iterator.hasNext()) { Map.Entry entry = (Map.Entry) iterator.next(); Emp emp = (Emp) entry.getValue(); // 筛选工资>18000的员工 if (emp.getSal() > 18000) { System.out.println(emp); } } } } |
运行结果:
Java =====第一种遍历方式(keySet+增强for)===== Emp{name='jack', sal=300000.0, id=1} =====第二种遍历方式(entrySet+迭代器)===== Emp{name='jack', sal=300000.0, id=1} |
实际开发中建议使用泛型,避免强制类型转换,代码更安全:
Java MaphashMap = new HashMap<>(); // ... for (Integer key : hashMap.keySet()) { Emp emp = hashMap.get(key); } // 或 for (Map.Entryentry : hashMap.entrySet()) { Emp emp = entry.getValue(); } |
HashMap小结
1.Map 接口常用实现类
•HashMap、Hashtable、Properties
1.3.1.1 HashMap 地位
•是 Map 接口中使用频率最高 的实现类
1.3.1.2 数据存储方式
•以 key-value 键值对 形式存储,底层通过 Entry(HashMap$Node)对象封装每一对 k-v
1.3.1.3 key 与 value 特性
•key:不可重复,允许为 null(最多 1 个 null key)
•value:可重复,允许为 null(多个 null value 均可)
1.3.1.4 重复 key 处理
•若添加已存在的 key,不会新增,而是覆盖原有的 value,等价于 “修改操作”(key 保持不变,仅替换 value)
1.3.1.5 顺序性
•与 HashSet 一致,不保证存储 / 遍历顺序,因为底层基于 hash 表的方式来存储的(hashMap底层:数组+链表+红黑树)
1.3.1.6 线程安全
•未实现同步(synchronized),因此是 线程不安全 的,多线程环境下需手动处理同步或使用 ConcurrentHashMap
HashMap底层原理和代码剖析
该方面靠理解,可观看原视频536~538
结论:

精简记忆版
1.结构:Node 数组 table,初始为 null
2.加载因子:默认 0.75,首次扩容后容量 16,临界值 12
3.添加:哈希定位 → 冲突判断 → 链表 / 红黑树处理 → 覆盖 / 追加
4.扩容:2 倍扩容,临界值同步 2 倍
5.树化:链表长度 ≥ 8 且数组容量 ≥ 64 → 转红黑树
Map接口实现类——HashTable
基本介绍
存储结构
•存放元素为 键值对(K-V),实现 Map 接口,与 HashMap结构一致。
1.3.1.7 Key 与 Value 的限制
•键(key):不能为 null
•值(value):不能为 null
•违反任一限制将直接抛出 NullPointerException 空指针异常
Java import java.util.Hashtable; @SuppressWarnings({"all"}) public class HashTableExercise { public static void main(String[] args) { Hashtable table = new Hashtable();//ok table.put("john", 100); //ok //table.put(null, 100); //异常 NullPointerException //table.put("john", null);//异常 NullPointerException table.put("lucy", 100);//ok table.put("lic", 100);//ok table.put("lic", 88);//替换 System.out.println(table); } } |
1.3.1.8 使用方式
•使用方法 基本与 HashMap 一致,常用方法如 put()、get()、remove() 等用法相同。
1.3.1.9 线程安全性
•线程安全:方法采用 synchronized 同步修饰,多线程操作时无需额外同步控制。
•线程不安全:与之对比,HashMap 未实现同步,多线程环境下可能出现数据异常。
Map接口实现类——Properties
常用于读取配置文件,如何读取配置文件可前往:
为什么要有配置文件这种东西呢?
因为类似数据库的JDBC就将数据库连接代码写死了,将用户账号和密码等信息写死在了代码里边,如果需要修改就得修改代码,这就意味着需要重新测试运行打包;
https://www.cnblogs.com/xudong-bupt/p/3758136.html学习(韩顺平的随笔学习笔记,产自博客园,一个类似CSDN的程序员网站)
基本介绍
继承与实现
•继承自 Hashtable 类,同时实现了 Map 接口,本质是一个键值对存储结构。
•数据存储形式与 HashMap/Hashtable 一致,为K-V 键值对。
1.3.2 使用特点
•基础使用方式与 Hashtable 类似,线程安全(继承了 synchronized 方法)。
•不允许 key 或 value 为 null(继承自 Hashtable 的特性)。
1.3.3 核心特殊功能
•支持从 .properties 配置文件中加载数据到 Properties 对象。
•可对加载后的配置数据进行读取与修改操作,是 Java 中处理配置文件的标准类。
1.3.4 工程应用说明
•.properties 文件是工作中常用的配置文件格式(如数据库连接、系统参数配置)。
•该知识点在 Java IO 流章节,是后端开发的高频实用技能。
1.3.5 拓展学习链接
https://www.cnblogs.com/xudong-bupt/p/3758136.html
代码示例:
Java import java.util.Properties; public class Properties_ { public static void main(String[] args) { // 1. Properties 继承 Hashtable// 2. 可以通过 k-v 存放数据,当然 key 和 value 不能为 null // 增加 Properties properties = new Properties(); // properties.put(null, "abc"); // 抛出 空指针异常 // properties.put("abc", null); // 抛出 空指针异常 properties.put("john", 100); // k-v properties.put("lucy", 100); properties.put("lic", 100); properties.put("lic", 88); // 如果有相同的 key,value 被替换 // 打印所有键值对 System.out.println("properties=" + properties); //(Properties 不保证遍历顺序,输出顺序可能与插入顺序不同) // 通过 k 获取对应值 System.out.println(properties.get("lic")); // 88 } } |
实际开发中如何选择集合实现类

核心选择口诀(底层代码解释请观看视频542-544,靠理解)
1.先分类型:单列用 Collection,双列用 Map
2.单列再分:
○要重复 → 用 List:增删多用 LinkedList,改查多用 ArrayList
○不要重复 → 用 Set:要无序用 HashSet,要排序用 TreeSet(继承Set接口,相当于简介继承了collection接口,最大特点是可以排序),要顺序不变用 LinkedHashSet
TypeScript import java.util.Comparator; import java.util.TreeSet; public class TreeSet_java { public static void main(String[] args) { // 1. 当我们使用无参构造器,创建TreeSet时,仍然是无序的(按自然排序)// 2. 我们希望添加的元素,按照字符串大小来排序(降序)// 3. 使用TreeSet提供的构造器,传入一个比较器(匿名内部类)并指定排序规则 // 方式1:无参构造器(自然排序,即无序) // TreeSet treeSet = new TreeSet();// 方式2:带比较器的构造器(自定义排序) TreeSet treeSet = new TreeSet(new Comparator() { @Override public int compare(Object o1, Object o2) { // 调用String的compareTo方法进行字符串大小比较 // o2.compareTo(o1) → 降序排序;o1.compareTo(o2) → 升序排序 return ((String) o2).compareTo((String) o1); } }); // 添加数据 treeSet.add("jack"); treeSet.add("tom"); treeSet.add("sp"); treeSet.add("a"); // 打印结果:treeSet=[tom, sp, jack, a] System.out.println("treeSet=" + treeSet); } } |
3.双列再分:
○键无序 → HashMap
○键要排序 → TreeMap(底层是红黑树)
TreeMap:自然排序版(底层是红黑树,会默认对Key排序,String默认a-z):
Java import java.util.TreeMap; public class TreeMapDemo { public static void main(String[] args) { // 使用默认的构造器,创建TreeMap(按键的自然排序) TreeMap treeMap = new TreeMap();treeMap.put("jack", "杰克"); treeMap.put("tom", "汤姆");treeMap.put("kristina", "克瑞斯提诺"); treeMap.put("smith", "斯密斯"); // 打印时,会按照 key (String) 的字典序自动排序 System.out.println("treeMap=" + treeMap); //treeMap={jack=杰克, kristina=克瑞斯提诺, smith=斯密斯, tom=汤姆} } } |
TreeMap自定义排序版本:
TypeScript import java.util.Comparator; import java.util.TreeMap; public class TreeMapCustom { public static void main(String[] args) { // 这里使用带比较器的构造器 TreeMap treeMap = new TreeMap(new Comparator() { @Override public int compare(Object o1, Object o2) { // 按照传入的 k(String) 的大小进行排序 // 调用 String 的 compareTo 方法实现字典序比较 return ((String) o1).compareTo((String) o2); } }); // 添加数据 treeMap.put("jack", "杰克"); treeMap.put("tom", "汤姆"); treeMap.put("kristina", "克瑞斯提诺"); treeMap.put("smith", "斯密斯"); // 打印结果 System.out.println("treeMap=" + treeMap); } } |
○要保持插入顺序 → LinkedHashMap
○读配置文件 → Properties
Collections工具类(545~546)
这里的Collections带s,和Collection接口不是一回事,给Java提供的集合工具类(服务于Collection接口(List/Set)和Map接口对象)
1.所有方法均为 static 静态方法,无需创建对象,直接通过类名调用,可对集合元素进行排序、查询、修改等操作。

点击图片可查看完整电子表格

Java import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Collections_ { public static void main(String[] args) { Listlist = new ArrayList<>(); list.add(3); list.add(1); list.add(2); list.add(5); list.add(4); // 1. reverse:反转Collections.reverse(list);System.out.println("反转后:" + list); // [4,5,2,1,3] // 2. shuffle:随机打乱Collections.shuffle(list);System.out.println("随机打乱后:" + list); // 每次结果不同 // 3. sort:自然升序 Collections.sort(list);System.out.println("自然升序后:" + list); // [1,2,3,4,5] // 4. sort:自定义降序Collections.sort(list, new Comparator(){ @Override public int compare(Integer o1, Integer o2) { return o2 - o1; // 降序 } }); System.out.println("自定义降序后:" + list); // [5,4,3,2,1] // 5. swap:交换索引 0 和 2 的元素 Collections.swap(list, 0, 2); System.out.println("交换后:" + list); // [3,4,5,2,1] } } |
记忆要点
•Collections 是工具类,方法全是 static。
•排序类方法主要针对 List,Set/Map需先转成 List 再操作。
•sort() 有两个重载:自然排序 vs 自定义比较器排序。
查找,替换
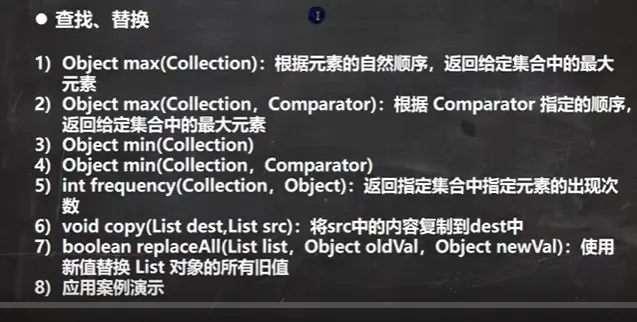
示例代码:
Java import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; @SuppressWarnings({"all"}) public class Collections_ { public static void main(String[] args) { // 1. 创建 ArrayList 集合,用于测试 List list = new ArrayList(); list.add("tom");list.add("smith");list.add("king");list.add("milan");list.add("tom"); // 重复元素,用于测试 frequency// 2. reverse(List): 反转 List 中元素的顺序 Collections.reverse(list);System.out.println("反转后 list=" + list); // 3. shuffle(List): 对 List 集合元素进行随机排序// Collections.shuffle(list); // System.out.println("随机打乱后 list=" + list); // 4. sort(List): 按元素自然顺序升序排序(String 字典序) Collections.sort(list);System.out.println("自然排序后 list=" + list); // 5. sort(List, Comparator): 按字符串长度升序自定义排序Collections.sort(list, new Comparator() { @Override public int compare(Object o1, Object o2) { // 按字符串长度比较:长度小的在前 return ((String) o1).length() - ((String) o2).length(); } }); System.out.println("字符串长度大小排序后 list=" + list); // 6. swap(List, int, int): 交换指定索引的元素Collections.swap(list, 0, 1);System.out.println("交换后的情况"); System.out.println("list=" + list); // 7. max(Collection): 自然顺序最大值Object maxObject = Collections.max(list);System.out.println("自然顺序最大元素=" + maxObject); // 8. max(Collection, Comparator): 按字符串长度找最大值 Object maxLengthObj = Collections.max(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o1).length() - ((String) o2).length(); } }); System.out.println("长度最大的元素=" + maxLengthObj); // 9. min(Collection) / min(Collection, Comparator): 参考 max 方法// 用法与 max 一致,此处省略 // 10. frequency(Collection, Object):统计元素出现次数int tomCount = Collections.frequency(list, "tom");System.out.println("tom出现的次数=" + tomCount); // 11. copy(List dest, List src): 复制集合 // 注意:dest 必须先初始化足够的容量! ArrayList dest = new ArrayList(); // 先填充占位元素,保证容量与 list 一致 for (int i = 0; i < list.size(); i++) { dest.add(""); } Collections.copy(dest, list);System.out.println("复制后的 dest=" + dest); // 12. replaceAll(List list, Object oldVal, Object newVal): 批量替换Collections.replaceAll(list, "tom", "汤姆");System.out.println("list替换后=" + list); } } |
Java 反转后 list=[tom, milan, king, smith, tom] 自然排序后 list=[king, milan, smith, tom, tom] 字符串长度大小排序后 list=[milan, smith, king, tom, tom] 交换后的情况list=[smith, milan, king, tom, tom] 自然顺序最大元素=tom 长度最大的元素=smith tom出现的次数=2 复制后的 dest=[smith, milan, king, tom, tom] list替换后=[smith, milan, king, 汤姆, 汤姆] |
记忆要点
•max/min:支持自然排序和自定义比较器,可作用于所有 Collection。
•frequency:快速统计元素出现频率,适合去重、计数场景。
•copy:目标列表必须先扩容,否则会报错,这是高频易错点。
•replaceAll:批量替换 List 中所有匹配的旧值,返回是否发生替换

