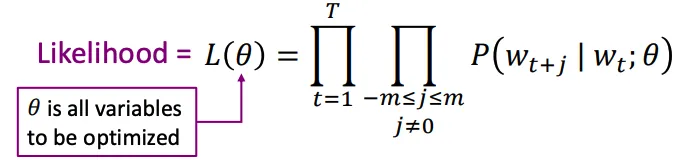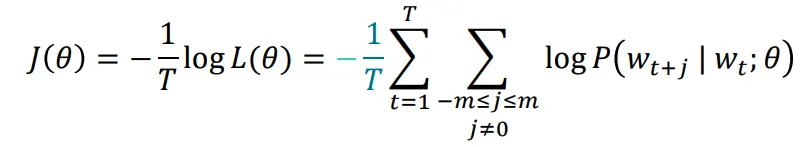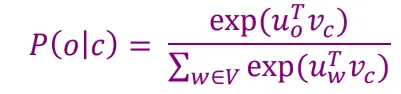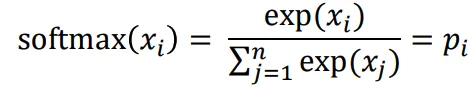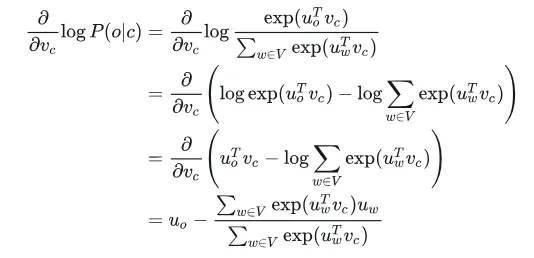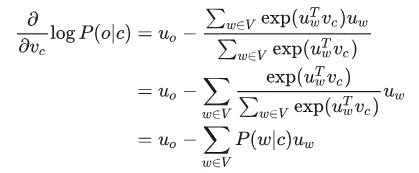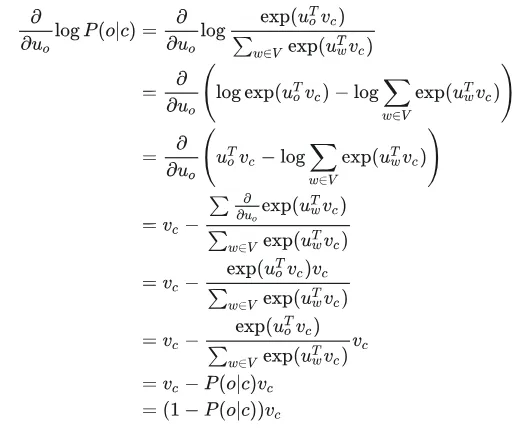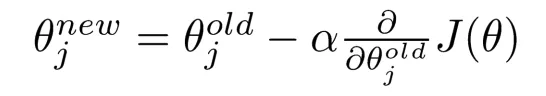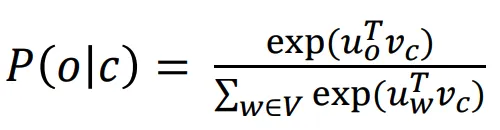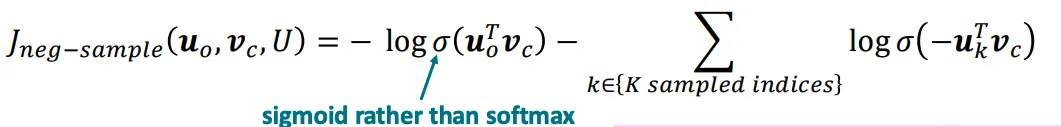cs224n学习笔记-Lecture 02:world vector(词向量)
skip-gram模型
wordvec有两个模型变体
1、Skip- gram(SG):给定中心词预测预测上下文词
2、CBOW:从上下文词袋中预测中心词
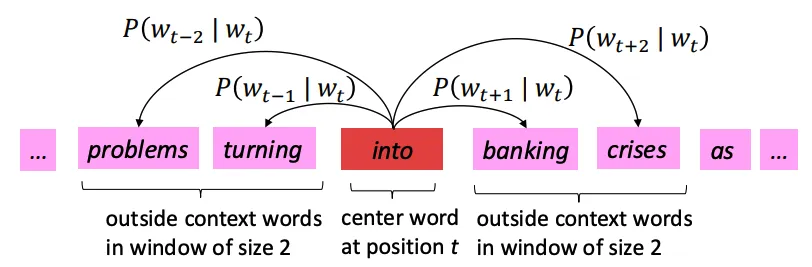
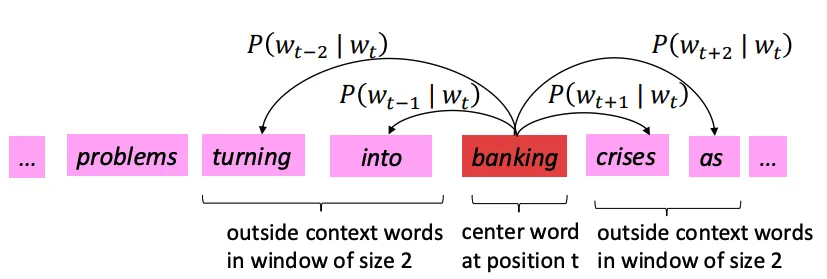
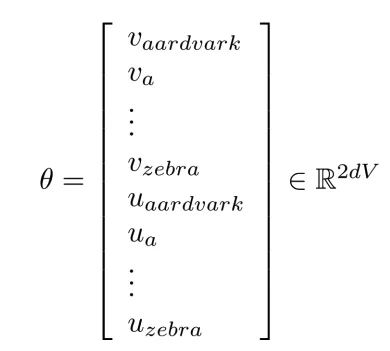
有一个很大的语料文本,构成一个很长的词列表,遍历每一个位置t,得到中心词c和上下位词o,使用词向量的相似度来计算给定中心词c的情况下出现上下文词o的概率,通过调整词向量使得概率最大化。对于每一个位置t = 1, 2, ..., T,给定中心词wt,预测在一个固定长度为m的窗内的上下文词,似然函数如下。上式的分子中的uo代表上下文词的向量,vc是中心词的词向量,uo和vc的点积的含义是计算上下文词和中心词的相似度。点积越大,P(o|c)概率越大。分子是用于归一化概率,将中心词c的词向量vc与词汇表中所有词的向量计算相似度然后求和。P(o|c)的计算和softmax函数计算比较相似,softmax的公式如下:theta代表所有的模型参数,每个词有两个词向量,作为中心词词向量(v)和作为上下文词词向量(u)。训练时,一个epoch中遍历一遍语料文本,计算损失函数和梯度,然后执行梯度下降,更新词向量(权重)。负采样的skip-gram模型
负采样skip-gram的原理
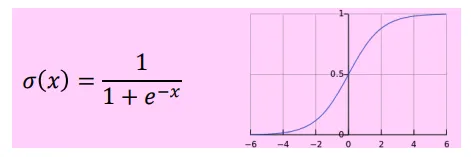
回顾一下“给定中心词计算上下文词的条件概率”公式:通常词汇表非常大(高达几十万),softmax类别非常多,P(o|c)的分母计算量极大。在标准的word2vec实现中使用的是负采样的skip-gram模型来解决这个问题。即通过训练二元逻辑回归分类器,来辨别‘正样本’(中心词及其上下文词)与多个‘负样本’(中心词与随机噪声词)。负采样的skip-gram在一次参数更新时,不再更新所有词,而只是更新:k是一个超参数,通常设置为5~20,对于低频词,k通常设置大一点(如15~20),因为需要更多样本教会模型这些词不常同时出现。对于高频词,k可以设置小一点(如5)。在word2vec原始论文中,作者发现直接使用词频分布效果不是最好,而是使用词谱进行3/4次方平滑处理。假设词wi在语料库中出现的次数为count(wi),总词数为Z。未平滑的词词频概率为P_original(wi) = count(wi)/Z。负采样使用的实际概率分布为P_neg(wi) = cout(wi)^(3/4)/Z如果不做处理(指数为 1),像 "the" 这样的词占比太高,导致负样本里全是 "the",模型学不到其他词的区分度。如果指数太小(比如 0,即均匀分布),高频词作为负样本出现的几率太低,模型无法有效降低中心词与高频词的共现概率,将中心词cat和the推开,也就是是cat,dog,idea经常和功能词the一起出现,在整个语料库中,如果使用均匀采样,负样本中出现the的概率相对而言很低,例如几十万分之一,负样本采样的词比较生僻,而模型是按照skip- gram学习的,会使得cat,dog,idea和功能词the有语义关联。3/4 次方 是一个经验上的“甜蜜点”(Sweet Spot)。它降低了最高频词的权重,同时提升了低频词被选为负样本的相对概率。损失函数使用sigmoid函数而不是softmax函数。负采样的skip- gram随机梯度下降
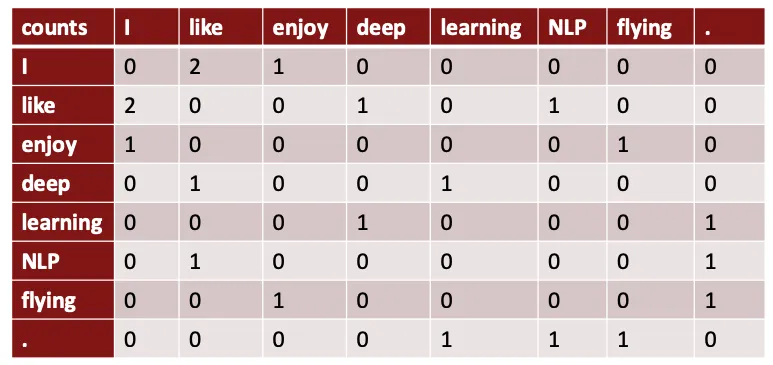
以迭代优化的方式,在每个上下文窗口为随机梯度下降求一次梯度,在每个窗口只有2m+1个词加上2km个负样本词,因此梯度矩阵是非常稀疏的。在做随机梯度下降时,只更新实际出现的词向量。使用稀疏矩阵操作来更新整个词向量矩阵U和V的特定行,并且维护词汇表词向量id哈希值集合。此外,这个哈希集合可以更好的完成负样本与中心词去重。如果有百万级的词向量做分布式计算,不能全部一起去更新词向量。负采样skip- gram模型是通过窗口迭代整个语料库多次,为什么不直接计算并统计什么词在什么词附近出现呢?构建共现向量也有两种方法:1)使用窗口,类似于word2vec,在每个词周围使用窗口,捕捉语法和语义信息(词空间);2)整个文档语料库的共现矩阵,导出潜在语义分析(文档空间)例如使用第一种方法,构建基于窗口的共现矩阵。窗口长度是1,对称的上下文。通过简单统计共同出现的向量,向量个数随着词汇表的增大而增多。解决方案:降维,使用低维向量。大多数的重要信息是固定的,使用稠密向量;通常25~1000维,类似word2vec。——————————————————————————注意:以下两节也是是lecture 02的中的主题,为了更好理解,部分参考了AI的回答。GloVe
GloVe (Global Vectors for Word Representation) 是一种经典的静态词嵌入(Static Word Embedding)技术,由斯坦福大学的研究团队于2014年提出。尽管目前以 BERT 为代表的动态上下文模型(Contextualized Embeddings)已成为主流,但 GloVe 因其训练效率高、在特定任务上表现稳定以及作为理解词向量演进的基石,依然在自然语言处理(NLP)领域占有一席之地。GloVe 的核心创新在于它结合了两种主流方法的优点:- 全局矩阵分解(Global Matrix Factorization):像 LSA (Latent Semantic Analysis) 那样利用全局统计信息。
- 局部上下文窗口(Local Context Window):像 Word2Vec 那样捕捉局部的语义关系。
GloVe 不直接预测上下文(如 Word2Vec 的 Skip-gram),而是构建一个巨大的词 - 词共现矩阵(Co-occurrence Matrix),统计单词在全局语料库中共同出现的次数。然后,它通过优化目标函数,学习出词向量,使得两个词向量的点积尽可能等于它们共现概率的对数。尽管 GloVe 很经典,但它有一个致命的弱点,这也是所有静态词嵌入的通病:- 无法处理一词多义(Polysemy):GloVe 为每个单词只生成一个固定的向量。例如,“Apple”在“吃苹果”和“苹果公司”这两个语境中,向量是完全一样的。
- 被动态模型取代:2018年以后,以 BERT、RoBERTa、GPT 为代表的预训练语言模型(PLMs)兴起。这些模型生成的向量是动态的(Contextualized),即同一个词在不同句子中会有不同的向量表示,从而完美解决了一词多义问题,并在绝大多数 NLP 任务上大幅超越了 GloVe。
如何评估词向量的质量
评估词向量(Word Embeddings)的质量通常分为两大类:内在评估(Intrinsic Evaluation)和外在评估(Extrinsic Evaluation)。- 内在评估:直接测试词向量本身的统计特性,通常速度快,用于调试模型。
- 外在评估:将词向量作为特征输入到具体的下游任务(如情感分析、命名实体识别)中,通过任务性能来评估,更能反映实际效果,但计算成本高。
内在评估 (Intrinsic Evaluation)
这类方法主要考察词向量是否捕捉到了语言学上的规律(如语义相似性、类比关系)。词相似度/相关性任务(Word Similarity/Relatedness)
原理:计算两个词向量的余弦相似度,并与人类标注的相似度分数进行对比(通常计算 Spearman 或 Pearson 相关系数)。指标:Spearman 秩相关系数(因为人类评分通常是序数)。A:B::C:? (例如:男人:女人 :: 国王:?)。计算方法:寻找向量 D ,使得 vec(D)≈vec(B)−vec(A)+vec(C) 。通常通过余弦相似度在词汇表中搜索最接近的词。原理:对词向量进行聚类(如 K-Means),然后评估聚类结果与已知词类(如 POS 词性、语义类别)的一致性。指标:纯度 (Purity)、归一化互信息 (NMI)、F1 值。外在评估 (Extrinsic Evaluation)这是评估词向量价值的“金标准”。将训练好的词向量作为初始化层或静态特征,投入到具体的 NLP 下游任务中,观察任务性能的提升。- 文本分类 (Text Classification): 如情感分析 (IMDB, SST-2)。
- 命名实体识别 (NER): 如 CoNLL-2003。
- 机器翻译 (Machine Translation)。
- 问答系统 (Question Answering)。
- 依存句法分析 (Dependency Parsing)。
- 结果受下游模型架构、超参数影响大,难以确定性能提升是源于词向量好还是模型调优好。
- 不同任务对词向量的需求不同(例如,NER 可能需要更多形态学信息,而情感分析需要更多语义信息)。
可视化评估 (Qualitative Evaluation)虽然不能给出量化分数,但对于直观理解词向量空间结构非常重要。t-SNE / PCA / UMAP:将高维词向量降维到 2D 或 3D 进行可视化。针对上下文相关词向量 (Contextualized Embeddings) 的评估
对于 BERT、RoBERTa、ELECTRA 等动态词向量,传统的“一个词一个向量”的评估方法(如直接查表做类比)不再完全适用,因为它们依赖于上下文。多义词评估:测试模型是否能区分同一词在不同语境下的含义(例如 "bank" 在 "river bank" 和 "bank account" 中的向量应不同)。https://web.stanford.edu/class/cs224n/slides_w26/cs224n-2026-lecture02-wordvecs.pdf