昨天我参加了公司的培训——英伟达深度学习培训中心(DLI)的《构建大语言模型 RAG 智能体》课程。非常建议大家用半天到一天的时间,跟着过一遍,能够加深对于智能体系统、rag系统、langchain、模型评估这些前沿的AI概念的理解。
什么是 RAG 智能体?
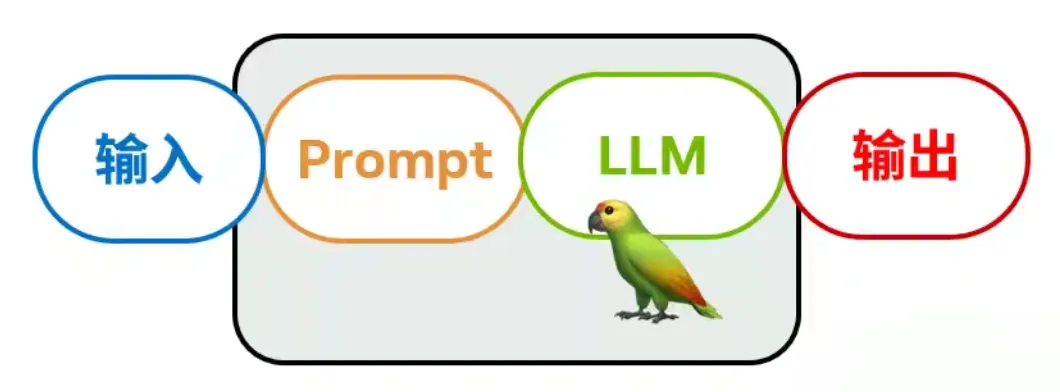
具备对话与检索能力的 RAG 智能体,是一种能结合丰富上下文信息、生成更符合我们期望回答的 AI。
之所以需要这种智能体,是因为单纯的大模型问答模式已经无法满足我们对准确率的要求。原因在于,模型的训练数据通常具有滞后性,无法囊括我们当前对话的最新场景或私有数据。
新的解决方案就是 RAG(检索增强生成)。它在大模型生成回答之前,会先通过语义搜索去寻找最匹配的上下文。这里引申出一个更深度的问题:为什么现在像 Claude Code 等应用,在处理代码库时更倾向于使用 Grep 等传统搜索,而不是 RAG?这是一个值得思考的设计考量。
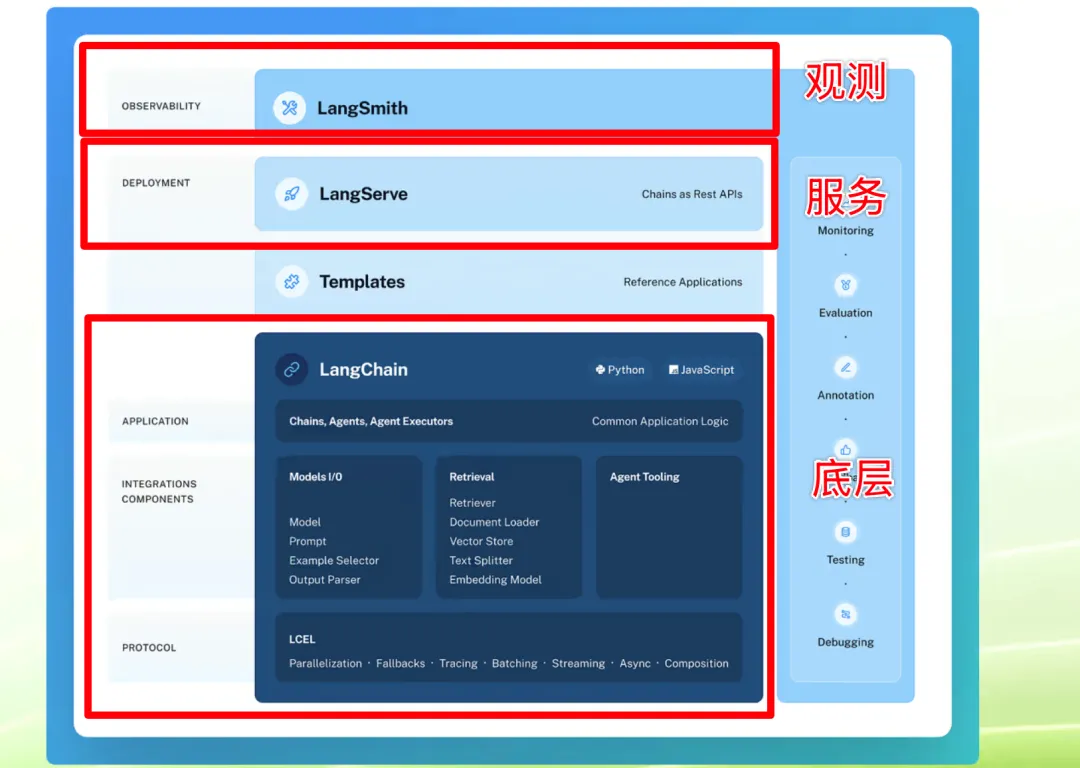
另一个重要的背景知识是 LangChain。作为一个开源的软件库,它是帮助我们开发大模型应用的强大框架,内部集成了模型对话、数据管道等搭建各类工具所需的元素。
💡 注:本次课程中,所有的大模型微服务均基于英伟达的 NIM 微服务提供。
开发环境与基础组件
课程配套的实验环境是 Jupyter Lab。相信使用过各类云服务的朋友对它已经很熟悉了,它运行在一个线上的虚拟容器中。类似的环境也可以在本地通过 python -m jupyter notebook --port 8888 启动,或者直接使用 Google Colab。
使用容器是为了在云端更好地分配资源(包括算力、数据等)。这里抛出一个疑问:所谓的 Nginx 代理,究竟是应该单独启动一个容器去对接其他容器,还是直接在原有的服务开发环境中进行配置更好呢?
下一个组件是 Gradio。它是一个构建网页端 UI 的服务框架,优势在于可以轻松部署到 Hugging Face 或 Vercel 等云平台上,将自己的应用开放给更多人使用。你可以把它理解为传统意义上的“前端”。
💡 一些 Docker 技巧:
在主机环境中,我们可以通过类似 docker_router 的服务打开一个连通外部环境的端口。创建该服务的具体代码可以在 docker_router/docker_router.py 和 docker_router/Dockerfile 中查看,里面定义了一个可调用的 help 命令。下面是一个通过 Shell 进行网络查询的示例,它能直接调用该 help 例程。
底层服务架构与网关
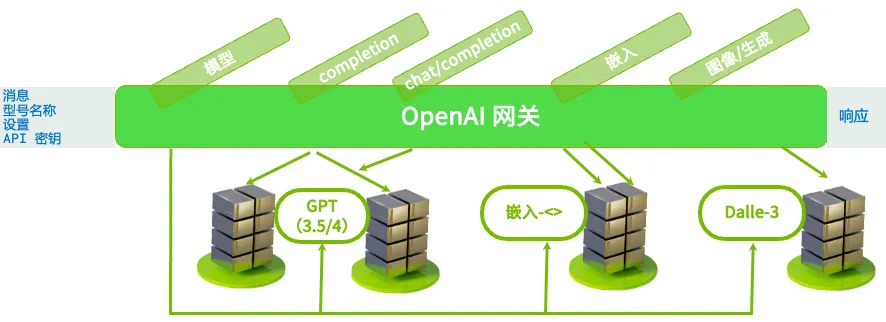
因为课程是英伟达主办的,所以也深入讲解了大模型底层服务的部署逻辑。整体架构大致可分为三层:算力层、中间层和用户层。
中间层(比如 OpenAI 兼容网关)存在的意义,就是将“模型具体部署在哪个算力节点”以及“算力如何分配”等底层细节对用户层屏蔽。用户只需发送需求,完全不需要操心底层算力的调度。
具体来说,网关向上会验证请求是否符合规范、API 密钥是否正确等;向下则负责路由,决定分配哪个模型、调用哪块算力,以及向哪台服务器发起请求。
接入大模型 API
接下来,我们将尝试接入英伟达提供的大模型环境,为后续搭建应用打下基础。具体来说,课程在本地启动了一个客户端服务,这是英伟达专门为教学封装好的。API 密钥和底层链接已经被妥善隐藏,方便大家直接调用。
import requestsinvoke_url = "http://llm_client:9000"headers = {"content-type": "application/json"}requests.get(invoke_url, headers=headers, stream=False).json()# 返回结果示例:# {'/health': '健康检查端点以验证服务运行。',# '/hello': '回应一个简单的问候语,对初次测试很有用。',# '/': '列出所有可用端点及其描述。',# '/set_keys': '更新应用程序的 API 密钥',# '/revert': '将 API 密钥恢复为初始状态',# '/v1/models/{model:path}': '返回可用模型(或单个模型)的列表',# '/v1/models': '返回可用型号的列表',# '/v1/{path:path}': '根据路径将请求转发到相应的 OpenAPI 端点。'}
通过发送请求,我们可以看到它内部署了 DeepSeek、Qwen、英伟达自己的 Llama、BGE 等各种各样的模型。
import requestsinvoke_url = "http://llm_client:9000/v1/models"# invoke_url = "[https://api.openai.com/v1/models](https://api.openai.com/v1/models)"# invoke_url = "[https://integrate.api.nvidia.com/v1](https://integrate.api.nvidia.com/v1)"# invoke_url = "http://llm_client:9000/v1/models/mistralai/mixtral-8x7b-instruct-v0.1"# invoke_url = "http://llm_client:9000/v1/models/mistralaimixtral-8x7b-instruct-v0.1"headers = { "content-type": "application/json", # "Authorization": f"Bearer {os.environ.get('NVIDIA_API_KEY')}", # "Authorization": f"Bearer {os.environ.get('OPENAI_API_KEY')}",}print("Available Models:")response = requests.get(invoke_url, headers=headers, stream=False)for model_entry in response.json().get("data", []): print(" -", model_entry.get("id"))print("\nExample Entry:")invoke_url = "http://llm_client:9000/v1/models/mistralai/mixtral-8x7b-instruct-v0.1"requests.get(invoke_url, headers=headers, stream=False).json()
作为示例,课程提供了一段原生的流式对话(Streaming)请求代码。当然,后续我们会使用 LangChain 等高级框架,所以在实际开发中不需要手写如此底层的请求处理,这里仅作展示。
import requestsimport json## Use requests.post to send the header (streaming meta-info) the payload to the endpoint## Make sure streaming is enabled, and expect the response to have an iter_lines response.response = requests.post(invoke_url, headers=headers, json=payload, stream=True)## If your response is an error message, this will raise an exception in Pythontry: response.raise_for_status() except Exception as e: print(response.json()) raise edef get_stream_token(entry: bytes): """提取字节流中的增量内容""" if not entry: return "" entry = entry.decode('utf-8') if entry.startswith('data: '): try: entry = json.loads(entry[5:]) except ValueError: return "" return entry.get('choices', [{}])[0].get('delta', {}).get('content')for line in response.iter_lines(): print(get_stream_token(line), end="")
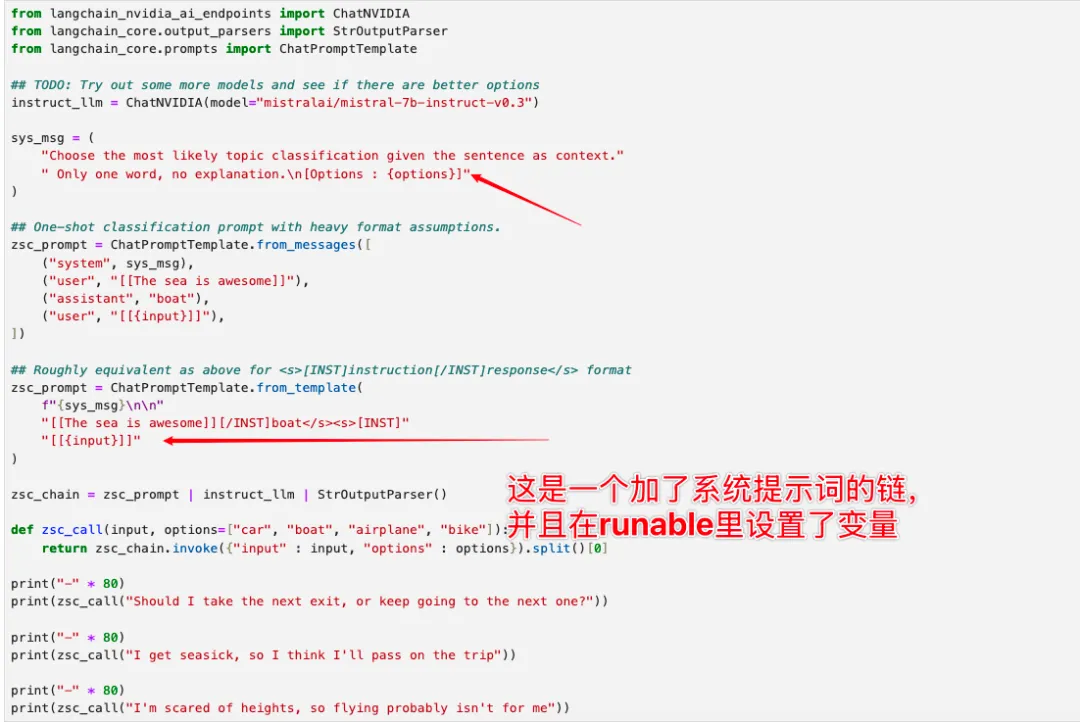
LangChain 登场:简化调用流程
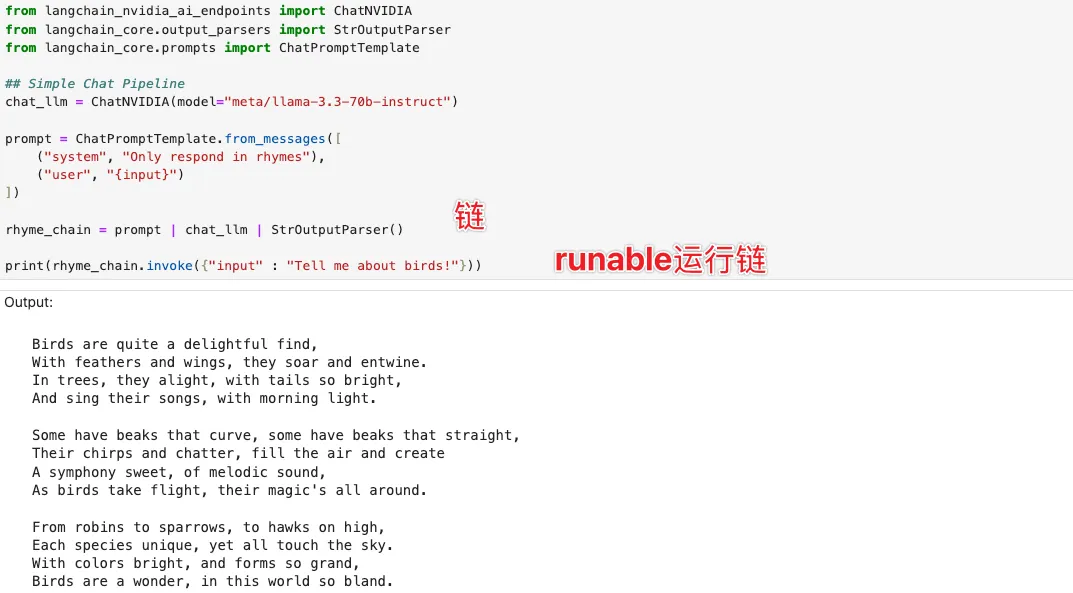
接下来,我们看看如何使用 LangChain 配合 langchain_nvidia_ai_endpoints 专属组件,来极大地简化大模型的调用。
## Using ChatNVIDIAfrom langchain_nvidia_ai_endpoints import ChatNVIDIA## NVIDIA_API_KEY pulled from environmentllm = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1")# llm = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1", mode="open", base_url="http://llm_client:9000/v1")llm.invoke("Hello World")# 这里收到的回复是大模型的回复以及一些要回复的配套信息。llm._client.last_inputs# 这里可以看到回复是上一次的请求是怎么来的,发生了什么query。llm._client.last_response.json()# 这里是有一次把上一次的回复有哪些信息回复了什么内容进行回复的具体的和原始数据进行一个配套的展示。
核心概念:Runnable 与链式结构
LangChain 的核心设计思路就是“构建链(Chain)”:将输入、提示词构建、模型调用到最终输出解析,全部串联成一条工作流。
它的核心接口是 Runnable,这是各个组件之间统一的对接协议。
调用 invoke 方法就代表执行这条链。因此,整体开发流程就是:先用各类组件组装链条,然后执行它。链条里包含各种组件:比如生成提示词的组件、对话模型组件、将回复反序列化成对象的组件等。
除了 invoke,另一种常见的执行方式是流式输出 stream。两者的区别仅在于返回数据的方式不同:一个是全部生成完一次性返回,另一个是逐字生成返回,但底层的执行本质是一致的。
再往上层走,LangServe 可以将我们构建好的链直接包装成 API 服务;LangSmith 系统则能帮助我们监控、追踪整个调用链路。
接下来我们看一看具体的代码:
掌握了简单的调用后,我们可以用一些更复杂的事例看一看。
组件之间的衔接润滑剂
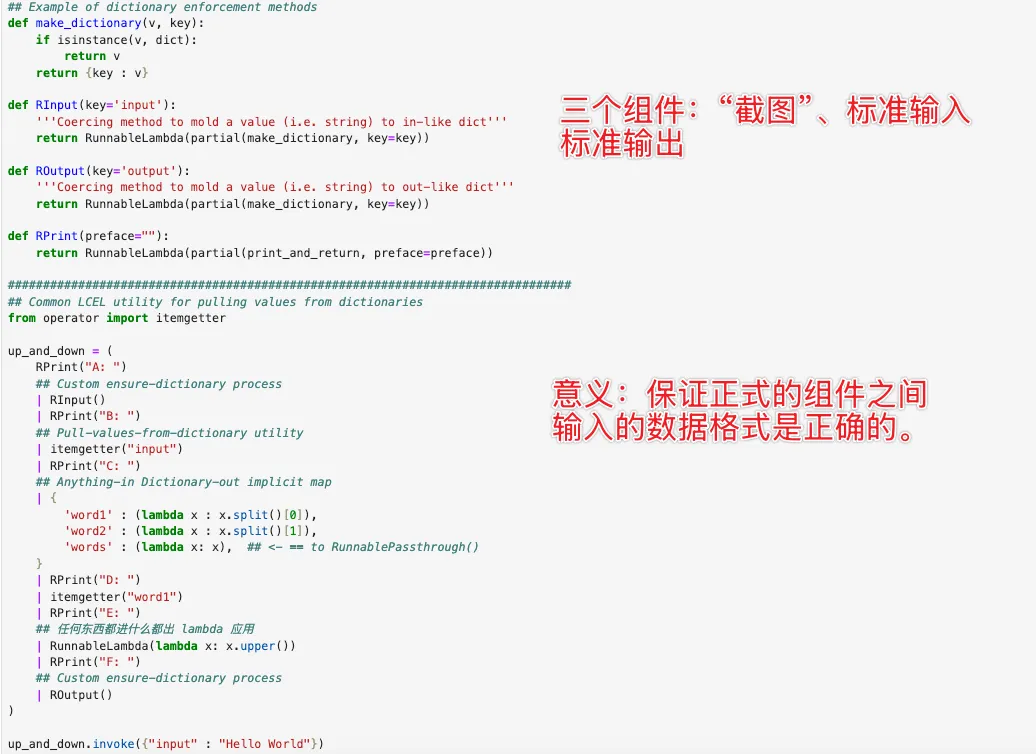
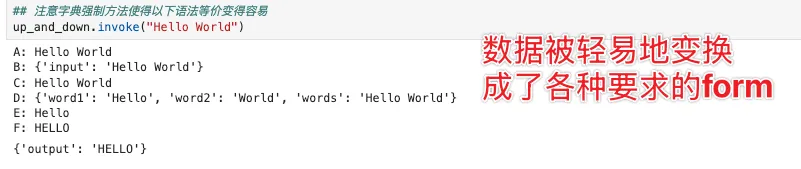
状态链(State Chain)的意义在于引入了历史记忆和上下文。LangChain 的设计哲学是让一切保持“链”的完整性,而不是打断链条去外部声明变量。它的解决方案是对当前状态进行快照传递。
这里核心用到的是 RunnableAssign。它的特点是只会向当前状态字典中追加或更新数据,绝对不会破坏或删除已有流程。(打个比方,放在 n8n 的语境下,这就类似于流转中的全局上下文变量)。
具体代码拆解如下:
再给一种 Python 编程角度的抽象理解:我们可以抽象地将运行状态链看作 Python 类的变体,其中包含状态变量(或者说属性)和函数(或者说方法)。
- 运行状态:类似于类的属性(始终可被访问)。
- 分支节点:类似于类的方法(可以选择要用的属性),它们的返回值可以通过
assign 更新,也可以返回给用户。 .invoke() 或类似的方法就像是按顺序触发内部的 __call__ 方法。
此外,还有:
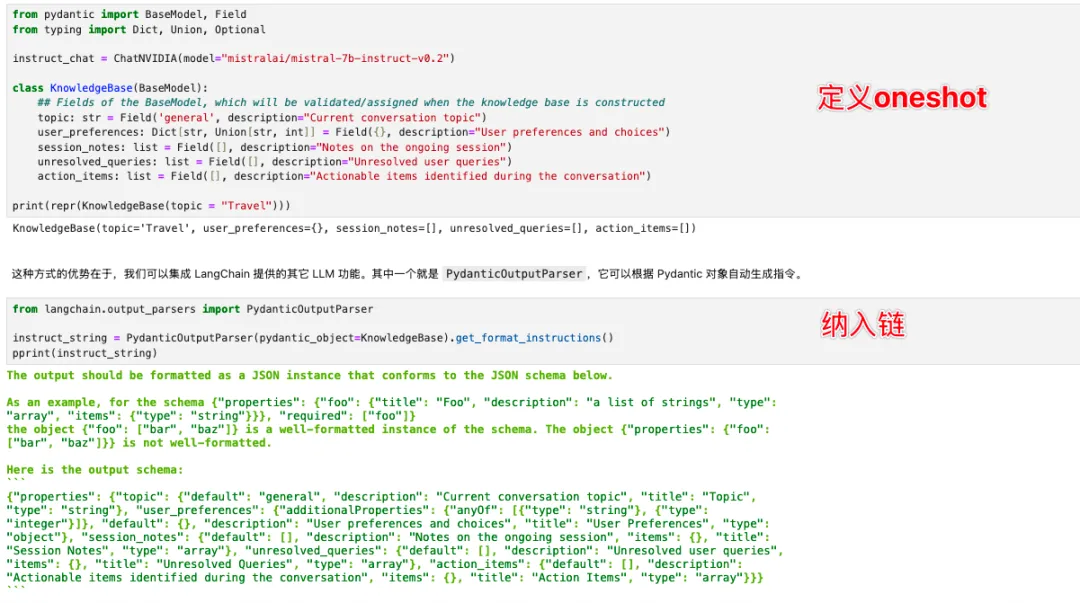
RunnableLambda:自造组件,引入自定义函数。PydanticOutputParser:用于规范大模型输出格式(如 JSON),不仅能做 One-shot 示例,还能进行强类型验证。
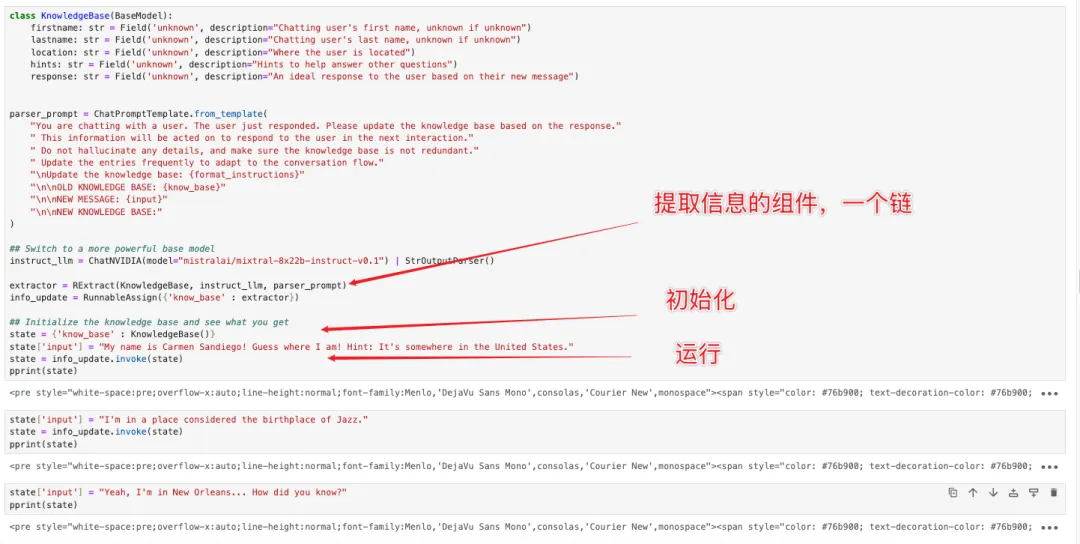
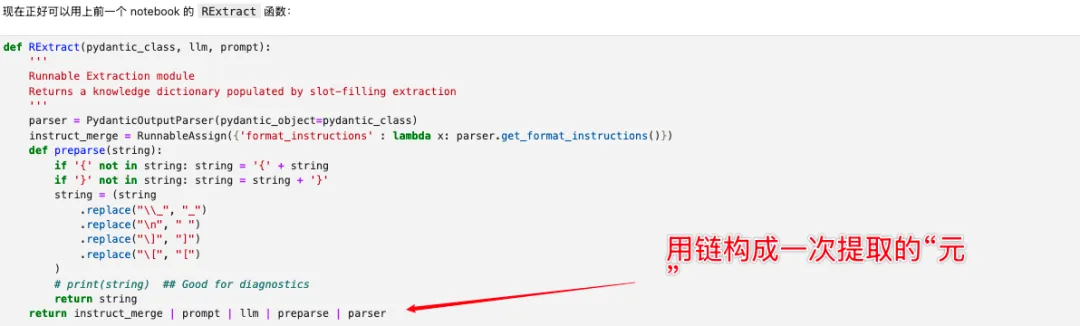
提取 Pydantic 信息的组件:
结合以上组件,我们就能做成一个更新知识库的全套流程。
接下来展示一个整体的聊天机器人是如何做出来的,我们跳过引入各种库和初始的提示词设置:
构造 RAG 智能体:文档处理
我们离构造智能体更进一步了。接下来就是构造 RAG 智能体的另一个重要组件,处理文档。
LangChain 提供了丰富的 Document Loaders(文档加载器)来读取文本:
随后用内置的分块方法把长文本拆分:
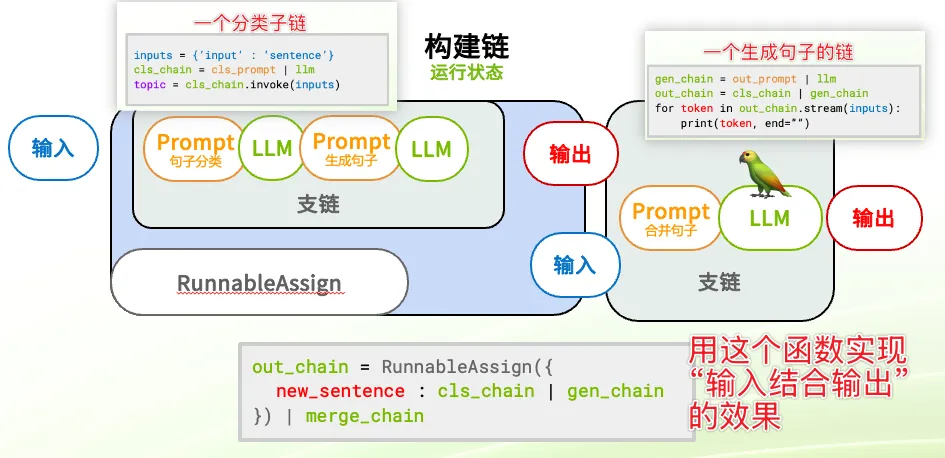
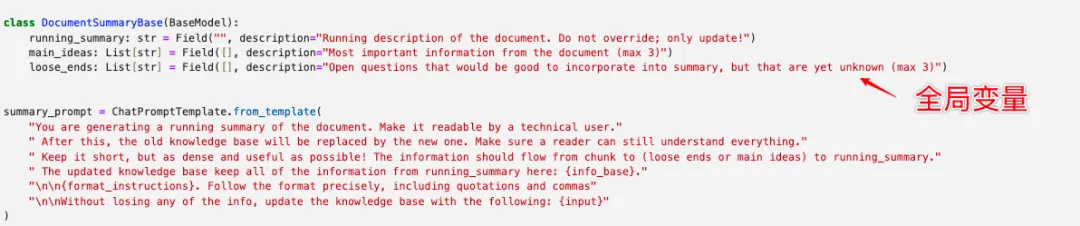
结合前面的知识,课程带着我们实践了一个“长论文循环总结智能体”。
整体来看这个文档总结智能体(整个逻辑稍微有点太绕了,我把难理解的点在图里标清楚了):
我最初有个疑惑:循环总结时,每次输入给模型的是第 个数据块,还是前 个数据块?
仔细思考后明白了:是前个块的累加。这其实是在模仿人类的阅读习惯,此循环会获取更多的段信息,也会对整份文件有更深刻的理解。
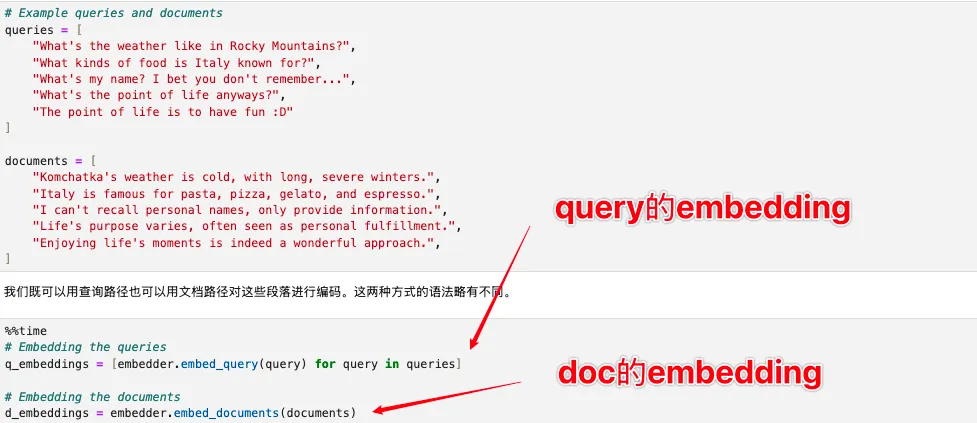
Embedding 向量化
LangChain 也集成了多种 Embedding 方法。
下面是针对用户问题和文档的两种嵌入的方法,本质是相似的,但是用的场景有些区分,一个是对用户的提问,一个是用户的文档。
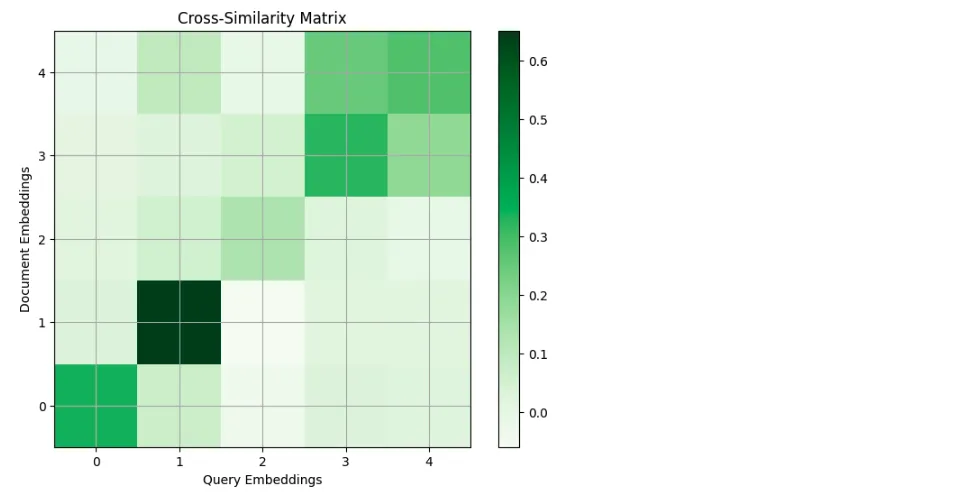
嵌入之后的变量就是一些数组,所以就可以对它们的相似图进行检查,画出一个很好看的相似度矩阵。
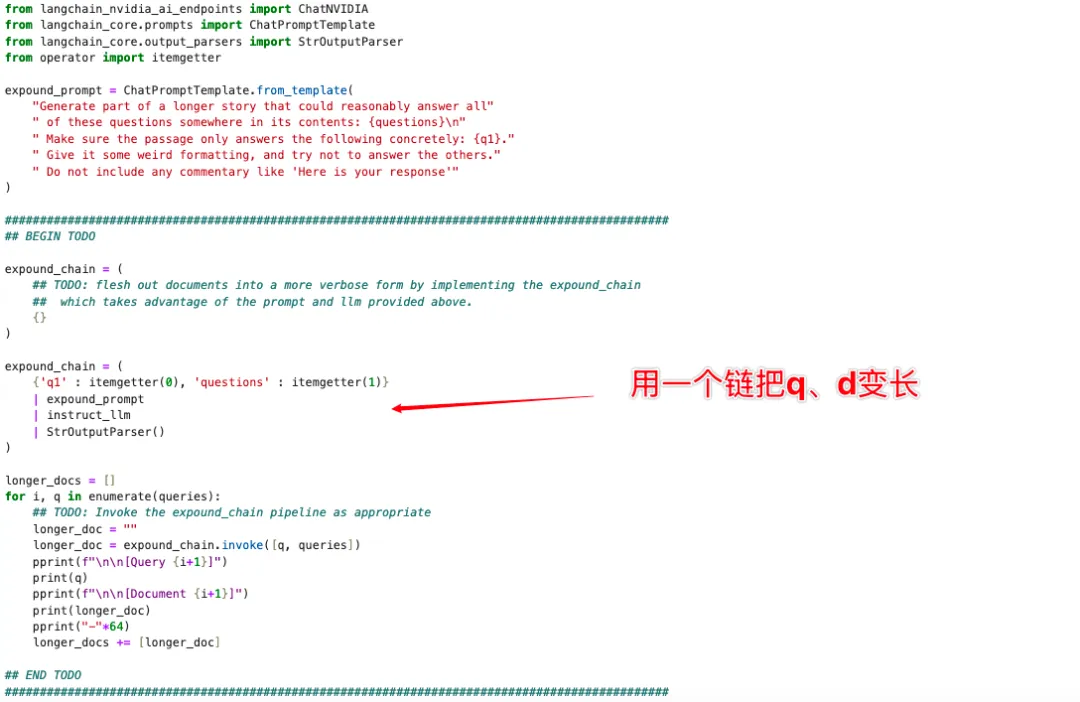
接下来再做另一个实验,我们先把文档变长:
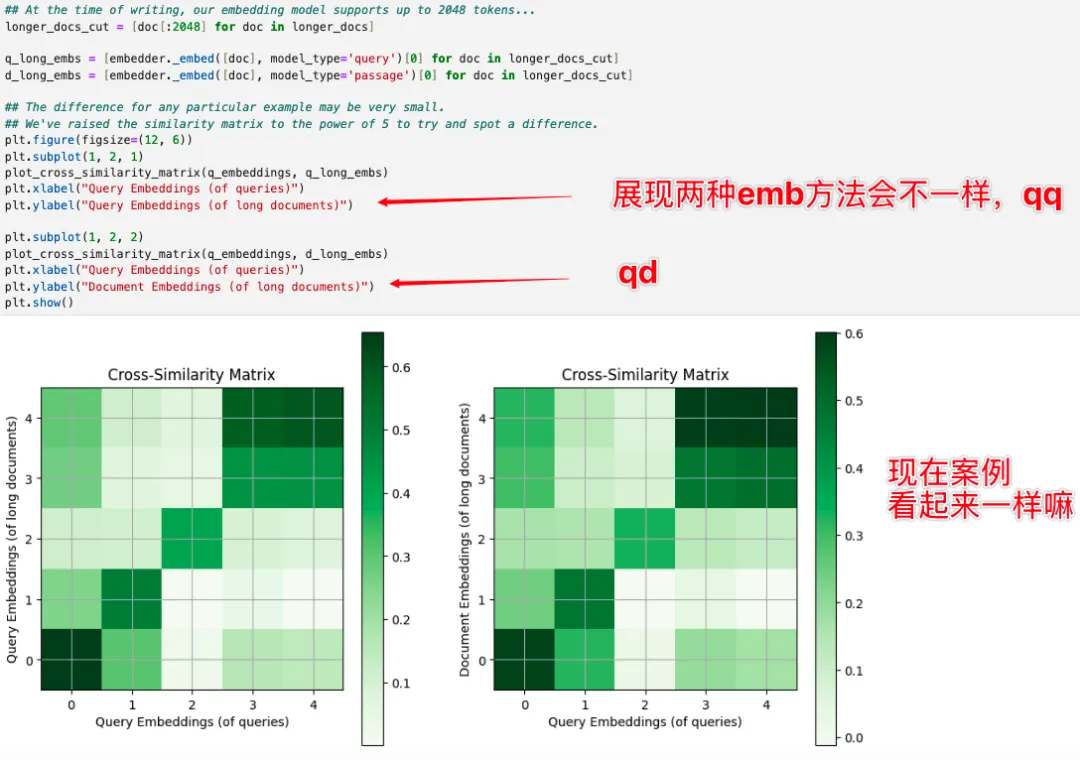
变长了以后,在后续测试长文档的实验中,课程旨在展示不同的嵌入策略会造成不同的语义相关性。
(不过说实话,目前从当前的这个长度和当前的这个嵌入模型里面看不出来这个效果差异,哈哈)。
向量数据库与实战演练
快速的搭完了嵌入模型的实验之后,我们就正式进入 RAG 智能体的搭建吧。
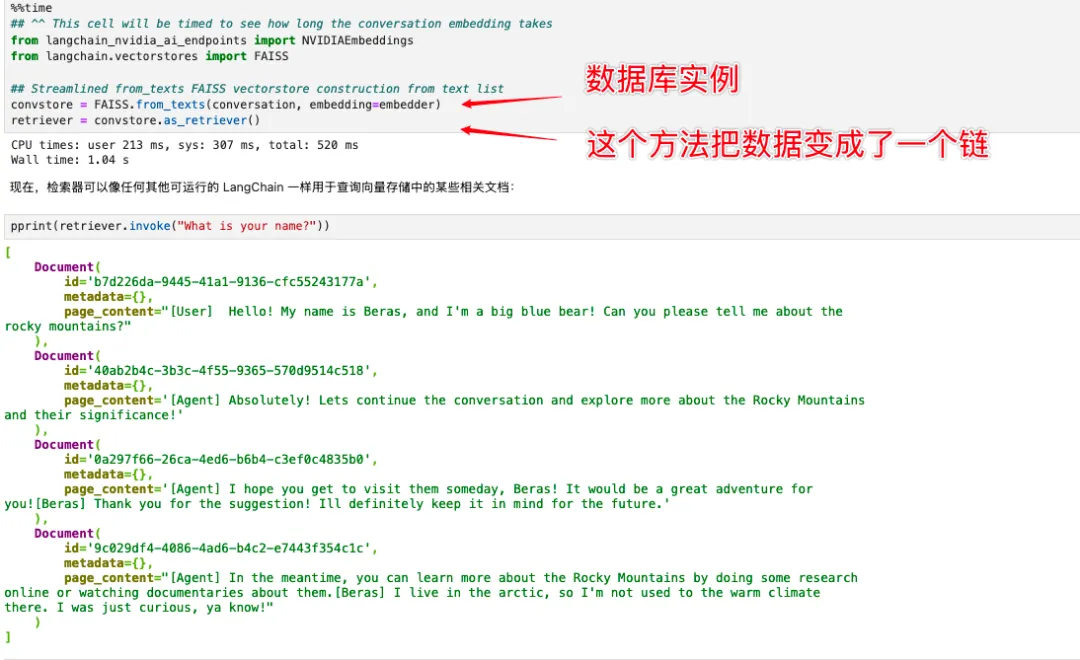
第一个最基础的 RAG,其知识库仅仅利用了一段历史对话。
Langchain 自带了一些向量数据库用来存文档数据,并且可以把向量数据库集成进链。我们将文本存入 FAISS 等向量数据库,并将其转化为 Retriever 接入到链中。
接下来就可以搭建一个知识库的简单使用了,具体如下图:
另外一个向量数据库里的重要操作是继续增加新的数据。以下面这个方法为例,就是把用户和 Agent 的每一轮新对话实时记录进向量数据库里面。
实战测试:
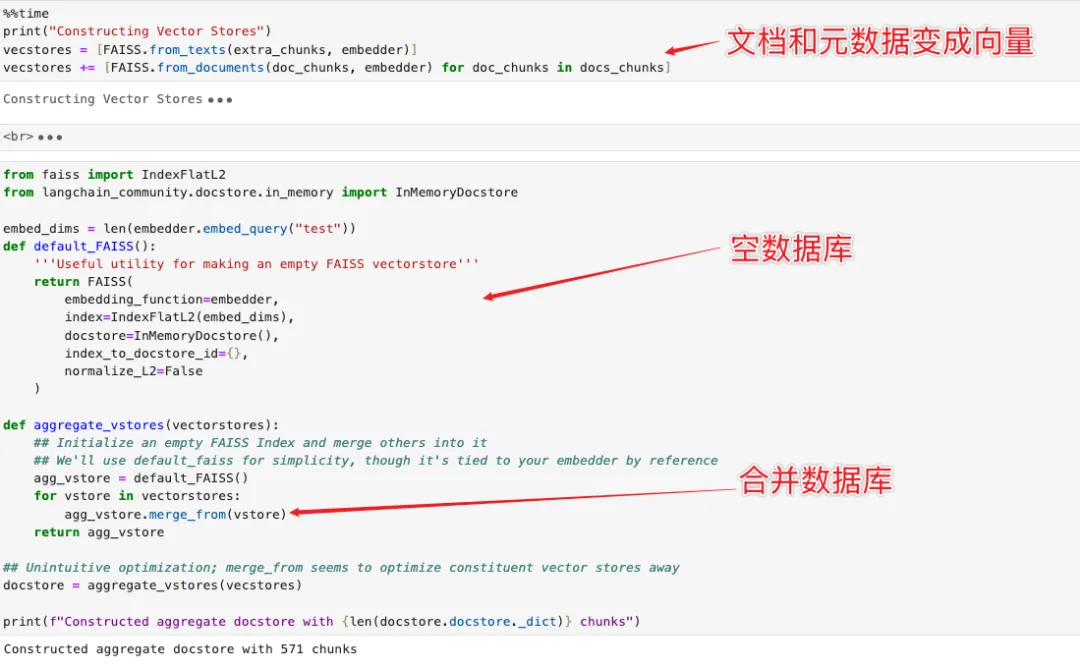
接下来就是一个真正的实战部分,把一些真实论文集成到向量数据库里头,然后对一些知识进行提问,看看他能不能从这个向量数据库里头获得正确的知识。
- 首先利用前面的代码对文档进行加载并分块,变成一系列分块后的文档列表:
上面两个 Chunk 分别是:docs_chunks(文档的具体文本内容块(细粒度)、具体段落)+ extra_chunks(文档的全局元信息(粗粒度)、文档清单)。
⚠️ 思考:当然到目前为止,敏锐的朋友可能注意到了,他这个构建的向量库有一个全局信息丢失的风险在,不知道大家有没有发现。
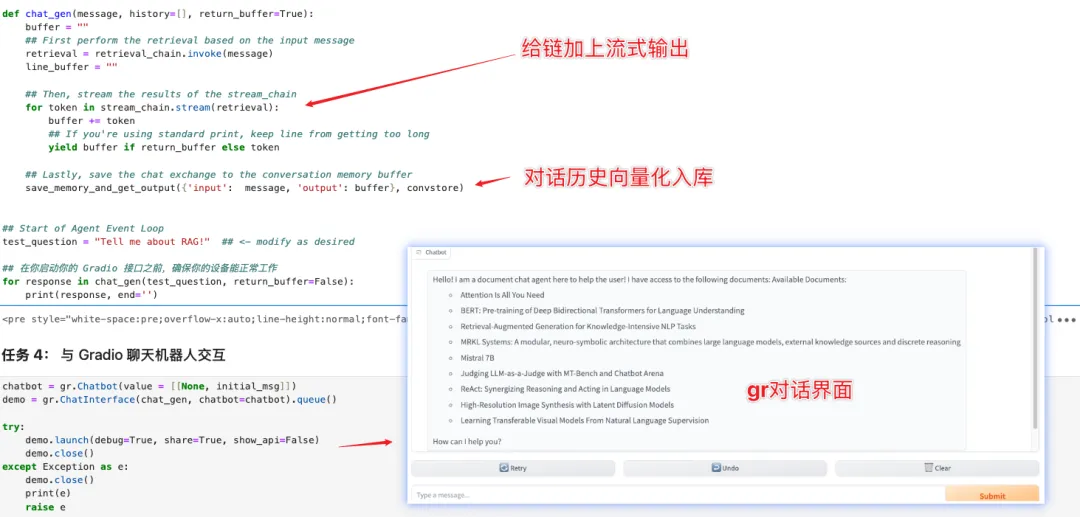
- 最后就是把它变漂亮一点,变成一个对话的 Web 界面:
当然,大模型应用的另一个关键的组成是记录和评估,所以我们一定要把对话历史记录下来:
大模型效果评估 (Evaluation)
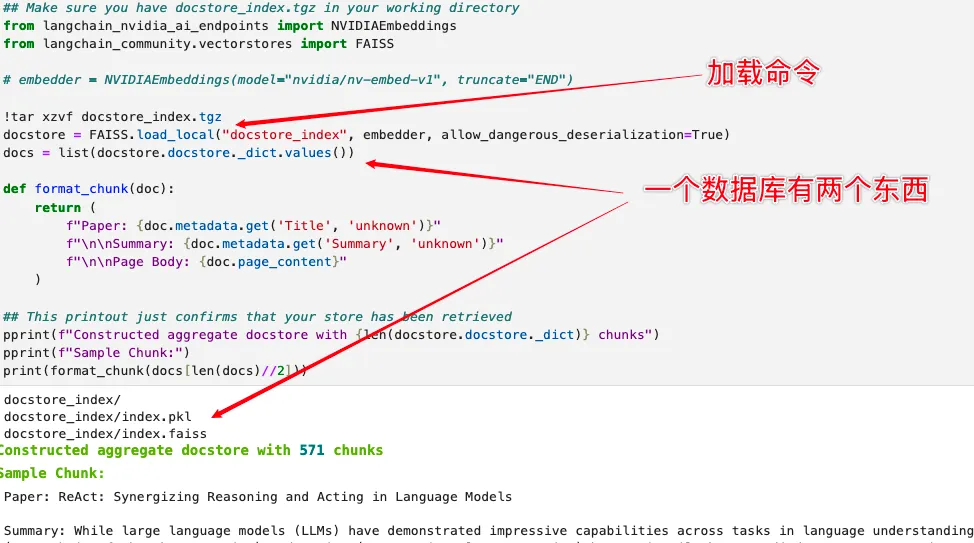
开发 RAG 系统的最后一环是评估。首先,加载跑好保存的信息和数据库:
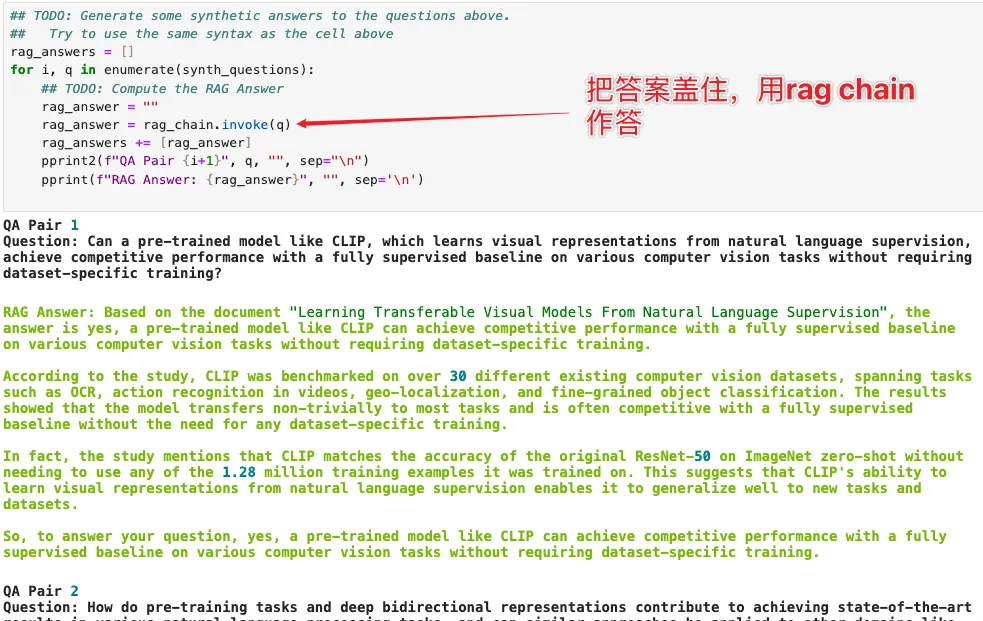
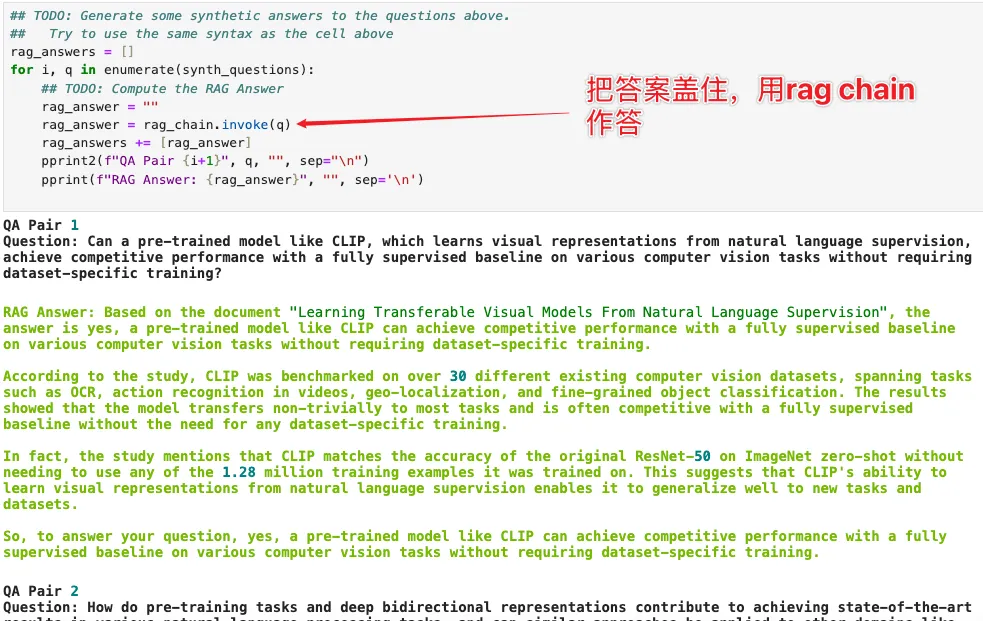
然后我们随机采样几个文本模块,利用模型反向生成一批 Benchmark 问答对。生成这类问答对的核心目的,正是为了测评向量数据库(RAG 系统)的效果——验证向量库能不能精准返回 “能回答问题的优质文本块”,并且用这些切块回答,理论上(也应该)比直接用整篇文档回答更优。
接下来用 RAG Chain 进行作答,如图:
接下来引入第三个强大的大模型(LLM-as-a-Judge 裁判模型)作为正确答案的基准,和 RAG 作答的结果进行评估,并且按照我们要求进行打分:
十分尴尬,目前这个系统得到了零分的好成绩。
总之这个评分的思路就是如此了。这个 0 分的来源是我在本地运行了多遍数据库,新的数据没有覆盖旧的,导致检索库非常混乱。这让基准评分的答案对于当前 Notebook 的 RAG 智能体来说,难度超纲了。
附:极简 RAG 智能体服务源码
最后提供一个基于 FastAPI 的极简 RAG 智能体实现源代码:
# server_app.pyfrom fastapi import FastAPIfrom langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddingsfrom langserve import add_routesfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_community.vectorstores import FAISS# 1. 初始化模型embedder = NVIDIAEmbeddings(model="nvidia/nv-embed-v1", truncate="END")instruct_llm = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",)# 2. 基础聊天入口add_routes( app, instruct_llm, path="/basic_chat",)# ==========================================# 3. ASSESSMENT TODO: 实现 RAG 组件# ==========================================# 加载之前保存的本地向量数据库作为检索器docstore = FAISS.load_local("docstore_index", embedder, allow_dangerous_deserialization=True)retriever = docstore.as_retriever()# 构建生成器链chat_prompt = ChatPromptTemplate.from_template( "You are a document chatbot. Help the user as they ask questions about documents." " User messaged just asked you a question: {input}\n\n" " The following information may be useful for your response: " " Document Retrieval:\n{context}\n\n" " (Answer only from retrieval. Only cite sources that are used. Make your response conversational)" "\n\nUser Question: {input}")generator_chain = chat_prompt | instruct_llm | StrOutputParser()# 将生成器绑定到 /generatoradd_routes( app, generator_chain, path="/generator",)# 将检索器绑定到 /retrieveradd_routes( app, retriever, path="/retriever",)# ==========================================if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=9012)
所有源码可以关注+后台私信获取,一对一包教包会服务可以私信聊~
在文章的最后,想给大家强烈推荐一个我平时部署项目经常用的神器——Zeabur。
不管你是想快速上线一个前端全栈网页、部署小程序后台,还是跑一些大模型相关的 AI 应用(OpenClaw、n8n),Zeabur 都能帮你省去折腾服务器环境的麻烦,真正做到极简部署,让你把时间花在写代码本身上。
如果你刚好需要部署自己的项目,或者准备购买他们家的服务器和 AI Hub 额度,结账的时候一定要记得填我的专属推荐码:xiaomukuaier (小木块儿的全拼)。
用我的推荐码,你可以直接享受 10% 的专属折扣,省下一笔钱;同时你也是在支持我的公众号,让我能有一点点佣金收益,继续给大家产出更多硬核的技术内容。这波绝对是双赢!
注册链接和推荐码如下。赶紧去试试吧,部署代码从未如此简单!感谢大家的三连支持,我们下篇文章见!
🚀 极简代码部署平台 Zeabur:https://zeabur.com/zh-CN/templates
💰 结账输入推荐码 xiaomukuaier 立享折扣!