这篇文章内容较长,没耐心可以直接将图作为主线阅读。
核心内容:以工程链视角的思路来分析精度在AI算力工程的演进,将 FP32 → FP16 → FP8 → INT8 作为工程链,发现一条非常清晰的工程因果。带着这样的目标来思考和整理。了解清楚后给企业级用户做算力选型有帮助。
第一部分|事实与知识整理
一、为什么必须分清楚“精度”的语义
经常看到文章、交流中碰到精度这个词,“精度”是一个高频词,却往往也是一个“黑盒”。
客户常问:
“用 FP8 会不会让模型变傻?”
“为什么训练要用 BF16 而不是 FP16?”
要INT8推理精度。
很多时候,技术人员用公式解释,业务人员听天书;销售人员用比喻,技术人员觉得不专业。几乎所有关于精度的混乱,都源自一个根本问题:
语义层级没有被区分。
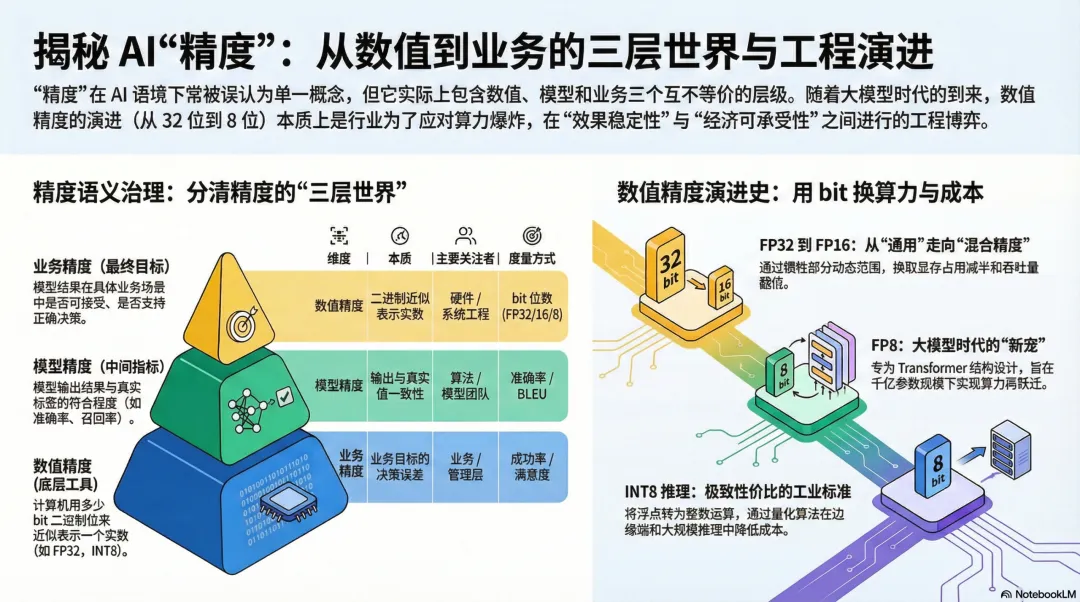
数值精度
指计算系统用有限 bit 表示和计算连续数值时的误差控制能力。
模型精度
指模型输出结果与真实标签或统计规律之间的符合程度。
业务精度
指模型结果在具体业务场景中是否可接受、是否支持正确决策。
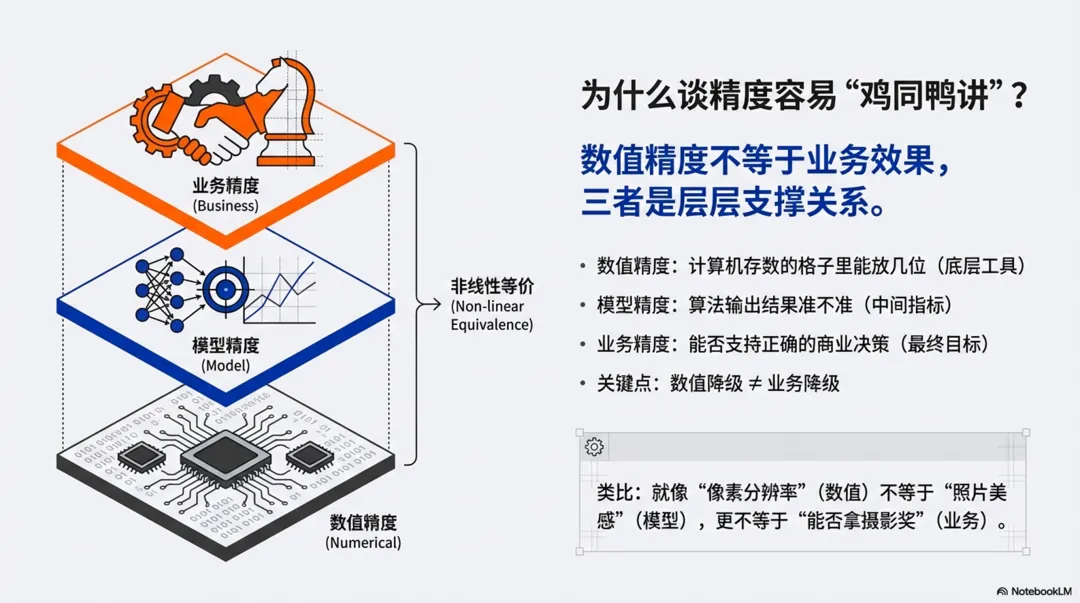
这三个概念并不矛盾,但彼此不等价。精度这个词之所以让人困惑,是因为它在不同语境下指向三个完全不同的概念层面,而大部分人只知其一不知其二。
二、精度不是一个概念,而是数值、模型、业务的三层世界
尝试用自己了解到的理解给出一个归类。
| | | |
|---|
| | | |
| bit 位数(FP32、FP16、BF16、FP8、INT8)、误差范围 | | |
| | | |
| | | |
| | | |
这三者互相关联,但绝非等价。数值精度是底层工具,模型精度是中间指标,业务精度是最终目标。 忽略任何一层,都会导致沟通错位。
三、数值精度的工程演进事实:从 FP32 到 FP16,并非 AI 的选择
可以把“FP32 → FP16 → FP8 → INT8”看成一条很清晰的工程演进链:算力需求爆炸、硬件资源有限,行业就一层层把“数字表示得没那么精细”,换来更多吞吐和更低成本,同时用算法把损失兜住。
3.1、FP32:数值计算的“黄金时代起点”
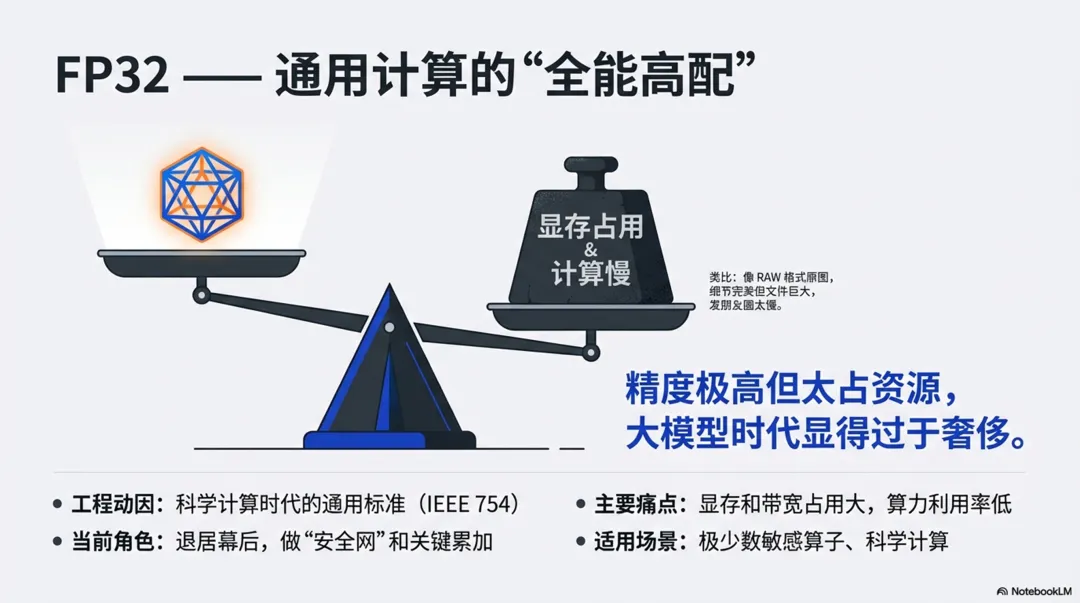
1)工程动因:为通用数值计算定一个“够用又统一”的标准
FP32来自 IEEE 754 标准,它不是为 AI 设计,而是为所有通用数值计算设计的:
科学计算、图形渲染、信号处理等都需要“既有足够精度,又有足够动态范围”的通用格式,FP32 就成了折中选择。
它的工程目标很简单:“绝大多数程序员用一个统一的浮点类型,既不需要 FP64 那么贵,也比定点好用。”
2)AI 出现之前的价值:HPC + 图形 + 通用软件的基石
在深度学习之前,FP32 已经是:
- 高性能计算(HPC)的主力格式:数值模拟、天气预报、计算流体力学等大量用 FP32/FP64 混合。
- GPU 图形渲染的主角:顶点坐标、纹理坐标、大量 Shader 计算都用 FP32。
- 通用软件中“默认的浮点类型”:C/C++ 里的 float、 信号处理库默认也是 FP32。
对 GPU 厂商来说,FP32 是“必须做好”的:做不好 FP32,整个 HPC 和图形市场都不要你。
3)AI 规模化后,哪里开始“不够用”了?
深度学习兴起后,问题变了:模型参数从百万级 → 亿级 → 千亿级;训练数据从 GB → TB → PB;单次训练要跑几天到几周。
在这个规模下,FP32 主要暴露了两个矛盾:
显存和带宽不够用:同一块 GPU,如果权重和激活都用 FP32,占用是 FP16 的两倍,直接限制了模型大小、batch size,也限制了吞吐。
算力利用率不够高:硬件上,FP32 乘加单元面积比 16/8 位大很多,同样面积能做的 FP32 MAC 数量远少于低精度。对深度学习这种“矩阵乘爆炸多”的负载,FP32 让 GPU 的“每瓦 FLOPS”不够好看。
简单说:
在“小模型时代”FP32 很舒服,到了“后来大家都堆大模型”的时代,它太浪费了。
4)业界怎么迁移:从“全 FP32”到“FP32 + 低精度混合”
迁移不是一夜之间发生,而是几个阶段:
早期深度学习:几乎都是纯 FP32 训练和推理。
中期:GPU 开始加入半精度能力,但大家还在探索数值稳定性,训练时多是“试验性”使用。
现在:FP32 基本只剩下三个角色:权重、累加、少数极其敏感的算子/归一化
主流训练/推理路径,都在往 FP16/FP8/INT8 迁移。
FP32 从“主角”变成了“安全网”和“控制枢纽”。
3.2、FP16:第一次大规模“降精度换算力”
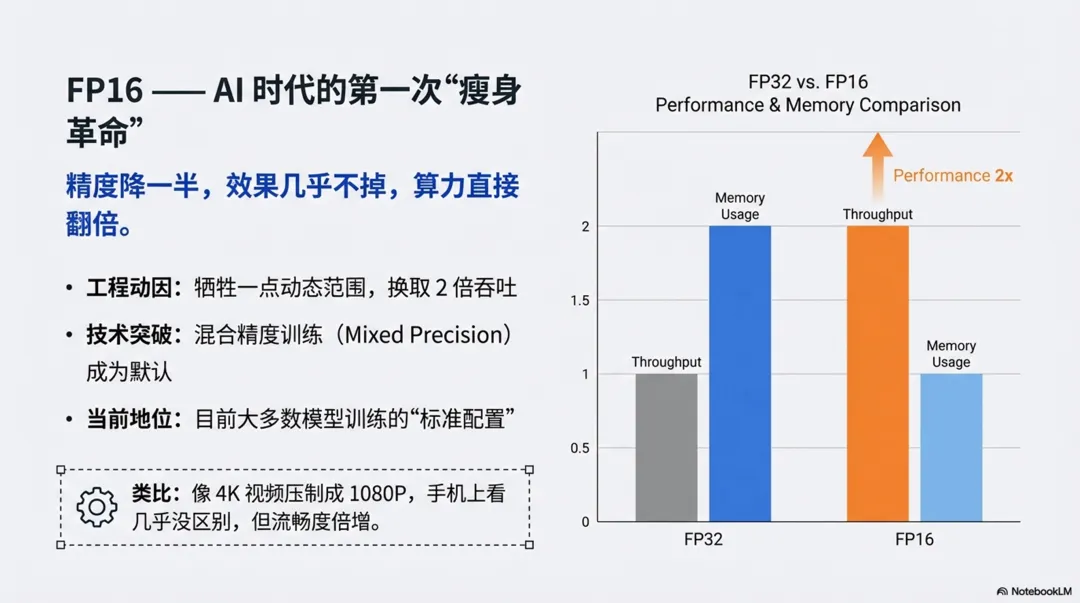
1)工程动因:在不明显掉效果的前提下,把吞吐和显存翻倍
FP16(16 位浮点)出现很早,但真正被“重视”是在深度学习兴起后。对 GPU 厂商和云平台来说,最直接的问题是:
能不能把每个数从 32 位压到 16 位,让同样的显存、带宽、芯片面积,跑出至少 2 倍算力?
工程收益很直观:
- 一样的显存,可以放更大的模型或更大的 batch。
2)AI 之前的价值:在嵌入式/图像管线里“省资源”的小角色
在 AI 之前,FP16 主要在这些地方出现:
- 移动端/嵌入式图形:半精度纹理在移动 GPU 上普遍,用来节省带宽和存储。
- 图像处理:不需要很高精度,但需要浮点灵活性,这时 FP16 是个不错的折中。
也就是说,它原本是一个“节能/省空间”的小角色,而不是通用计算的主力。
3)AI 规模化后,纯 FP32 不够,FP16 又有什么矛盾?
当大家开始把训练/推理搬到 FP16 时,很快遇到了两个问题:
- 动态范围不足 /溢出问题
- 指数位更少,有些梯度和激活在 FP32 里“正好”,到 FP16 里就变成 0 或 Inf。
- 尾数位少,累加误差大:
- 用 FP16 直接做大规模矩阵乘 + 累加,会把小量贡献吞掉,SGD 更新变得不稳定。
- 需要特殊的 loss scaling、梯度缩放等 trick 才能稳定训练。
因此,工程现实是:直接把所有 FP32 换成 FP16 不行,必须搞混合精度。
4)业界的集体迁移:混合精度成为默认配置
迁移路径大致是这样:
- NVIDIA 引入 Tensor Core,专门做 FP16 矩阵乘,但累加在 FP32 完成(典型的“乘低精度、累加高精度”)。
- 框架支持:PyTorch、TensorFlow、MXNet 先后支持 AMP(Automatic Mixed Precision),自动把适合的算子换成 FP16。
- 工程最佳实践:权重/激活用 FP16,梯度累加、优化器状态用 FP32(或者 BF16 + FP32)。
- 大多数大模型训练都已经是“FP16/BF16 + FP32 混合精度”作为默认选择,纯 FP32 训练只在少数精度极敏感场景。
- 推理侧,云厂商 GPU 实例都会强调“FP16/BF16 tensor 性能”。
FP16 让行业第一次集体意识到:“精度可以降,但要聪明地降。”
3.3、FP8:为“超大模型时代”再砍一刀

1)工程动因:大模型时代,16 位仍然太奢侈,必须再压一半
当 LLM 进入百亿、千亿参数规模,单卡 80GB 显存都吃紧,即便用 FP16/BF16:
- 模型本体 + KV Cache + 中间激活,很快就顶满显存。
工程问题变成:
如果从 16 位再压到 8 位,能不能再拿到一次“吞吐 ×2、显存/带宽 ×0.5”的大跃迁?
FP8 就是在这个背景下,被 Arm、Intel、NVIDIA 等一起推动出来的 8 位浮点标准,目标是 同时服务训练和推理。
2)AI 之前的价值:几乎没有——它就是为 AI 生的
与 FP32/FP16 不同,FP8 在 AI 之前几乎没有历史包袱:
所以它的“历史定位”非常干净:就是为神经网络的矩阵运算、尤其是 Transformer 类网络的训练/推理而生。
3)大规模 AI 下,FP16 为何开始“不够香”?
当大家把 LLM、推荐大模型、视觉大模型规模上到千亿参数后,FP16 的短板暴露出来:
- 1×FP16 权重 + 1×KV Cache + 中间激活,很快压到单卡极限。
- 训练一个 GPT-3 级别模型就要消耗巨额电费和 GPU 时间。
当 FP16 成为“新常态”之后,大家自然开始问:
如果 32 位能降到 16 位,为何不能再从 16 降到 8?AI 模型到底能吃下多少这类数值噪声?
4)业界的集体迁移:FP8 正在“落地期”
迁移过程目前大致在这样一个状态:
- Arm、Intel、NVIDIA 联合定义了 FP8 标准,方便不同硬件、框架之间共享模型。
- E5M2 和 E4M3 是 FP8 算力精度下的两种数据表示格式,它们的核心区别在于如何分配 8 个比特(bit)来平衡“数值范围”和“数值精度”。E5M2、E4M3 两种格式,在 8 位空间的极限下,范围和精度是不可兼得的“杠杆两端”,E4M3 侧重“准”,E5M2 侧重“广”。
- H100、L40S 等新一代 GPU 都支持 FP8 Tensor Core,广告语基本都是“FP8 训练吞吐翻倍”。
- 各大框架、推理引擎在逐步加入 FP8 support、自动 scaling、per‑channel 配置等。
- 一些公开 benchmark 已经展示:在合理设置下,FP8 训练/推理能做到接近甚至匹配 FP16 精度,但吞吐大幅提升。
- 对“尖端大模型训练”和“大规模推理服务”,FP8 正在从“尝鲜”走向“早期主流”;
- 对中小规模模型和传统任务,FP16/BF16 仍然是主要选项,FP8 还在“验证成本/收益比”的阶段。
可以说,FP8 是“正在进行时”:标准已定、硬件就绪,软件生态在跟上,工程认知在形成。
3.4、INT8:从“高精度浮点”回到“粗粒度整数”

1)工程动因:推理场景要极致性价比,整数运算最便宜
INT8 本质上不是新东西,8 位整数在计算机里存在很久了。它之所以在 AI 里重新被捧上台,是因为:
在边缘设备/手机/大规模线上推理解耦负载里,浮点单元贵,整数单元便宜,如果能把模型都压成 INT8,性价比爆表。
工程收益非常直接:
- 大多数 CPU/DSP/专用 NPU 的 INT8 算力远大于 FP32/FP16。
2)AI 之前的价值:数字信号处理、嵌入式里的“老兵”
在 AI 之前,INT8/定点数在很多领域是主角:
- 通信、音频、图像编码:常用 8 位或更低位宽的定点数做滤波、变换。
- 传统嵌入式控制:MCU 上大量运算都是整数,浮点很贵。
这些领域早就习惯了“为了省资源,牺牲一部分精确度”。
3)AI 规模化后,浮点依然主导,INT8 的矛盾点在哪?
当 AI 规模化之后,INT8 面临的矛盾其实和 FP8 不一样:
- 纯 INT8 训练在数值稳定性上难度极高,梯度范围、更新幅度很难控制。
- 目前工业界主流仍是“高精度训练 + 低精度推理”,INT8 主要用于推理。
- 把训练好的 FP32/FP16 模型直接硬压成 INT8,会带来较大精度损失。
这些矛盾催生出一整套新工程技术:量化算法、scale 策略、per‑channel 量化、QAT(量化感知训练)等。
4)业界如何集体迁移:INT8 推理已经是“成熟工业品”
迁移的大致路径是:
- 第一阶段:简单 PTQ(Post‑Training Quantization)
- 直接把 FP32 权重按固定 scale 映射到 INT8,激活也做类似处理。
- 第二阶段:QAT(Quantization-Aware Training)
- 在训练阶段就模拟 INT8 的量化误差,让模型“习惯”低精度,再导出 INT8 模型。
- 对 CNN、部分 NLP 模型,QAT 能显著改善 INT8 模型精度。
- 各大框架(TensorFlow Lite、PyTorch、ONNX Runtime、OpenVINO 等)都内置了 INT8 量化工具链。
- 移动端 SoC、云端 CPU/NPU/GPU 都把 INT8 作为核心卖点之一。
- 在很多生产推理场景(尤其是 CNN/ResNet/MobileNet 类),INT8 已经是事实标准。
目前的局面可以概括为:
- 训练侧:仍以 FP16/BF16/FP8 为主,INT8 训练还在研究和试点。
- “老牌视觉模型、小模型、多路并发服务” → INT8 很成熟。
- “超大 LLM 推理” → 更倾向 FP8/INT4/混合方案,INT8 多用于权重量化等部分路径。
3.5、这条演进链背后的“统一认知落点”
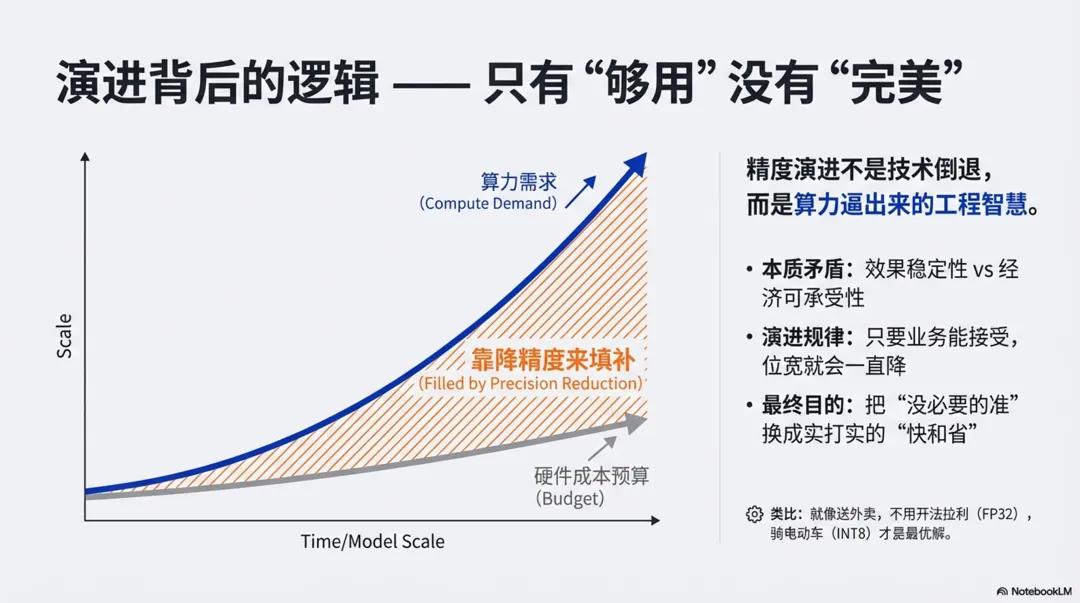
把 FP32 → FP16 → FP8 → INT8 放在一起看,会发现一条非常清晰的工程因果:
- 工程动因
- 算力需求指数级增长,能源和成本做不到同步指数级增加。
- 想继续堆大模型、撑高 QPS,就必须在“每个数字上省 bit”。
- 行业选择
- FP32 → FP16:第一次降精度,证明“AI 能接受不那么准”。
- FP16 → FP8:大模型时代再压一刀,依赖更强的算法和硬件协同。
- FP8 → INT8(推理侧):在可以容忍一定误差的场景,把“浮点语义”部分交给量化算法,最终落在整数上。
- 时间趋势
- 认知
FP32:为通用数值计算准备的“老牌精度”,在 AI 里现在主要做安全网和关键累加。
FP16:第一次证明“精度可以降一半,效果几乎不掉,算力翻倍”,现在是基础配置。
FP8:为大模型时代定制的新浮点,让训练和推理的吞吐再翻一倍,正在从尝鲜走向主流。
INT8:用整数做 AI 的推理标准,靠量化算法把精度损失控制在可接受范围,换极致性价比。
每一次位宽的变化,都是算力需求和成本压力推着走的工程结果,而不是学术上追求优雅。
行业每走一步,都会先证明:在某个应用上,降精度后的模型效果可以被业务接受,然后才会规模迁移。
大家谈 FP8、INT8,本质是在延续 FP16 当年那条路:用更聪明的数值设计,把‘没必要那么准’的那一部分,换成实打实的算力和成本优势。
二、第二部分|我的理解
2.1、认知提炼
真正驱动精度演进的,是工程矛盾,而不是技术理想。
如果只看技术参数,精度演进会显得零散、割裂。但从工程角度看,它其实围绕着一个非常清晰的核心矛盾。
2.1.1. 精度演进的核心矛盾
效果稳定性 vs 经济可承受性
精度演进,本质上是在不断寻找这两者之间的平衡点。
2.1.2. 为什么现有讨论总让人困惑?
因为我们经常混用三种不同层级的语言:
结果就是:
每个人都在说自己的认知,但没对齐同一个问题。
2.2、这个模型对企业级用户意味着什么?
这条数值精度演进史,帮企业在算力选型时看清三件事——
1、现在真正需要的精度层级是什么、
2、未来要走到哪一级、
3、哪家厂商在这一条路线上已经走在工程事实而不是 PPT 上。
2.2.1、算力选型启示
在企业级场景中,算力选型往往不是一次纯技术决策,而是一种长期成本、风险与责任的综合选择。
精度问题,恰恰是其中最容易被误解、也最容易被过度放大的因素之一。
基于前文对精度的拆解与抽象,总结一些对企业级算力选型有用的认知启示。
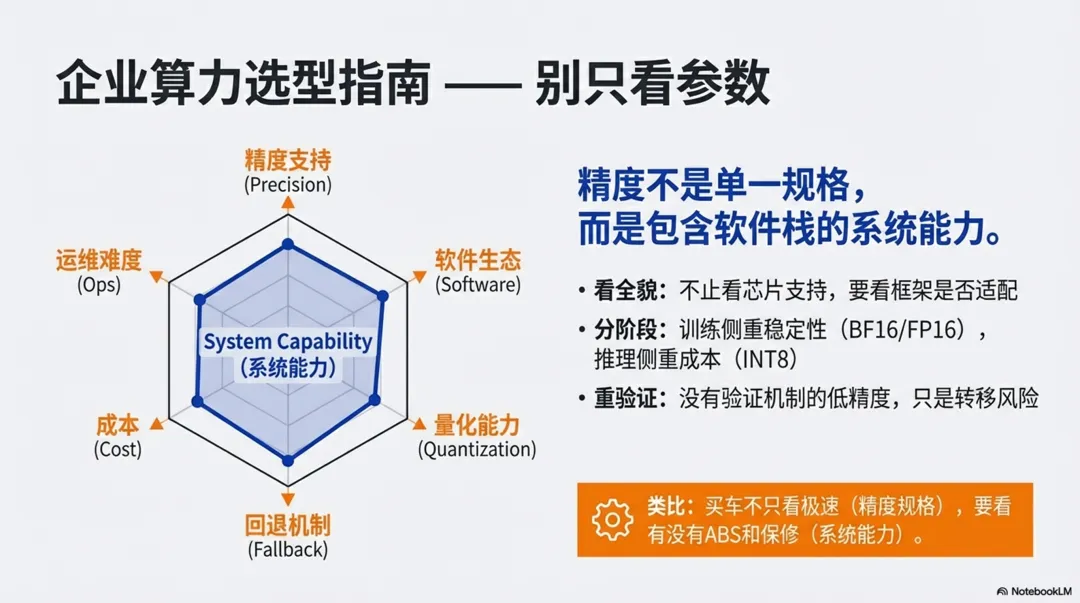
1、精度不是算力规格,而是“系统能力的一部分”
从工程视角看,精度并不是一个孤立属性,而是由以下能力共同决定的:计算单元是否支持多精度、软件栈是否支持混合精度、是否具备量化、校准与验证能力、出现问题时是否可以回退或切换
同样支持 FP8 的算力平台,实际可用性可能完全不同。
因此,对企业级用户选择精度而言,问题不应是:
“这块算力支持什么精度?”而应是:“在不同精度下,这套系统是否仍然可控、可解释、可运维?”
2、算力选型前,先问清楚“用在什么阶段”
精度讨论必须放在训练侧和推理侧分别进行,否则结论一定会偏。
- 训练阶段:更关注数值稳定性、精度切换的风险更高、成本压力集中在“单次训练是否可完成”
- 推理阶段:更关注吞吐、延迟与单次成本、更容易接受低精度、精度问题更多体现在“边缘场景”
如果一个算力方案在宣传中混用训练与推理的精度优势,企业在选型时就需要格外谨慎。
3、精度讨论,往往是成本讨论的“替身”
在很多算力选型场景中,精度被反复讨论,其实并不是因为精度本身,而是因为:成本压力无法被直接讨论,业务规模尚不确定,决策者希望找到一个“技术理由”
理解这一点非常重要,精度问题如果脱离了:业务规模假设、调用频次、生命周期成本
单独讨论,很容易变成技术正确但决策错误。
4、把“选规格”变成“选精度–模型–业务三件事的组合”
在选型算力时,不需要只盯着卡型号和显存,而要同步思考三件事:
- 业务:你是做超大 LLM 服务,还是大量中小模型推理,还是训练为主?
- 模型:是千亿级 LLM,还是若干亿级视觉/推荐模型?
- 精度:这些模型在你的业务指标上,能接受多大的效果波动来换取多少成本优化?
2.2、精度语义治理启示
当精度被放回工程与业务语境中,它就不再是一个“规格参数”,而是一个治理问题。
第一,精度必须分层管理
不同系统层、不同任务,对精度的敏感度完全不同。
第二,精度调整必须可验证
没有验证机制的低精度,只是风险转移。
第三,精度选择必须可解释
对业务、对管理、对未来的审计,都必须说得清楚。

三、结语|为什么我要写这篇文章
篇幅和内容多到我在犹豫是否发布,但是觉得还是做一个积累,给认知做一些提升,并不是为了给出一个“精度应该选多少”的标准答案。
而是想把长期混在一起的概念拆开,让讨论重新变得可能:
只有先把语义拉齐,工程决策才有意义。