偷懒的论文学习笔记(7)|为什么Agent越聪明,GPU反而越闲?清北联合DeepSeek这篇DualPath论文,打破了我对大模型推理的认知
最近在AI圈,Agentic(智能体)应用可以说是红得发紫。大家都在谈论怎么让大模型接入浏览器、执行代码、多轮反思。但如果你去问真正负责在大厂里部署和运行这些Agent的底层系统工程师,他们大概率会大吐苦水:Agent这玩意儿,简直就是吞噬I/O(输入输出)的黑洞。
当我们在前端看着Agent聪慧地执行着几十上百轮的复杂任务时,后台机房里却出现了一个极其诡异的现象:昂贵的GPU计算利用率掉到了冰点(比如只有40%),它们无所事事地停在那里,就为了等硬盘把数据读出来。感觉就像是你花重金请了一个顶尖的数学家,结果他大部分时间都在等外卖小哥把草稿纸送过来。
这篇文章,我们就来抽丝剥茧地聊聊DeepSeek、北大和清华联合发布的这篇最新论文——DualPath。它到底做对了什么,为什么能把Agent推理的吞吐量硬生生翻了近一倍,以及这背后揭示的系统演进哲学,跟我们有什么关系。
关于“GPU越来越闲”
我有一个论调:大模型推理系统现在的瓶颈,早就不是算力(Compute)了,而是存储带宽(I/O)。
传统的大模型聊天(像ChatGPT)是“一问一答”。但Agentic应用完全是另一个物种。一个典型的代码Agent,可能会和环境交互几十上百轮,积累下极其庞大的上下文(动辄几万到几十万Token),但每次实际新增(Append)和生成的Token却只有寥寥几百个。
这就带来了一个极其夸张的KV-Cache命中率(通常≥95%,甚至高达98.7%)。这意味着模型在每一轮根本不需要进行多少实质性的“计算”(Prefill),它真正需要做的是:把之前几十万Token的记忆(KV-Cache),从便宜但缓慢的外存(SSD)里重新搬回显存里。
以DeepSeek-V3.2为例,在处理这类任务时,它的“缓存/计算比”大约是22 GB/PFLOP,这意味着要把存储网络带宽彻底撑爆。如果你看看这几年的硬件演进史就会发现这有多绝望:从Ampere到Blackwell架构,GPU的算力(FLOPS)翻了28.8倍,但PCIe带宽只涨了2倍。算力涨得越快,GPU因为等数据而产生的“闲置”就越严重。
现行架构的死穴:被反噬的PD分离
为了解决推理效率问题,过去两年业界形成了一个黄金标准:Prefill-Decode(PD)分离架构。简单说,就是让一批机器专门负责“阅读理解”(Prefill),另一批机器专门负责“逐字生成”(Decode)。
对于传统的聊天应用,这套架构简直完美。但一碰到Agent,它立刻就暴露出了一个致命的“死穴”。
在PD分离架构下,命中缓存的庞大KV-Cache数据,只能由Prefill节点的存储网卡(SNIC)从远端存储中读取。这就导致了一个极其滑稽的局面:Prefill节点的存储网卡带宽被100%打满,甚至堵得水泄不通;而Decode节点明明也配了同样规格的存储网卡,此时却毫无用武之地,利用率几乎为零。
换句话说,这就好比一条高速公路明明有10个收费站,但系统却死板地规定大货车只能走第1个,导致第1个收费站排起长龙,剩下9个收费站的工作人员在里面打瞌睡。这就是我们在Agent时代遇到的结构性失衡。
DualPath的破局:借道与暗渡陈仓
DualPath的聪明之处就在于,它打破了“KV-Cache必须由Prefill节点读取”的思维定势。
既然Decode节点上的存储网卡(SNIC)闲着,那为什么不让它去帮忙读数据呢?
DualPath引入了一条全新的数据路径:Storage -> Decode -> Prefill。
当Prefill节点忙不过来时,系统会把读取任务派发给Decode节点。Decode节点把KV-Cache从磁盘读进自己的内存后,再通过极其高速的计算网络(Compute Network,比如RDMA),把数据瞬间“闪送”给Prefill节点。
这就非常巧妙了。现代AI集群中,计算网络(GPU和GPU之间的通信)的带宽往往是存储网络的几倍(比如8x400Gbps对1x400Gbps),而且在推理过程中,计算网络的流量是呈现“阵发性”的微秒级爆发,中间存在大量的闲置间隙。DualPath等于是“白嫖”了Decode节点的空闲存储带宽,又“白嫖”了计算网络的空闲传输带宽,硬生生把全局的I/O瓶颈给冲破了。
限制和Trade-off(工程上的无底洞)
听起来是不是很简单?但如果你真的在机房里手搓过这种系统,你就会知道这里面全是深坑。
当你试图把巨大的KV-Cache数据流塞进“计算网络”和PCIe总线时,你会遇到一个经典的冲突(Trade-off):数据的搬运,绝不能干扰模型本身的计算。
像DeepSeek这种MoE模型,在计算时需要进行极其密集的AllToAll等集合通信(Collective Communications)。这些通信对延迟极为敏感,稍微卡顿个几微秒,整个GPU集群就要停下来等。如果这个时候,你的一大坨KV-Cache数据刚好通过同一张网卡挤进来,两边就会撞车,导致推理性能断崖式下跌。这就陷入了一个悖论:你想利用闲置带宽加速,但一加速就干扰主业务。
为了解决这个限制,DualPath团队做了一个极其硬核的决策:放弃现成的GPUDirect Storage和CUDA Copy,改用“以CNIC为中心的流量管理器”。
他们把所有进出GPU的数据流都强制收口到计算网卡(CNIC),利用InfiniBand网卡原生的虚拟通道(Virtual Lanes, VL)功能做物理级的QoS隔离。他们把模型计算流量放在高优先级(预留99%带宽),把KV-Cache搬运放在低优先级。这就相当于在高速上强制划出了一条应急车道,大货车(Cache)只能在旁边慢慢挪,绝对不能挡住救护车(计算流)。虽然路径变长了(要多经过一次Host DRAM),但这是目前唯一能保证不干扰模型计算的解法。
此外,如果放任数据乱跑,很快Decode节点也会被撑爆。所以DualPath还配备了一个双层自适应调度器(Adaptive Scheduler),实时监控每个节点的磁盘读取队列(Reading Queue)和未完成Token数,动态决定这个请求到底该走传统的Prefill路径,还是借道Decode路径。
So What? 这跟我们有什么关系?
讲到这里,自然会有人问:分析了一堆底层架构,然后呢?我又不去手搓一个大语言模型推理框架,这跟我有什么关系呢?
回答是:底层架构的演进,永远是上层业务发展的风向标。
通过DualPath在真实Agentic RL(强化学习)任务中的测试,我们看到了极其夸张的收益:离线吞吐量提升了最高1.87倍,在线服务容量提升了1.96倍。但这背后真正值得我们深思的,是以下几点认知转移:
第一,理解Agent的真实成本结构。
当你或者你的公司在构思下一个“震撼世界的全自动Agent产品”时,不要只算大模型的API调用费(算力成本),必须把上下文持久化和状态读取的I/O成本算进去。DualPath的出现证明了,在Agent时代,存储和网络带宽的调度,甚至比压榨GPU的CUDA kernel更决定系统的生死存亡。
第二,不要迷信“绝对的职责分离”。
PD分离(Prefill-Decode Disaggregation)一度被奉为圭臬。但DualPath告诉我们,当系统演进到Agent范式时,过于绝对的物理隔离反而造成了资源的巨大浪费。在设计你自己的分布式业务系统(甚至是微服务架构)时,留一点灵活的“后门”(借道机制),让空闲节点能在不影响主业的情况下分担系统瓶颈,往往能取得意想不到的奇效。
第三,系统级Co-design才是终局。
DualPath不仅是一次调参,它是对计算、存储、网络进行的联合设计(Co-design)。他们甚至结合了Layerwise Prefill(逐层预填充)来解决HBM容量瓶颈,同时还要把数据块切分成“Layer Block”和“Full Block”来适应这种传输。这意味着,今天做AI,已经没有孤立的“算法优化”了,懂算法的人必须懂系统,懂系统的人必须懂网络拓扑。
毕竟,热门的模型框架可能会过气,但解决系统瓶颈的第一性原理和这些巧妙的Trade-off智慧,永远不会过时。
🔗 参考文献:https://arxiv.org/pdf/2602.21548
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,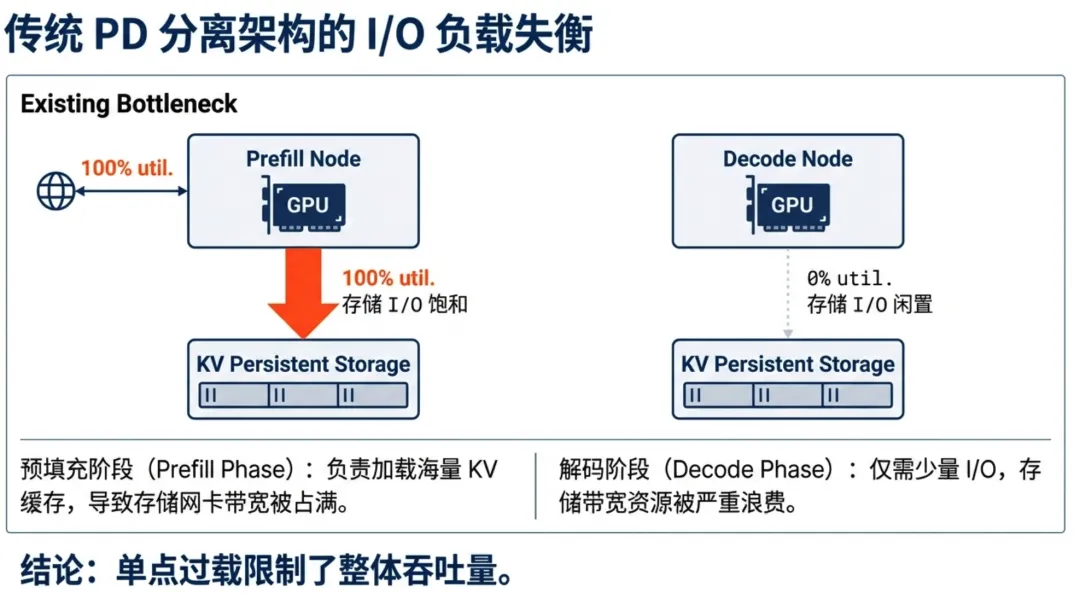

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
