一、资讯内容处理:
1)个性化推荐涉及3个部分:用户、算法和策略。
2)资讯内容来源:1、第三方网站提供2、企业编辑撰写3、作者撰写
二、资讯的分类体系:三种形式:
①结构化的分类系统:层级分明,存在父子关系。如:科技-互联网-AI;分类与分类之间相互独立。
②半结构化分类体系:具有结构化的形式,同时具有一些不成体系的分类
③非结构化分类体系:比较灵活,不存在明确的父子关系
三、常见的分类问题(分类做不好会影响用户体验):
1、一级分类=二级分类:如一些新闻的分类,一级分类名称是美食,二级分类名称也是美食。
2、二级分类不够全或者分的较粗:如历史被分为古代史、近代史、现代史
3、一些分类较杂:如科学探索分类下包括各种内容
4、一些二级分类的归属不合适
5、一些资讯没有归属
6、AI分类下的资讯有一些是玩偶
四、内容分类原则:结构化分类体系的搭建原则1、相互独立2、完全穷尽:各个分类应当完全穷尽列举3、命名应当短小易懂4、命名应当准确无歧义5、命名应具有内容代表性6、分类粒度应当适合7、每个分类下的三级分类不能过于庞大8、释义应当简单明了,不应长篇大论,太过专业
五、分类体系的搭建
1、程序抓取:抓取浏览量较多的关键词。实际操作看,用户的兴趣分层(一、二、三级)分类—主题—兴趣点—关键词。
2、人为定义:操作步骤:①了解每个一级分类的内涵②根据网站分类,逐一列举,列举三级分类的分类词③从三级分类合并为二级分类,以及二级分类拆分为三级分类双向进行整理。④对分类给出释义和边界,以便标注人员区分。
新的问题:如何保证三级分类下的资讯充足?如何保证人工分类的准确性?
两项措施:①针对第一个问题,把三级分类词放进资讯召回系统中进行搜索,查看内容及数量是否充足②针对第二个问题,部分资讯要先经过标注人员的人工标注,标注时反馈具体某三级分类存在的问题及不合理性,产品人员、运营人员、编辑都会介入此环节对不适合的三级分类进行修改。
六、内容的标注与机器学习
1)内容标注:目的是为内容选择对应的分类。内容运营人员会设置质检小组,对编辑和标注人员的结果进行抽样检查。
2)机器学习:标注人员不会对所有内容进行标注。
1、标注人员标注一定数量的内容,算法工程师运用算法对人工标注的样本进行有监督的机器学习,把剩余内容用程序给它标注分类。
2、算法工程师会使用多种方法对内容进行机器学习。
3、标注人员对使用3种方法进行分类的内容校验。计算公式:机器标注准确率=标注人员分类和机器分类相同的内容数量/总的内容数量。
4、算法工程师对标注不准确的内容继续进行机器学习,不停的迭代和优化算法。
七、资讯用户的画像和特征
1)资讯用户的画像:对用户这个客观实体的描摹。
2)资讯用户的特征:
1、特征介绍:从时效性上划分:长期特征(用户基本信息如性别、年龄等)、短期特征(用户的兴趣爱好和行为特征)和实时特征(用户的实时地理未知、网络状态)。
2、特征获取:通过用户主动填写或埋点来获取。根据业务指标对事实特征进行复合计算得到。
问题:如果用户没有填写某些信息或者获取不到怎么办?一般有2种解决方案:
①引入第三方数据补全用户画像
②算法工程师把填写性别的用户作为样本,按照男、女分别进行有监督的机器学习,对性别特征不完整的用户进行模型训练。
模型特征:制定一些规则为业务场景服务。
八、资讯的推荐算法
根据用户的一些条件,把符合这些条件的资讯从广阔的内容池中召唤出来,放到一个小的池子中。
1)资讯的信息抽取:①深度优先遍历,就是纵向最深,按照从左到右深度优先的规则把每个节点都走一遍。②主体的识别。识别哪些是正文,哪些是广告。
2)资讯的分词方法。有3种方法:①字典最大前缀数。需要有一个字典集,其中包含所有词语,当机器“读”一句话的时候,按照字典集中存在的词语从左至右进行匹配。直到找到最大的词组。
②N-Gram。N表示对一句话用几个字去拆分,如N=3,“个性化推荐真好玩”就会被拆分为“个性化”“性化推”“化推荐”等
③基于统计学的分词。例如贝叶斯公式,根据语料库的历史信息,分析当一个汉字出现时,另一个汉字出现在它后面的概率,从而进行分词。
3)资讯的过滤排重。
1、在分词后会进行一些过滤:
敏感词过滤
低质过滤(根据机器学习的历史低质资讯算法,以及标注人员标注的低质资讯,对资讯进行过滤)
排重(对相似度较高的资讯进行去重,有2种方法:
①I-Match找相似算法(假设有A、B两篇文章,我们首先统计出这两篇文章的高频词、中频词、低频词,去掉高频词和低频词,比较A、B两篇文章的中频词的相似度,卡一个相似度的阈值。)
②Shingle(瓦片)算法
假设有A、B两篇文章,A文章的内容是“我困了晚安我睡了”,B文章的内容是“我累了晚安我睡了”。Shingle算法会把A文章拆分为“我困了,困了晚,了晚安,晚安我,安我睡,我睡了”,把B文章拆为“我累了,累了晚,了晚安,晚安我,安我睡,我睡了”。两篇文章的相似度=重复词汇量/(A文章的词汇量+B文章的词汇量-重复词汇量)=4/(6+6-4)=50%,卡一个相似度的阈值。
对相似度达到阈值的文章进行过滤,仅留一篇,如按照发表的先后顺序或者按照文章的质量等保留一篇文章。
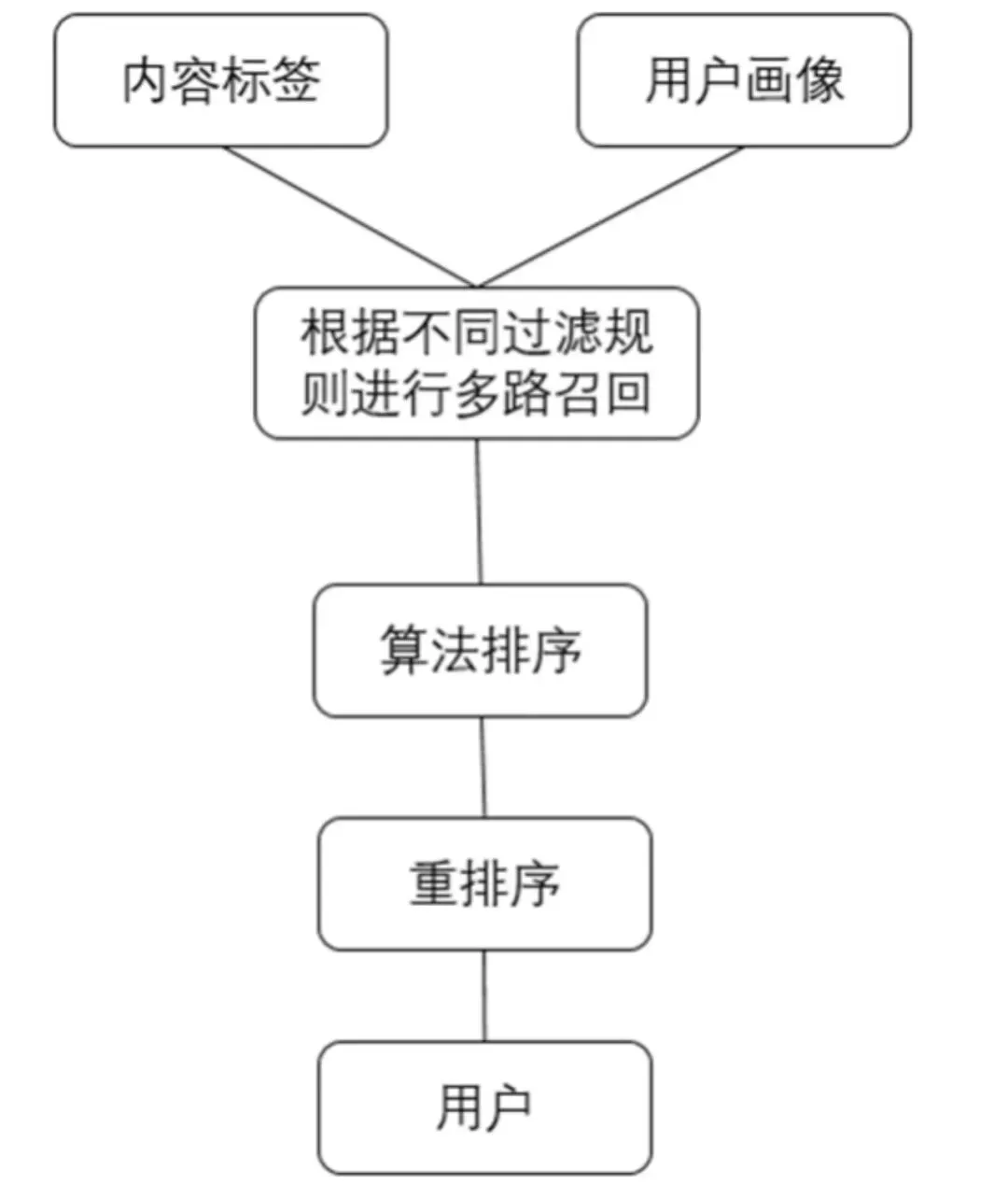
4)资讯的召回模型:一般有多路召回,每一路召回都有其合理性。
1、基于用户属性的召回
2、基于用户兴趣的召回
3、基于用户行为特征的召回
4、基于协同的召回:①空间向量模型。用一个向量来描述一个用户,代表不同用户的两个向量的夹角越小,就表示两个用户越相似。②协同(基于用户的协同(如果A、B用户在向量化后很相似,那么认为B用户喜欢的东西A用户也会喜欢)、基于内容的协同(如果A喜欢甲文章,甲乙两篇文章在向量化后很相似,那么A很可能也喜欢乙文章)、基于整体的协同。
5)资讯的算法排序
常见的排序模型:逻辑回归、梯度提升决策树、因子分解机等以及它们的复合变种。
经过排序后,对每个用户,我们输出一个资讯偏好评分由高到低排列的信息流。
九、资讯的重排策略及案例
1)常见的重排策略及策略目标:
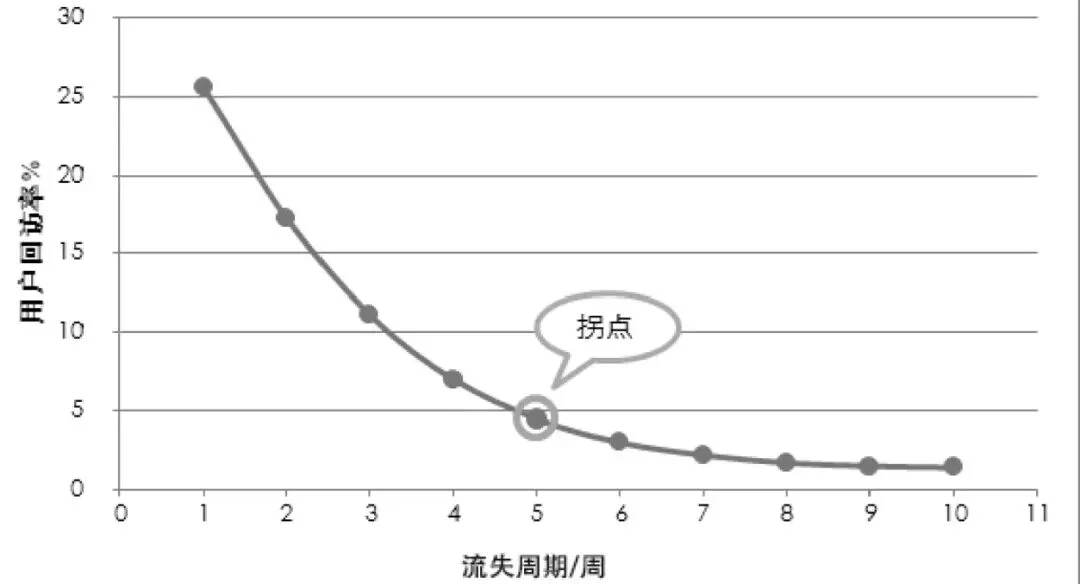
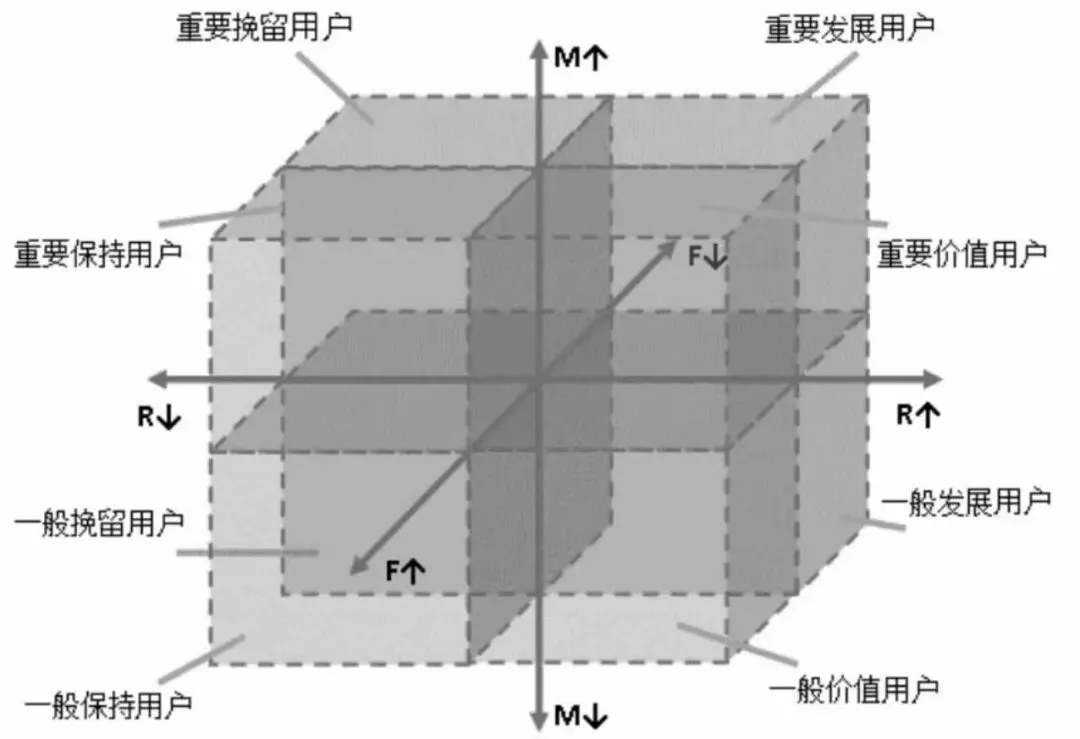
1、常见的重排策略:①新用户兴趣试探策略②兴趣打散策略③本地化推荐策略④分网络状态推荐策略⑤分时段推荐策略⑥搜索行为策略⑦负反馈策略⑧分场景策略⑨热点事件策略⑩通勤场景策略①①季节性策略①②流失召回策略
2、策略的目标:对新用户:发现他们的兴趣;对老用户:发掘他们更多的兴趣,提升点击率


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
