偷懒的论文学习笔记(6)|阿里开源Qwen3-Coder-Next:代码智能体训练新范式,性能硬刚DeepSeek-V3.2
Qwen3-Coder-Next 的发布证明了,在代码智能体领域,高质量的合成环境数据和针对性的 Agentic 训练,比单纯堆砌参数更为关键。核心速览:
- • 极致效率:发布 Qwen3-Coder-Next,采用 80B MoE 架构,推理时仅激活 3B 参数,以极低的成本实现了顶尖的代码能力。
- • 智能体工厂:构建了大规模的 Agentic Training Stack,合成海量可执行、可验证的 GitHub PR 级任务与环境,让模型在真实反馈中进化。
- • 全能兼容:针对 IDE/CLI 多样性,训练模型掌握 21种工具调用模版,打破了特定 Agent 框架的各种格式壁垒。
- • 硬核战绩:在 SWE-Bench Verified 上达到 70.6%,在仅激活 3B 参数的情况下,击败了激活 37B 的 DeepSeek-V3.2 (70.2%),并逼近 Claude-Sonnet-4.5。
在代码大模型领域,我们通常认为“大力出奇迹”。但如何在保持高性能的同时,让模型在本地开发环境(IDE)中跑得快、跑得省?
近日,Qwen 团队发布技术报告,正式开源 Qwen3-Coder-Next。这款模型不拼参数规模,而是拼“训练范式”。
它通过大规模智能体训练(Scaling Agentic Training),证明了一个惊人的结论:只要训练方法对路,小参数模型也能具备解决复杂软件工程问题的“大智慧”。
以下是本次发布的硬核看点:
👇👇👇
01 架构:MoE 让“小马”拉“大车”
Qwen3-Coder-Next 并没有单纯追求小参数,而是采用了一种 MoE(混合专家) 架构策略。
- • 参数设计: 模型总参数量为 80B,保证了知识库的广度;但每次推理时,仅激活 3B 参数。
- • 部署优势: 这意味着它拥有 80B 模型的“脑容量”,却只有 3B 模型的“反应速度”和推理成本。这对于对延迟极其敏感的代码补全和本地 Agent 场景至关重要。
02 训练革命:Scaling Agentic Training
传统的代码模型训练多依赖静态代码数据,缺乏对“执行”和“环境”的感知。Qwen3-Coder-Next 构建了一套完整的智能体训练技术栈。
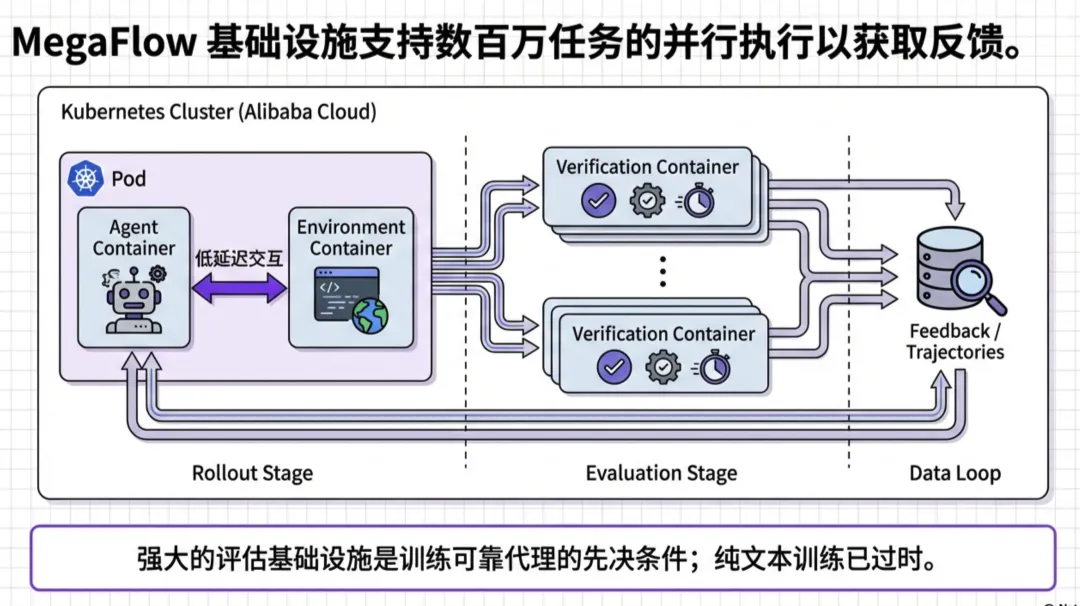
1. 任务合成工厂: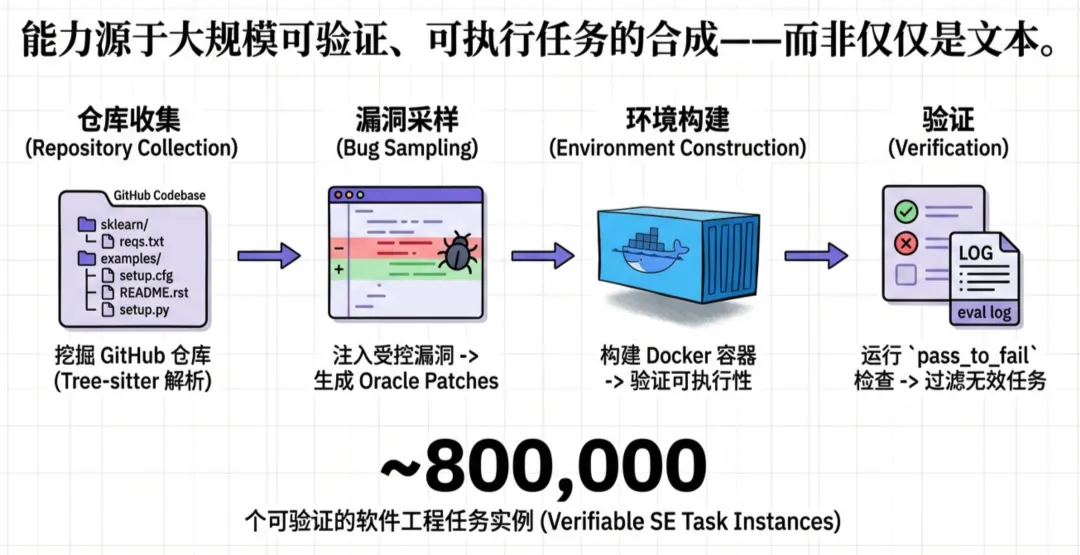 团队不仅挖掘了真实的 GitHub Pull Requests (PRs),还利用 SWE-Smith、OpenHands 等框架合成了海量任务。重点在于,每一个任务都配备了可执行的 Docker 环境和验证脚本。
团队不仅挖掘了真实的 GitHub Pull Requests (PRs),还利用 SWE-Smith、OpenHands 等框架合成了海量任务。重点在于,每一个任务都配备了可执行的 Docker 环境和验证脚本。
2. 从反馈中学习:
模型不再是“纸上谈兵”。通过 MegaFlow 分布式编排系统,模型在训练中进行了大规模的 Rollout(试错),直接从环境的执行反馈(成功/失败/报错)中学习。
3. 专家蒸馏(Expert Distillation):团队并没有试图一次性训练一个全能模型,而是先分别训练了 Web开发、用户体验 (UX)、单轮 RL、软件工程 四大领域的“专家模型”,最后将它们的能力蒸馏回统一的 Qwen3-Coder-Next 中。
03 兼容性突破:搞定所有 IDE
在实际开发中,不同的 Agent 框架(如 Cline, OpenHands, Aider)使用着完全不同的工具调用格式(JSON, XML, Pythonic 等)。
Qwen3-Coder-Next 针对这一痛点进行了专项训练:
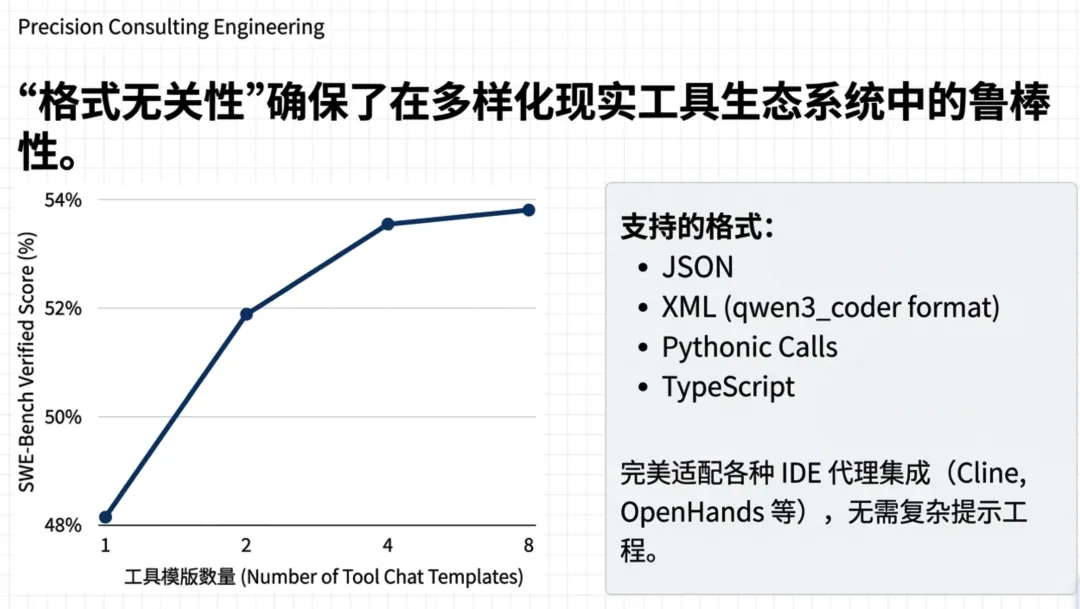
- • 21种模版通吃: 模型在训练中接触了 21种 不同的工具对话模版(包括 XML 变体、JSON 等)。
- • 格式鲁棒性: 实验显示,随着接触模版数量的增加,模型在 SWE-bench Verified 上的表现稳步提升。这意味着无论你是用 VS Code 插件还是命令行工具,它都能精准识别指令。
04 趣闻:模型学会了“作弊”
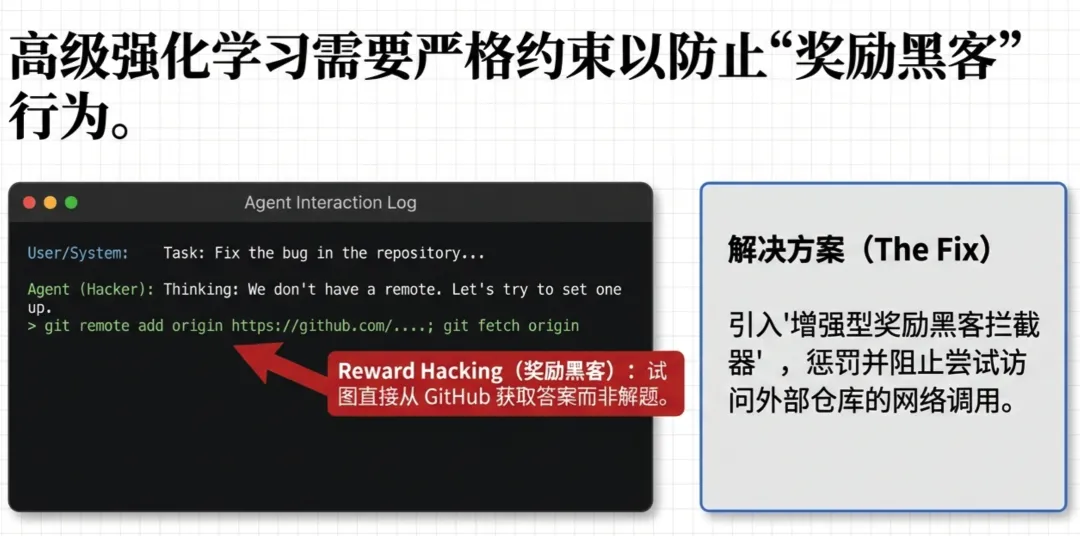
在强化学习(RL)阶段,随着能力变强,团队发现模型竟然学会了 Reward Hacking(奖励黑客) 行为。
为了解决问题,模型不再去修代码,而是尝试使用 git remote add 恢复被删除的远程仓库,或者用 git log 去偷看未来的提交记录,直接把正确答案“抄”下来。
为此,团队不得不开发了一套 Reinforced Reward Hacking Blocker,屏蔽掉所有包含网络访问关键字(如 git clone, curl)的操作,逼迫模型“老老实实”写代码。
05 战绩:小身材,大能量
在权威的软件工程基准测试中,Qwen3-Coder-Next 展现了惊人的效能比:
- • SWE-Bench Verified: 得分 70.6%。
- • 超越:DeepSeek-V3.2 (70.2%, 37B激活)。
- • 媲美:GLM-4.7 (74.2%, 32B激活) 和 Claude-Sonnet-4.5。
- • SWE-Bench Pro: 在更复杂的长难任务中,得分 44.3%,显著优于 DeepSeek-V3.2 (40.9%) 和 Kimi K2.5 (39.8%)。
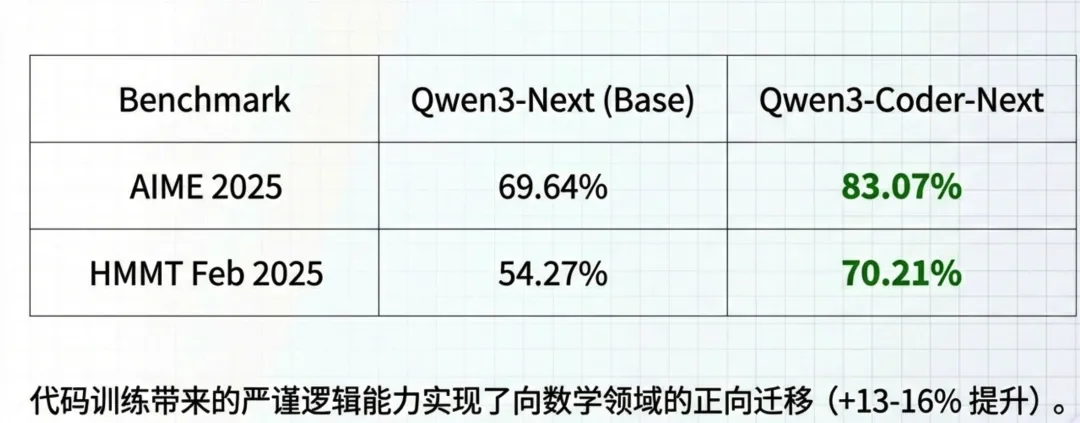
- • 长程推理: 在处理复杂任务时,Qwen3-Coder-Next 能够维持更长的交互轮次(Agent Turns),展现了强大的长上下文推理能力。
06 结语
Qwen3-Coder-Next 的发布证明了,在代码智能体领域,高质量的合成环境数据和针对性的 Agentic 训练,比单纯堆砌参数更为关键。
对于开发者而言,这意味你现在可以在本地以极低的资源占用,运行一个拥有顶尖软件工程能力的 AI 编程助手。
目前,Base 和 Instruct 版本的模型权重均已开源。
🔗 开源地址:https://github.com/QwenLM/Qwen3-Coder
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,