偷懒的论文学习笔记(7)|字节Seed团队新作!Stable-DiffCoder开源:扩散模型代码能力反超AR,小语种/编辑任务大爆发
Stable-DiffCoder 的出现,为代码大模型指出了一条新路:扩散模型不仅是为了推理加速,更是为了提升模型对代码结构的深层理解。核心速览:
- • 范式转移 (Paradigm Shift):打破了“扩散模型只快不强”的固有认知。Stable-DiffCoder 证明了扩散训练(Diffusion Training)本质上是一种极致的数据增强机制,能从有限数据中挖掘出深层逻辑。
- • 价值验证 (Value Proposition):在同等数据、同等架构的严格控制变量下,Stable-DiffCoder 全面超越了其自身的 AR 版本(Seed-Coder)。这不是简单的模型迭代,而是训练范式的胜利。
- • 差异化优势 (Differentiation):在代码编辑(Editing)与长尾语言(Low-resource Languages)两大场景展现统治力。对于 PHP、C# 等稀缺语料,其提升幅度远超传统模型。
- • 技术护城河 (Technical Moat):提出“AR预训练 + 小块扩散持续训练”的混合课程学习(Curriculum Learning),配合独创的截断噪声调度,解决了扩散模型训练不稳定的核心难题。
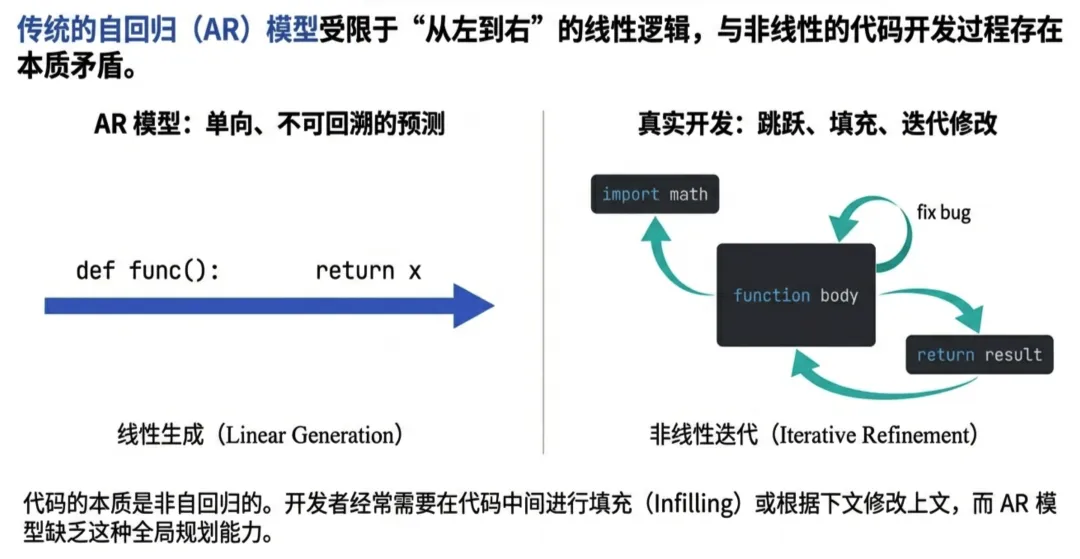
在代码大模型(Code LLM)的赛道上,自回归(AR)模型一直是绝对的霸主。尽管非自回归(Non-AR)的扩散模型拥有“并行生成”的速度优势,但在代码逻辑的严密性和生成质量上,始终难以望其项背。
行业内曾普遍存在一个隐性假设:扩散模型是为了“效率”而牺牲“质量”的妥协产物。
近日,字节跳动 Seed 团队与华中科技大学联合发布的 Stable-DiffCoder,彻底推翻了这一假设。这项研究不仅发布了一个 8B 的强力模型,更揭示了一个深层洞察:扩散模型不仅跑得快,只要训练得当,它甚至比 AR 模型更“懂”代码。
以下是基于麦肯锡思维方式,对该技术报告的深度拆解:
01 核心洞察:扩散训练即“超级数据增强”
为什么同样的训练数据,Stable-DiffCoder 能比 AR 模型学得更好?
第一性原理分析:
- • AR 模型(线性视角): 只能学习 ,即“从左到右”的一种可能性。对于一条珍贵的代码数据,AR 模型只能“读”一遍。
- • 扩散模型(全景视角): 学习的是 。通过随机掩码(Random Masking),模型被迫在任意位置、任意上下文中重建代码。
结论: 这种机制实际上是对数据的指数级复用。报告数据显示,对于 Python 这种数据充足的语言,提升可能有限;但在 PHP、C# 等“长尾语言”上,Stable-DiffCoder 展现了爆发式增长。这证明了扩散训练能够榨干数据的每一滴价值,是解决“高质量数据稀缺”痛点的最佳技术路径。
02 关键突破:驯服“不确定性”的精密工程
扩散模型难训练,核心在于其信号的高方差(High Variance)。字节团队没有采用暴力堆算力,而是通过精密的过程控制解决了这一问题。
三大战术动作:
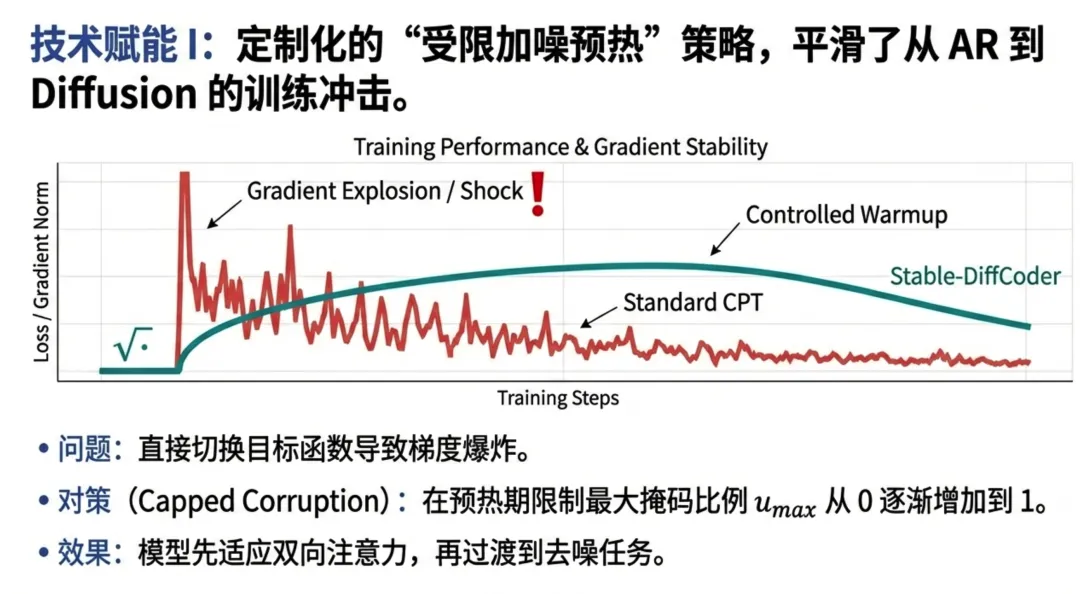
- 1. 课程学习 (Curriculum Design):采用 "AR First, Diffusion Second" 策略。先用 AR 模式高效压缩知识,再通过扩散模式进行“内化”和“重组”。这避免了模型在训练初期因掩码过多而“迷失方向”。
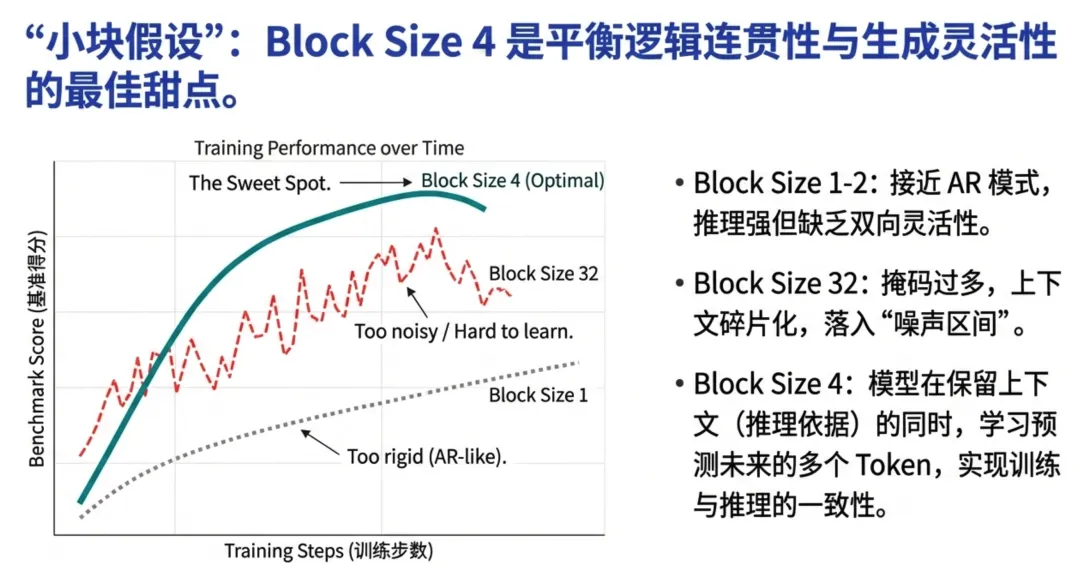
- 2. 小块扩散 (Small-Block Diffusion):将扩散单元限制在 block_size=4。这既保留了局部生成的灵活性,又在宏观上维持了代码的序列逻辑,实现了训练与推理的一致性(Alignment)。
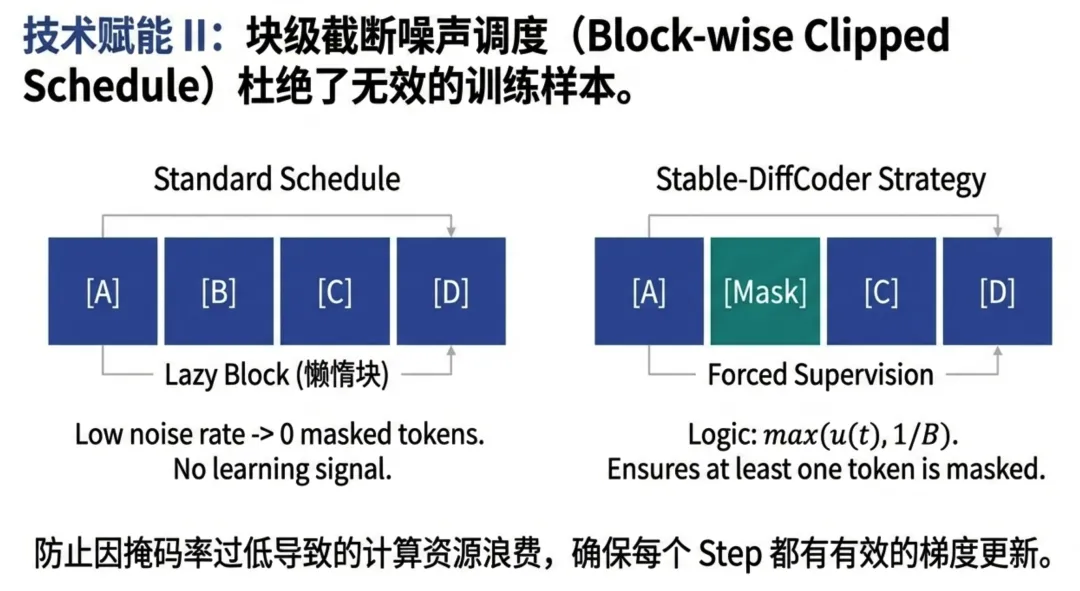
- 3. 截断噪声调度 (Block-wise Clipped Noise):这是本文最大的技术亮点之一。 传统调度在小块训练时容易出现“空转”(即没有Token被Mask,导致零梯度)。团队设计了强制截断机制,确保每一步训练都有非零的监督信号,极大提升了算力利用率(Compute Efficiency)。
03 性能矩阵:全方位的“六边形战士”
Stable-DiffCoder (8B) 的战绩不仅仅是“跑分高”,其分数的分布揭示了其独特的应用场景优势。
- • 基准统治力: 在 HumanEval (86.6%) 和 MBPP (85.7%) 上,它不仅击败了 LLaDA 等扩散竞品,更反超了其 AR 教师模型(Seed-Coder)。这意味着:扩散模型不再是 AR 的“降级替代品”,而是“升级形态”。
- • 编辑与维护 (Maintenance): 在 CanItEdit 榜单上达到 60.0% 的准确率,碾压 Qwen2.5 和 DeepSeek 同级模型。
- • 商业启示: AI 辅助编程正在从“从零生成(Greenfield)”转向“维护现有代码(Brownfield)”。Stable-DiffCoder 天然的 In-filling 能力使其在代码重构、Bug修复、遗留代码维护等高价值场景中具有天然优势。
- • 复杂指令遵循: 在 BigCodeBench 和 MHPP 等高难度榜单上,展现了接近 32B/70B 规模模型的推理能力。
04 战略意义:通往 System 2 的新路径
Stable-DiffCoder 的发布,对于 AI 开发者社区意味着什么?
- 1. 低成本起飞: 对于算力有限、缺乏海量数据的垂直领域开发者,引入扩散训练可以作为一种低成本提升模型性能的手段(无需扩充数据,只需改变训练方式)。
- 2. 交互形态变革: 其强大的任意位置编辑能力,为下一代 AI IDE 提供了底层支持——未来的编程助手将不再是简单的代码补全,而是能够实时、双向、多点地与人类协同修改代码。
目前,Stable-DiffCoder 的模型权重已全量开源,这或许标志着代码大模型“Diffusion 时代”的正式开启。
🔗 项目地址:https://github.com/ByteDance-Seed/Stable-DiffCoder
🔗 模型下载:https://huggingface.co/collections/ByteDance-Seed/stable-diffcoder
参考资料:Fan et al., "Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model", arXiv:2601.15892, 2026.
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,