最近正在读周鸿祎的《决战大模型 打造新质生产力》,这是第二篇读书笔记。今天继续提炼书中关于大模型本质认知的核心观点,希望能帮大家避开一些常见的理解误区。
在书的第一章中,主要阐述了以下7个问题:社会上对大模型有两种极端的观点、大模型理解了人类语言,是真智能、大模型是暴力美学新典范、大模型训练与人脑学习的类比、模型参数的本质、人们对大模型常见误解、大模型具备真智能的四大现象。
两种极端观点:大模型认知的误区
第一种观点认为大模型是用大量语料训练出来的“造句填空机”,虽然它能够回答人类的问题,但它自己也不能理解自己说的意思。换句话说,这种观点认为大模型相比传统AI没有实质性突破。
第二种观点认为大模型会毁灭人类。这种观点认为大模型会像科幻电影里描述的那样,变成硅基生物,不受人类控制,而最终将毁灭人类。
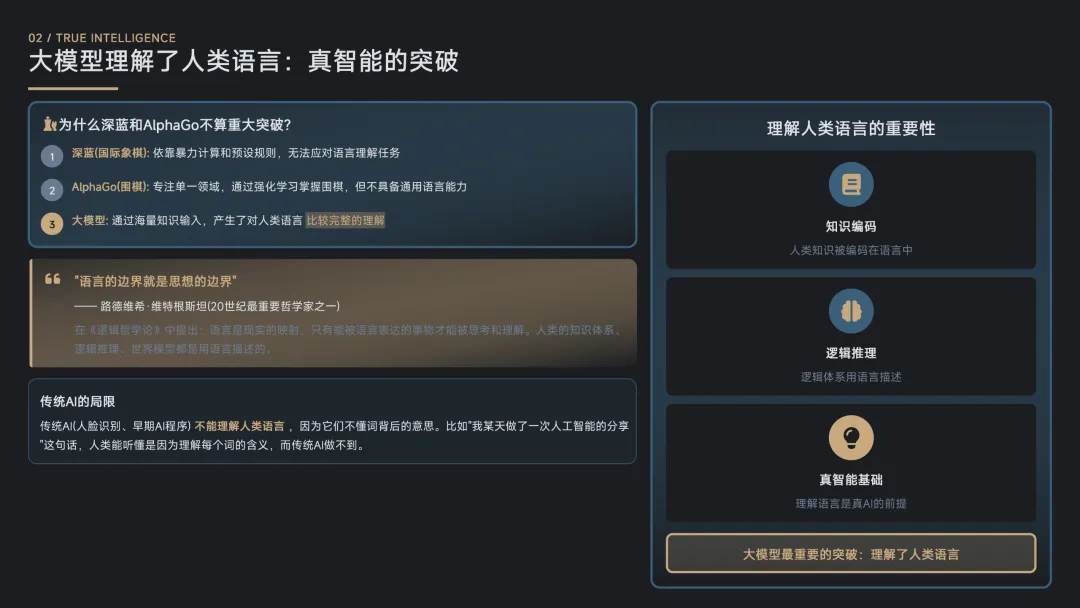
大模型理解了人类语言:真智能的突破
大模型最核心的突破是它通过海量知识的输入,产生了对人类语言比较完整的理解。理解人类语言是“真”AI的基础。
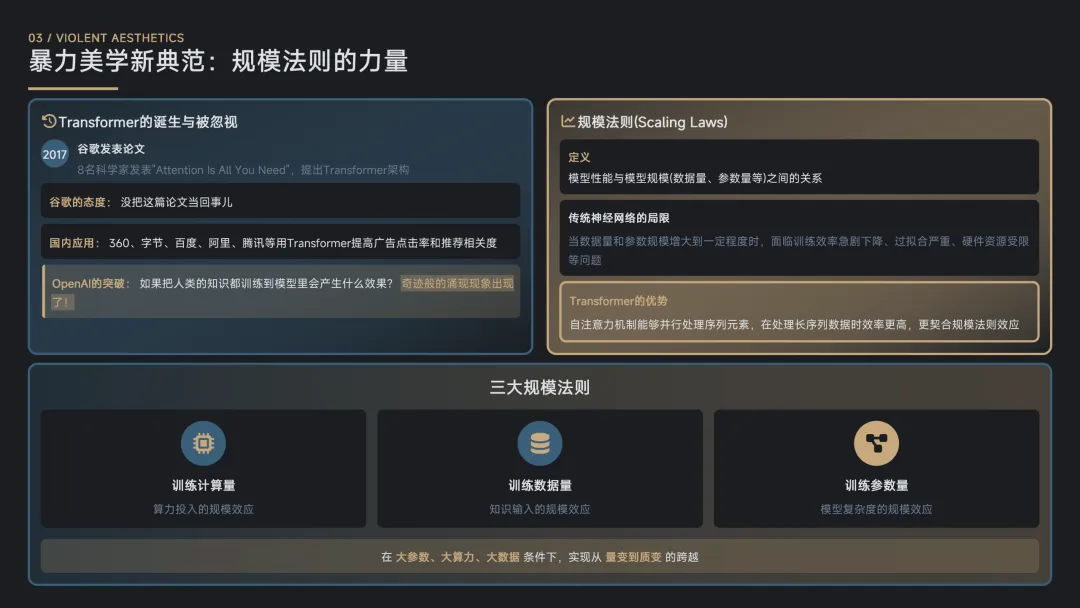
暴力美学新典范:规模法则的力量
规模法则:它指的是在AI模型训练过程中,模型性能与模型规模(如数据量、参数量等)之间存在一定的关系。OpenAI在模型训练过程中发现,对于Transformer以外的其他神经网络模型,例如用于人脸识别的传统卷积神经网络模型,当数据量和参数规模增大到一定程度时,会面临训练效率急剧下降、过拟合严重或者受限于硬件资源(如内存不足)而无法继续训练等问题。相比之下,Transformer在处理大规模参数方面具有显著优势,能够在更大规模的数据和参数下进行训练。也就是说,在具备足够算力、电力和数据的条件下,Transformer模型更易于扩大模型规模。这主要是因为Transformer模型在工程上更契合规模法则效应。Transformer模型中的自注意力机制能够并行处理序列中的各个元素,使其在处理长序列数据时具有更高的效率。这一特性使它在面对大规模数据和参数时,相比其他模型更具优势,能够在大参数、大算力和大数据的条件下,实现从量变到质变的跨越。
规模法则的挑战与新突破
三个规模法则:训练计算量的规模法则、训练数据量的规模法则和训练参数量的规模法则。
三个规模法则的局限?第一,人类的知识快用完了;第二,算力成为瓶颈。
推理时规模法则:OpenAI通过让大模型进行强化学习,即大模型通过自己给自己出题,自己给自己回答问题,实现“左右互搏”,通过自我产生数据、自我博弈训练,提升模型自身的能力。
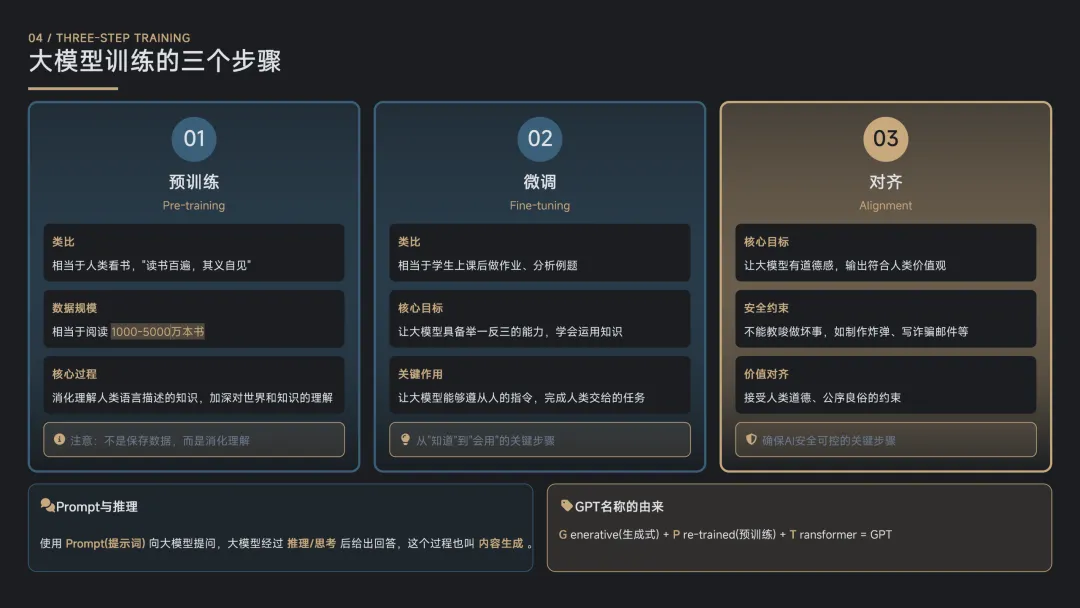
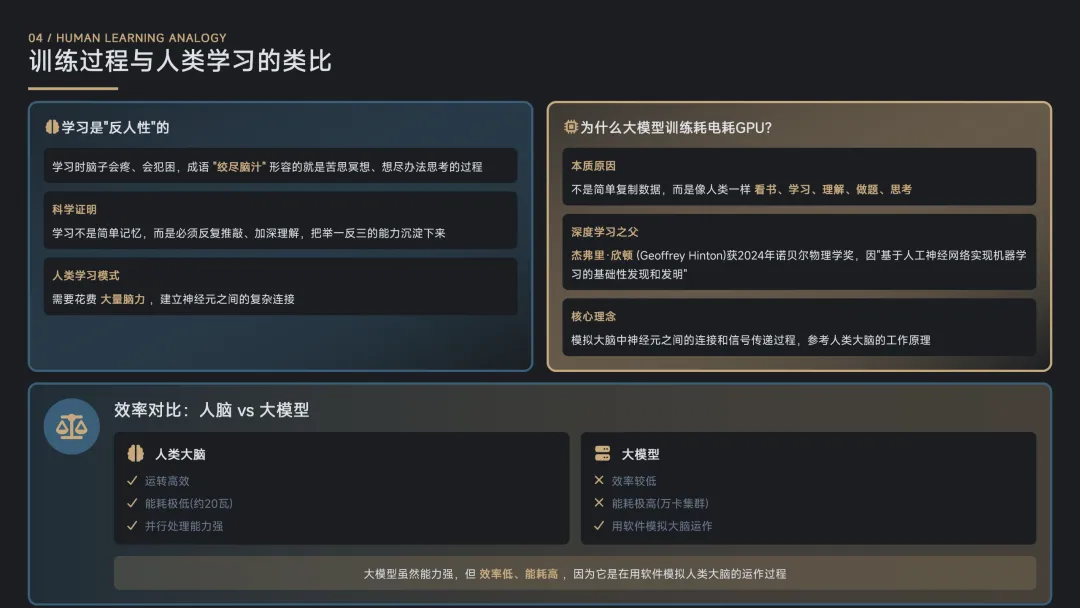
训练大模型的三个步骤:预训练、微调和对齐
预训练:大模型并不是把训练的数据保存起来,而是会消化理解这些知识
微调:就像我们上完课之后,老师还要给我们布置作业、分析例题,通过作业和例题让我们都具备举一反三的能力。这个学习之后做例题的过程,在大模型这里就叫微调。微调让大模型能够遵从人的指令,完成人类交给它的任务。
对齐:道德约束、安全约束。
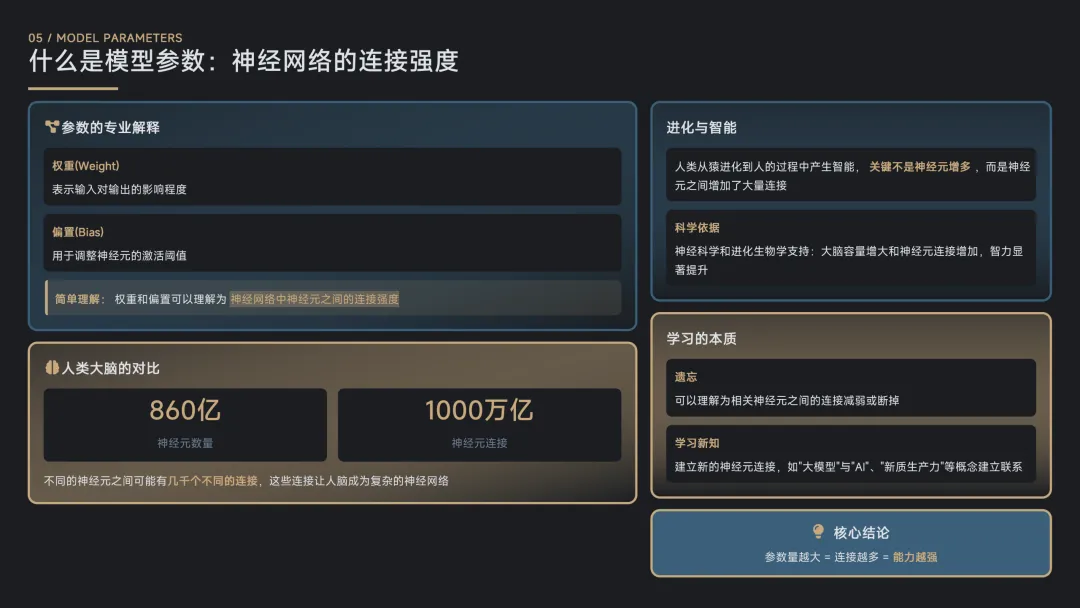
什么是模型参数:神经网络的连接强度
模型的参数,如果用术语来讲,应该叫模型的权重(weight)和偏置(bias),权重表示输入对输出的影响,偏置用于调整神经元的激活阈值。这两个术语,可以简单地理解为神经网络中神经元之间的连接强度。
不同的神经元之间可能会有几千个不同的连接。这些神经元之间的连接让人脑成为一个复杂的神经网络。可以认为这些连接就等同于大模型的参数,而连接的强度就代表权重的大小。
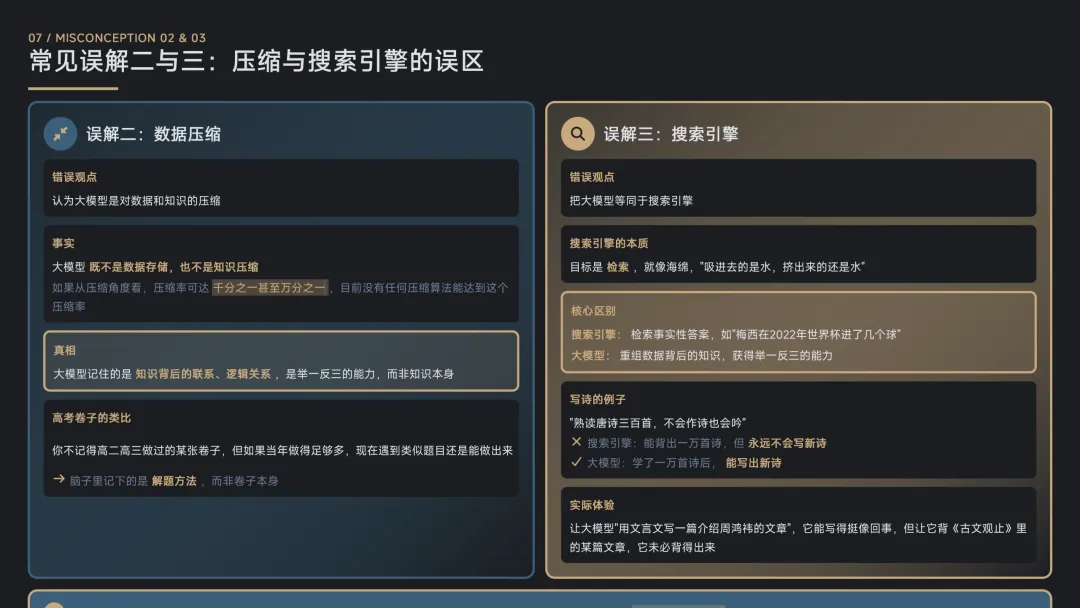
常见误解:不要用硬盘和内存的眼光看待大模型、压缩与搜索引擎的误区
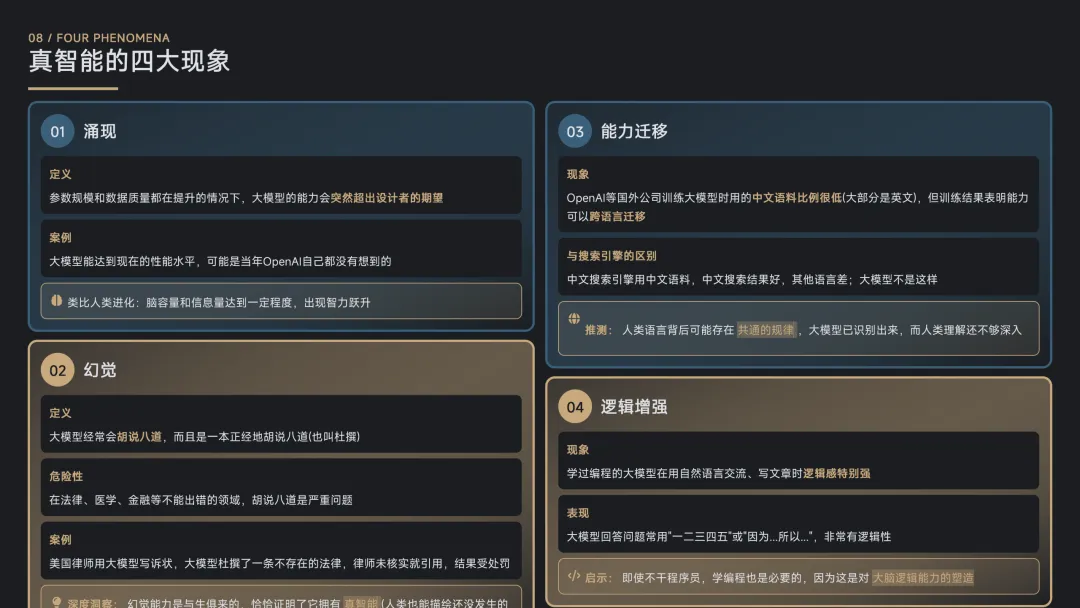
真智能的四大现象
涌现:规模达到临界点后,能力突然跃升,超出设计者预期,类似人类进化中的智力突破。
幻觉:看似缺点的"一本正经胡说八道",实则是人类特有的联想和创新能力——能够描绘尚未发生的事,这正是文明起源的基础。
跨语言迁移:用大量英文语料训练的大模型,中文能力依然出色,说明它掌握了语言背后的通用智慧规律。
逻辑增强:学过编程的大模型,自然语言表达的条理性显著增强,印证了思维训练的价值。
好了,同志们,今天的分享就到此结束了,大家可以在评论区进行相关话题的讨论,一起学习,一起进步,一起拥抱大模型。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
