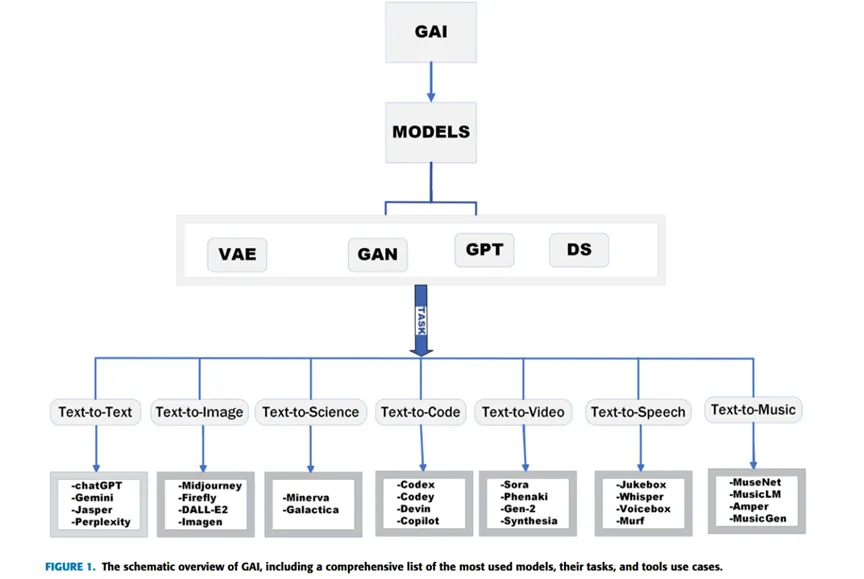
Advancements in Generative AI: A Comprehensive Review of GANs, GPT, Autoencoders, Diffusion Model, and Transformers
1. 背景介绍
人工智能(Artificial Intelligence, AI)这一概念最早可追溯到1956年的达特茅斯会议,其核心目标是使机器具备人类的智能。在此之后,涌现出了一系列经典或说传统机器学习算法,如回归模型(Regression Model)、感知机(Perceptron)、决策树(Decision Tree)、K近邻(K-Nearest Neighbor, KNN)、朴素贝叶斯(Naive Bayes Classifier)、支持向量机(Support Vector Machine, SVM)以及随机森林(Random Forest, RF)等,这些算法多数诞生于2000年之前。之后,随着计算能力的提升,深度学习(Deep Learning)逐渐崭露头角,出现了卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)、长短期记忆网络(Long Short-Term Memory, LSTM)等模型。尤其是2010年开始举办的ImageNet大规模视觉识别挑战赛和2012年AlexNet模型的突破,极大地推动了深度学习模型在图像识别领域的广泛应用,并衍生出残差网络(Residual Network, ResNet)、密集连接网络(Dense Convolutional Network, DenseNet)、移动端神经网络(MobileNet)以及高效神经网络(EfficientNet)等架构,逐渐形成了现代深度学习技术体系。
早期的深度学习模型主要聚焦于“描述性任务”(Descriptive Tasks),即对数据模式的建模与预测。直到2014年,Goodfellow等人提出了生成对抗网络(Generative Adversarial Network, GAN),该模型的提出标志着生成式人工智能(Generative Artificial Intelligence, GAI)的正式登场。生成模型的核心在于学习数据的底层分布,以生成高质量、与原数据相似的新样本。自此,GAI 在合成图像、文本创作、艺术生成等领域展现出巨大潜力,并引发学术界与工业界的广泛关注。随着模型能力和工具体系的指数级演进,生成模型不仅拓展了AI的边界,也开启了从预测走向创作的AI新时代,预示着在医疗、教育、工业设计、娱乐等多个行业中拥有极为广阔的应用前景。
2. 生成模型介绍
本节将讨论当前较为先进的生成模型的理论和数学基础。
2.1 自编码器
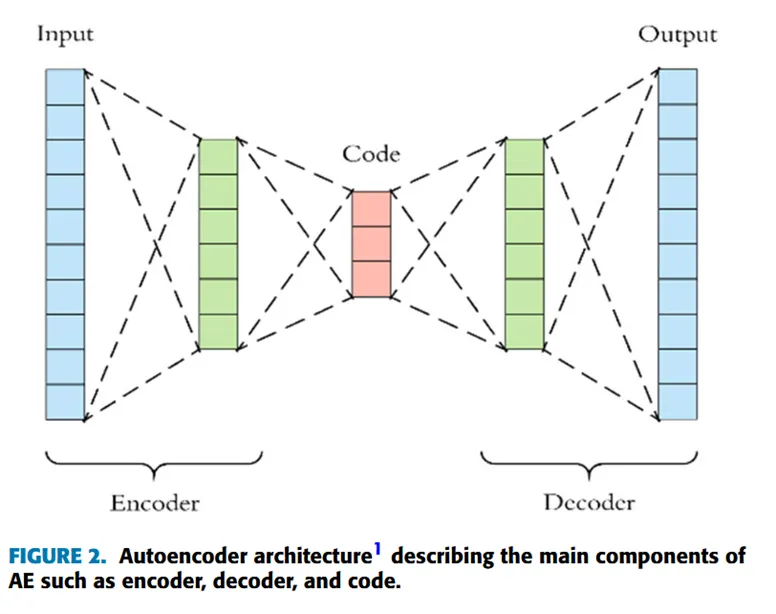
自编码器(Autoencoder, AE)是一种无监督的机器学习神经网络模型,其通过编码器(Encoder)将输入数据压缩为低维表示,即编码,再利用解码器(Decoder)将其还原为原始形式,即解码,并尽可能减少重构误差(Reconstruction Error)。该模型最初主要用于降维(Dimensionality Reduction)、特征提取(Feature Extraction)、图像去噪(Image Denoising)、图像压缩(Image Compression)、图像检索(Image Search)、异常检测(Anomaly Detection)和缺失值填补(Missing Value Imputation)等。
自编码器模型中的编码器与解码器均为神经网络,其中编码器可表示为一个输入的函数,而解码器则可视为作用在编码层上的通用函数。如图2所示,自编码器由四个主要部分组成:
*编码器(Encoder):将输入数据压缩为低维形式,输出结果构成一个新层,称为编码层。
*编码层(Code/Bottleneck):该层包含压缩后的数据表示,是输入数据的最小维度表达。参考下方公式,其中表示输入样本应用用户定义的函数后的编码层:
*解码器(Decoder):将编码层的低维表示重新构建为输入形式。
*重构损失(Reconstruction Loss):衡量解码器输出与原始输入之间的相似程度,即最终输出的重构效果。公式如下,其中,是对编码层应用第二个通用函数后得到的重构输出:
自编码器的训练目标是最小化输入与输出之间的差异性,如下方公式所示:
编码器和解码器通常由全连接前馈神经网络(Fully Connected Feedforward Neural Networks)组成,其输入层、编码层和输出层都是用户定义的神经网络层。与标准神经网络类似,自编码器也使用如Sigmoid和ReLU等激活函数。目前,自编码器已有多个变体,例如收缩自编码器(Contractive Autoencoder)、去噪自编码器(Denoising Autoencoder)和稀疏自编码器(Sparse Autoencoder)。通常,上述类型的自编码器并不具备生成能力,因为它们只是复制输入而不是生成新数据。然而,变分自编码器(Variational Autoencoder, VAE)是一种具备生成能力的自编码器变体。
2.1.1 变分自编码器
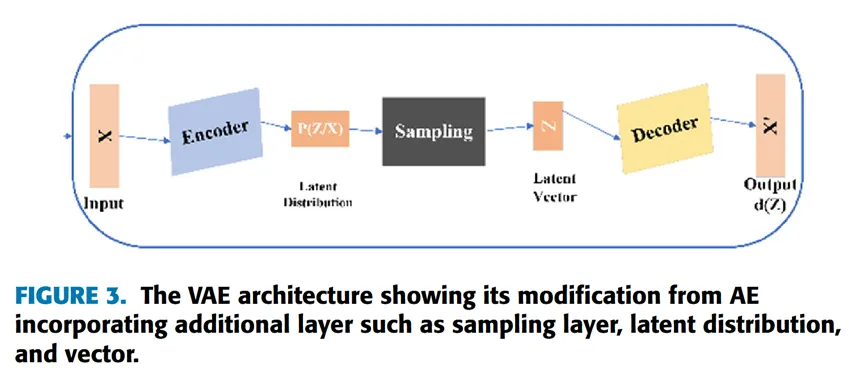
变分自编码器(Variational Autoencoder, VAE)是在 Kingma 等人将变分推断(Variational Inference,一种用于逼近复杂分布的统计技术)引入自编码器后发展而来的,是一种典型的生成模型。其使用变分贝叶斯推断(Variational Bayes Inference),通过概率分布来完成数据生成过程的建模。
与传统自编码器不同,VAE 除了编码器和解码器外,还引入了一个额外的采样层(sampling layer),如FIGURE 3所示。VAE模型的训练过程包括:首先将输入编码为潜在空间(latent space)上的一个概率分布;然后,从该分布中进行采样以生成潜在向量(latent vector);接着对该潜在向量进行解码,计算重构误差,并将该误差通过网络反向传播。在训练过程中,还会显式地引入正则项(regularization),以防止模型过拟合。 VAE中包含了从先验分布 中采样得到的潜在表示(latent representation) ,以及从条件似然分布 中生成的数据 。其中 被称为概率解码器(probabilistic decoder)。在训练推断阶段,模型的目标是学习给定观测数据 时,其潜在表示 的后验分布。后验分布可以通过贝叶斯定理进行精确计算:
但是由于直接求解后验分布 通常不可行,VAE引入了变分推断(variational inference)方法,使用一个可学习的近似分布 来逼近真实后验,即编码器。进一步地,VAE通过最大化对数边际似然的变分下界(Evidence Lower Bound, ELBO)来训练模型,该目标函数如下:
该目标函数由两部分组成:重构项 :鼓励模型从潜在变量 生成的数据能逼近原始输入;KL散度项 :作为正则项,使近似后验不偏离标准正态先验 ,从而保证潜在空间结构良好。
由于 是一个概率分布,无法直接对其进行反向传播。VAE通过引入重参数技巧(reparameterization trick)将采样过程转换为一个可导操作:
其中 和 分别是编码器输出的均值与标准差, 表示元素乘。该技巧使得模型能够端到端训练,从而学习到高质量的生成与编码能力。
完成训练后,VAE生成数据的过程可以用以下公式表示:
即,先从先验分布 中采样一个潜在向量 ,再通过概率解码器 解码生成观测数据 。由此可见,只要学得良好, 与 的组合就可以用于不断生成新的数据样本。