如图所示的是Meta Quest 3头显设备 ,它就搭载了这颗芯片。
戴上头显,抬手点一下悬浮在空中的按钮——就这一个动作,但在头显内部,这一秒钟里同时发生了很多事:多路相机持续进帧、头手位置实时估计、虚实画面叠合、左右眼高刷渲染、Wi-Fi和音频不能掉链子,语音识别、手势识别也可能同时在跑。
这正是头显场景对芯片提出的独特要求:
- 多任务并发,AI只是其中一路:渲染、SLAM(Simultaneous Localization and Mapping,同步定位与地图构建)、传感器处理同时占用芯片资源,让推理在竞争环境中运行。
- 强实时性约束:头显对延迟极其敏感,画面延迟超过几毫秒就会引发眩晕感,手势追踪延迟会破坏交互体验,AI模型必须在严格的时间窗口内完成推理。
- 散热与续航限制:穿戴设备无风扇,被动散热限制持续功耗上限,长时间高负载会导致热降频,影响AI推理的稳定性。
- 内存共享压力大:渲染帧缓冲、AI张量、相机图像流共用同一块LP-DDR5内存,峰值带宽在高负载下容易成为瓶颈。
必须先确认的一件事:HTP 版本
高通内部用HTP(Hexagon Tensor Processor)版本号来区分AI加速后端的能力代际,量化格式、算子融合、QNN编译选项、CPU fallback行为,这些都和 HTP 版本强相关。
XR2 Gen2/QCS8450对应的是 HTP v69——和 Snapdragon 8 Gen1同代。而8 Gen2 是v73, 8 Gen3 是v75,8 Elite已经v79了。
如果你把在 8 Gen2、8 Gen3 上跑得很顺的量化方案直接搬过来,大概率会踩坑。某个精度格式、某个算子融合pattern在v73/v75上成立,不代表在v69也成立。
很多开发者都会踩这个坑:同一套部署方案在Snapdragon 8 Gen2手机上测得好好的,搬到XR2 Gen2头显上却跑不起来,或者性能明显不符合预期。最后排查发现,问题往往不在模型,而在于没有提前确认目标设备的HTP版本、算子支持和量化数据类型约束。我们在LPCV比赛中也因为忽略了W8A16方案对HTP v73的最低版本要求,导致该方案无法直接落地到XR2 Gen2设备上。
HTP 版本搞清楚之后,下一步才是选工具链,把模型真正送上设备。
从模型到芯片,走哪条路
Qualcomm 的这套部署路径,可以概括为从模型到芯片的完整工具链:
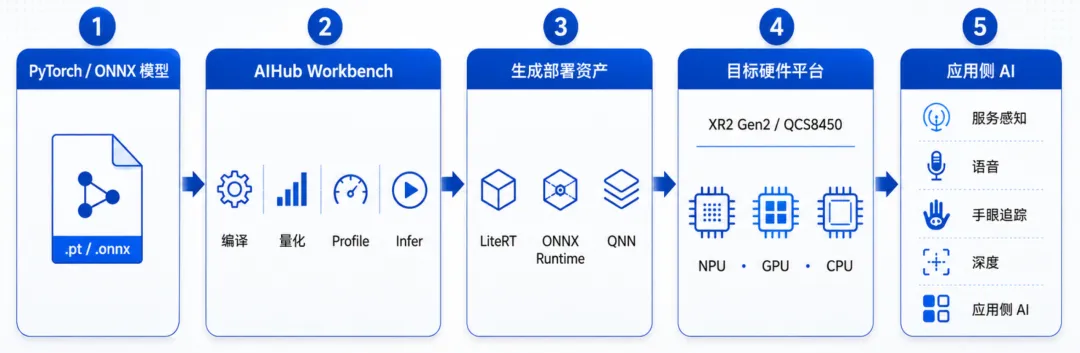
Workbench主要帮你做四件事:把模型转成设备可执行格式(Compile)、生成量化模型(Quantize)、看延迟和NPU利用率(Profile)、做数值对齐(Inference)。在早期验证阶段,用 Workbench 快速判断模型能否在目标设备上跑通、延迟是否在可接受范围内,已经足够。真正集成进产品时,再切换到完整的 SDK 工具链做精细调优。
模型从Workbench出来之后,在设备上通过三条路径执行(runtime):
- QNN / AI Engine Direct:是⾼通⾃家的底层运⾏时,直接控制NPU,也是另外两条路径的底层依赖。常见资产中,QNN DLC偏硬件无关,适合后续做链接和最终化;QNNcontext binary 面向特定SoC,设备特异性更强,更接近最终部署形态。
- LiteRT(TFLite):适合 Android 移动端快速集成,是现有 Android 项目的最短路径。
- ONNX Runtime + QNN EP:更适合跨平台项目:通过 QNN SDK/QAIRT把ONNX 图交给Qualcomm CPU/GPU/HTP后端执行,在Android/Linux/Windows上均可使用。
模型上了设备之后,还需要接入App的实际pipeline:初始化运行时、绑定相机buffer、处理线程调度等。这部分不在Workbench的覆盖范围内,需要通过QNN SDK或对应runtime的C++ API自行集成。
早期demo先选最快跑通的,产品阶段再根据NPU placement(算子放置策略)、版本可控性、失败复现成本来决定。
量化之后反而更慢?
我们在LPCV的比赛中需要处理CLIP模型的量化部署,它的Image部分就是一个Vision Transformer(ViT),但在我们比赛中发现了一个有趣的现象:量化之后,模型反而更慢了,这是什么原因呢?
我们通常认为量化是把float32压成int8,模型更小,所以推理更快。
前半句通常没错。后半句不一定。
在ViT上验证时,输入224×224的图片,86.6M 参数,float模型约330MB,w8a8量化后压到83.2MB,Top-1精度基本没掉(约81.1%)。
在 QCS8450 Proxy 上实测:
w8a8+TFLite组合,延迟从13ms涨到了20ms,内存反而更高。同样是w8a8,换成QNN DLC,延迟又几乎回到float水平。
这说明量化不自动等于加速,同一个模型、同一个精度,换runtime可能完全是另一条执行路径。
为什么会这样?
ViT 量化之后变慢,通常几个地方先查:
- Q/DQ 节点的开销。 QDQ量化会在图里插大量 Quantize/Dequantize边界,requantization处理进入关键路径,INT8的收益被抵掉。这里大家可以依靠netron看看量化后图里多了多少Q/DQ节点,从而更好判断量化方案是否合理。
- 算子融合被切断。 后端本来可以把相邻算子融合成更紧的执行pattern,Q/DQ一插进去,能一起做的计算被拆成几段。
- GELU 展开。 ViT MLP里常见
Linear→GELU→Linear,导出ONNX后GELU经常展开成Erf/Tanh/Add/Mul/Div子图,比Gemm→ReLU难融合得多。所以我们在LPCV比赛中就采用了将Gelu替换成ReLU的方式来实现了大范围的提速。
在实际芯片使用时,模型包大小、加载时间、峰值内存本身都影响用户体验,所以对于选择合适的量化方法、runtime、算子融合策略,需要综合考虑。
几个判断顺序
结合上面Qualcomm的软硬件结构的介绍,我们需要知道在实际部署时应该按什么顺序来排查和决策:
第一步,确认 HTP 版本。 查目标设备 HTP 版本(XR2 Gen 2 = v69),找对应版本的文档,HTP 版本决定量化格式兼容性和算子支持范围;v69 ≠ v73/v75,直接复用手机方案大概率踩坑
第二步,分 runtime 测。 TFLite、QNN DLC、ONNX Runtime+ QNN EP可能是完全不同的后端路径,同一套量化方案表现差异可以很大。
第三步,再谈量化。 量化后分别测模型体积变化和推理延迟变化,不要混为一谈,量化首要价值是减小模型/内存占用;延迟是否下降需实测,延迟上升时查Q/DQ overhead和算子融合断裂。
第四步,真机整机验证。 在渲染、相机、SLAM同时运行的整机负载下测延迟稳定性。
最终效果是:SoC后端×HTP版本×runtime×模型图结构×校准数据×整机并发负载,每一环都可能把前一步的结论推翻。只有这样一步步深入,我们才能真正实现将模型量化部署到XR2 Gen2 的目标。
欢迎关注流光AI笔记文案 | 杜金阳排版 | 徐子骞


