《AI启智之旅》•卷一
《“机器学习”算法笔记》
第十四单元:图解线性学习算法(2)
AI 从概念诞生到如今蓬勃发展,机器学习拉开了智能时代序幕,深度学习让机器能处理海量复杂数据。大模型加上超强算力的飞速发展,让 AI 看上去仿佛拥有了自我意识,产生逼真的 “智能幻觉”。但抛开表象看本质,AI 并不会真正思考,只是在海量数据里寻找隐藏规律、调试庞大参数,靠超高概率去猜下一个文字是什么、分辨眼前图像属于哪一类,这就是所有人工智能能力的底层逻辑。
现代AI技术就是调试超高维度学习参数,最终以概率推演的核心逻辑,高精准预测自然语言的下一个字符、判别机器视觉里的图像类别。有效高质量数据源才是现有技术条件下AI持续演化的动力源泉。
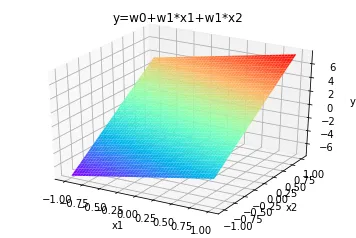
线性学习算法中的y=w0+w1*x模型实际上就是个“大模型宝宝”,对其进行参数(w0,w1)扩充,来应对不同数量的特征(x),依据已有数据完成最小乘方误差学习后,利用得到的参数就可以根据新的特征预测y值。这里的特征x可以是sin(x),x2,x100,只要参数和特征保持点乘模式,都是线性模型。
图14-1线性模型例子到这里你的直觉可能是模型中特征x的次数越高越好,越能契合数据规律。这种直觉也对也不对,可以用事实推理来改进这种直觉。
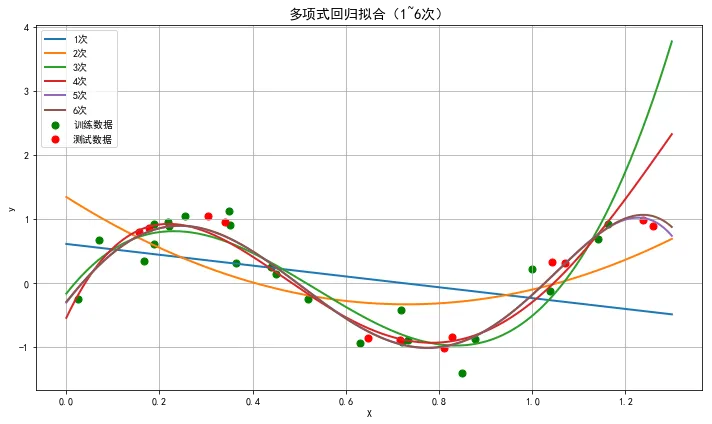
利用sin(2Πx)外加高斯分布随机数分别生成24个训练用数据(绿点标注)和12个测试用数据(红点标注),分别对1到6次项多项式进行学习拟合,分别比对不同多项式模型拟合的训练误差和预测的测试误差。
- 利用sklearn中的PolynomialFeatures生成多项式;
- 用sklearn.linear_model.LinearRegression针对24个训练用数据完成学习;
- 用sklearn.metrics.mean_squared_error分别计算训练误差和测试误差。
从结果中可以看出随着多项式次数的增加,对于训练数据拟合的效果越来越好(也就是训练误差逐渐达到最小),但是对于新的特征测试数据,却没有达到最小的测试误差(也就是对于新数据的预测能力并没有变好,反而变差),这种情况称为“过拟合”。
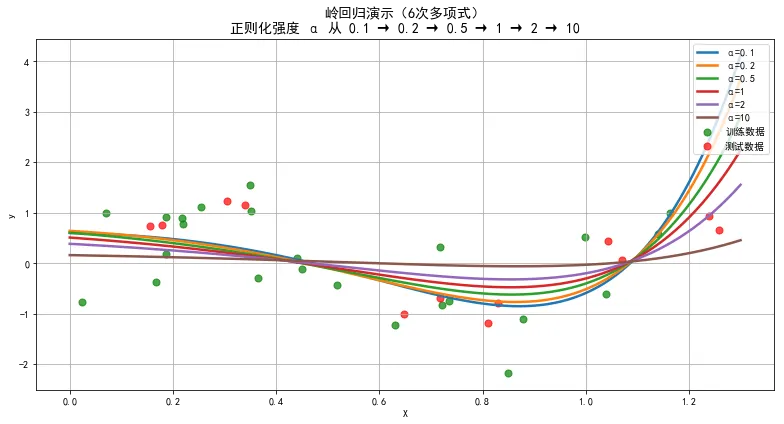
图14-2多项式回归一般使用岭回归算法(对应于sklearn.linear_model.Ridge)来纠正这种过拟合问题。即在模型中添加a*[w02+w12+w22+w32+...]学习项,纠正的强度a(也称正则化强度)需要根据数据情况自行设定。针对上批数据,a=2达到最佳。
图14-3岭回归推荐使用jupyter notebook(其程序文档为ipynb安装Anaconda就可以获得)来完成python机器学习的小规模程序开发,小小草稿模式,所加即所得。
所有数据和源码在网盘共享,算法的源码实现有任何问题,欢迎指正。
https://pan.baidu.com/s/1fPyYkznICkhHMBFRAPZYgw=FATM
2026年5月13日于江苏启东