GaussDB学习笔记之时间点恢复(PITR)
- 2026-04-22 22:55:00

在数据库运维中,误删数据、逻辑错误或系统故障是难以完全避免的风险。除了定期全量备份外,能够将数据库恢复到故障前任意一秒的能力至关重要。这就是时间点恢复(Point-In-Time Recovery,简称PITR)。GaussDB基于WAL(Write-Ahead Logging)机制提供了强大的PITR能力,支持将实例、库或表恢复到指定时间点。本文将解析PITR的原理、前提条件及操作流程。
一、什么是PITR?
PITR是一种数据库恢复技术,允许用户将数据库状态回滚到过去的任意特定时刻(精确到秒)。
核心原理:
数据库定期执行基准备份(Base Backup),保存某一时刻的全量数据文件。 开启WAL归档(Archive Logging),将基准备份之后产生的所有事务日志(WAL日志)持续保存到外部存储。 恢复时,先还原基准备份,再按顺序重放(Replay)WAL日志,直到达到用户指定的目标时间点为止。
公式化表达:目标状态 = 基准备份+(起始时间~目标时间)的WAL日志重放
二、PITR的前提条件
要成功执行PITR,必须满足以下三个硬性条件:
已存在有效的基准备份必须至少有一次完整的物理备份(全量备份),作为恢复的起点。 开启了WAL日志归档数据库参数archive_mode必须为on,且配置了正确的archive_command,确保WAL日志被实时复制到安全的归档目录或对象存储中。若归档中断,则中断期间的时间点无法恢复。 目标时间在有效范围内恢复的目标时间点必须位于基准备份完成时间之后,且小于最新归档日志的截止时间。不能恢复到基准备份之前的时间,也不能恢复到归档日志缺失的时间段。
三、GaussDB中的PITR应用场景
GaussDB支持多种粒度的PITR恢复:
实例级恢复将整个数据库实例恢复到指定时间点。适用场景:实例崩溃、大规模误操作(如误删表空间)、勒索病毒攻击。注意:恢复过程中实例不可用,通常会创建一个新实例或覆盖原实例。 库/表级恢复仅恢复指定的数据库或数据表到指定时间点,不影响其他业务。适用场景:单表误删、局部数据污染。限制:需GaussDB特定版本支持(如V2.0-3.200及以上),且单副本实例通常不支持。 租户级恢复(多租户模式)在分布式多租户架构下,独立恢复某个租户的数据。
四、PITR恢复流程详解
以手动执行实例级PITR为例,标准流程如下:
步骤1:停止数据库服务确保目标实例处于关闭状态,防止数据写入干扰恢复过程。
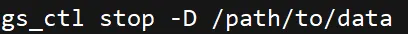
步骤2:准备基准备份文件将最近一次全量备份的数据文件拷贝到数据目录(PGDATA)。注意:需清空当前数据目录(或重命名备份),确保目录纯净。

步骤3:配置恢复参数在数据目录下创建恢复信号文件(如recovery.signal),并编辑配置文件(如postgresql.auto.conf或recovery.conf),指定目标时间。关键参数示例:

步骤4:启动数据库进行恢复启动实例,数据库会自动进入恢复模式,拉取归档日志并重放,直到达到指定时间。

日志中会显示如下类似信息:

步骤5:验证数据恢复完成后,检查数据是否回到预期状态,确认业务正常。
五、云环境下的PITR(华为云GaussDB)
在使用华为云GaussDB服务时,PITR操作更加简化,无需手动处理文件:
控制台操作:在“备份恢复”页面,选择自动备份记录,点击“恢复到新实例”或“恢复到当前实例”,输入具体时间即可。 限制说明: 仅支持V2.0-2.1以上版本; 单副本实例不支持; 节点扩容、版本升级期间产生的断档时间无法恢复; 恢复到当前实例会覆盖现有数据,需谨慎操作。
六、注意事项与最佳实践
归档存储安全WAL归档文件应存储在独立于数据库主机的存储介质上(如NFS、对象存储OBS),防止主机故障导致日志丢失。 时间同步数据库服务器时间必须准确(建议配置NTP),否则recovery_target_time可能偏差。 测试演练定期在测试环境进行PITR演练,验证备份和归档的有效性,避免“备份成功但恢复失败”的悲剧。 保留策略根据业务合规要求,设置合理的归档保留期限(如7天、30天),避免磁盘爆满。 性能影响开启归档会轻微增加写操作延迟(需等待日志复制完成),但在可接受范围内。
七、总结
PITR是数据库灾难恢复的最后一道防线,它将恢复粒度从“天”提升到了“秒”。GaussDB通过结合基准备份与WAL归档,实现了灵活、可靠的时间点恢复能力。无论是自建集群还是云服务,掌握PITR原理与操作,都能在面对误删、篡改或故障时,从容应对,最大程度减少数据损失。
备份不是目的,恢复才是。只有经过验证的PITR流程,才是真正可信的数据保障。
以上内容均为本人学习GaussDB备份恢复机制过程中,结合官方文档与实操经验所做的个人总结,初衷是希望能为同路学习者提供一点参考和帮助。内容仅作交流学习之用,若有疏漏或不当之处,欢迎大家指正交流。
本文由le就这样吧原创发布于社区,未经作者许可,禁止转载。 个人观点,仅供参考。