Unidbg学习笔记(六):补环境的思维框架
- 2026-04-17 19:15:53
补环境不是"遇到报错就查答案",而是"你在扮演 Android 系统回应 SO 的请求"。一旦建立这个思维模型,大部分补环境问题都可以靠推理直接解决。
上一篇把你留在了哪里
第五篇结束时,你应该已经能跑通一个最简单的 SO 了。但回想一下整个过程,你的工作模式是:
跑 → 看报错 → 在 switch 里加一个 case → 跑 → 看报错 → 加一个 case → ...
这是被动模式。你像是一个考生,面前是一张永远做不完的填空题:题目(报错)一个个出现,你一个个去找答案。报错没出现的时候你不知道下一个会是什么;报错出现了你才反应;如果报错的位置出乎意料,你就懵。
被动模式有两个根本性的问题:
问题 1:你永远在追 SO 的脚步,而不是预判它
复杂的 SO 可能会调几十甚至上百个 JNI 函数。如果你完全靠"撞墙"来发现它需要什么,那这一百次试错都得跑完,你才知道全貌。
问题 2:你不知道一个返回值"对不对"
报错消失了,不代表你给的回答是对的。getDeviceId 你随手返回一个 "123456",SO 不会立刻报错 — 但 SO 算签名时把这个 ID 拌进去了,最终签名和真机不一致,你完全不知道是哪一步出了问题。
所以你需要从被动模式切换到主动模式。这就是这一篇要讲的事情。
重新定义"补环境":你是 Android 系统的替身演员
一个观念上的彻底重构:你不是在调试一段 Java 代码,你是在扮演一个角色。
具体地说:当 SO 在 Unidbg 里运行时,它认为自己跑在一台真实的 Android 手机上。它会向"操作系统"提各种各样的问题:
"屏幕多高?" "现在几点?" "我所在 App 的包名是什么?" "/proc/self/cmdline 里写的什么?" "请给我一个 256 字节的内存。"
在真机上,这些问题由 Android 操作系统来回答 — Linux 内核 + ART 虚拟机 + Framework Service。在 Unidbg 里,这些回答的责任落到了你头上。你不是在"调代码",你是在用代码模仿一个完整的 Android 系统。
打个比方:补环境像在拍电影。SO 是主演,剧本是它原本的执行流,背景是 Android 系统。Unidbg 给了你一个空的摄影棚和一些基础道具(30% 的系统调用、JNI 表外壳),但其它一切场景都得你来搭。SO 走到一面墙前要"开门",你就得在墙后面准备一个"另一个房间"。SO 抬头要看"窗外的太阳",你就得举一个手电筒。演得好不好,取决于你能不能预判 SO 想看到什么。
这个心智模型一旦建立,几件事会立刻变得清晰:
**你不是在"修复 bug",你是在"提供服务"**。报错不是错误,是 SO 在向你提问。 **你的回答有"对错",不只有"通过/失败"**。返回一个能让流程继续的值很容易,返回一个让最终结果正确的值才是真本事。 你可以通过"理解 SO 需要什么"来预判,而不必完全靠撞墙。
四层响应模型:SO 的四种外部交互
把"扮演 Android 系统"具体化,就要回答一个问题:SO 到底会向系统提哪些类型的问题?
答案是四种。所有补环境工作都落在这四种之一。
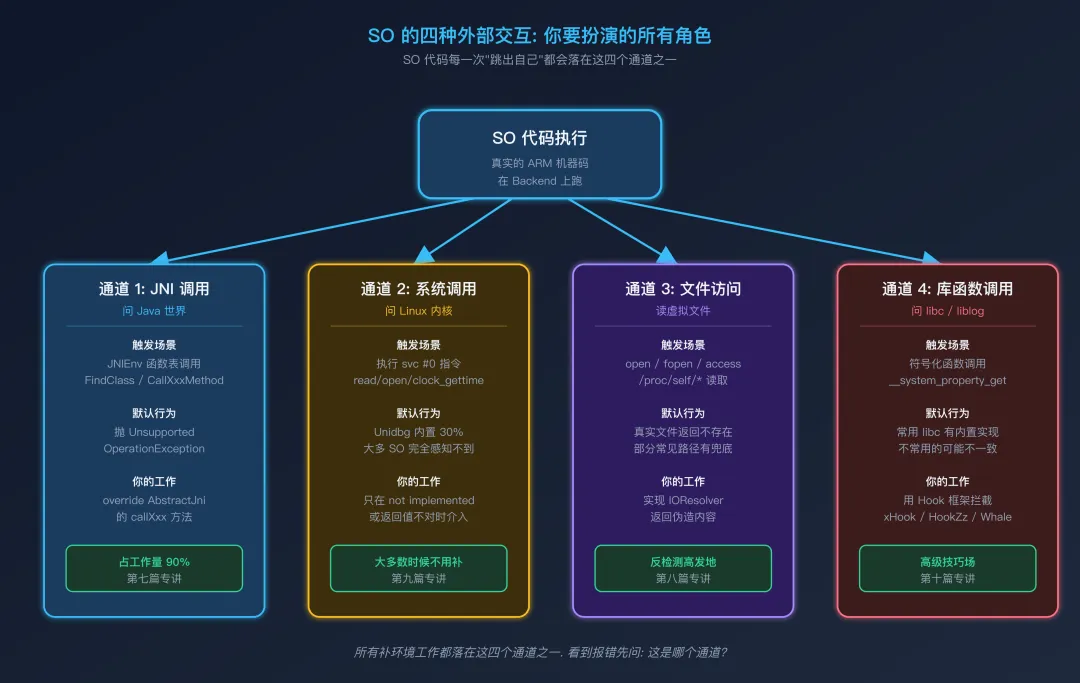
通道 1:JNI 调用 — 与 Java 世界对话
触发场景:SO 通过 JNIEnv 函数表调用任何 Java 方法或字段。
典型例子:
// SO 代码jclass settingsClass = (*env)->FindClass(env, "android/provider/Settings$Secure");jmethodID m = (*env)->GetStaticMethodID(env, settingsClass, "getString", "(...)Ljava/lang/String;");jstring androidId = (*env)->CallStaticObjectMethod(env, settingsClass, m, contextResolver, "android_id");Unidbg 默认行为:抛 UnsupportedOperationException,把签名告诉你。
你的工作:在 AbstractJni 子类里 override 对应的 callXxx / getXxxField / resolveClass。
**这一类占工作量的 90%**。第七篇会专门讲它。
通道 2:系统调用 — 与 Linux 内核对话
触发场景:SO 代码(或它调用的 libc 函数)执行 svc #0 指令。
典型例子:
// libc 函数最终都会落到一条 svc 指令structtimespects;clock_gettime(CLOCK_REALTIME, &ts); // → svc #0, NR=__NR_clock_gettimeUnidbg 默认行为:内置了约 30% 的常见系统调用实现(read、write、open、mmap、clock_gettime 部分分支等)。大部分时候 SO 跑这些 syscall 你完全感知不到。
你的工作:只在 Unidbg 报 not implemented 或者你怀疑某个 syscall 返回值不对时介入。第九篇会专门讲。
最重要的认知:JNI 是"Unidbg 把球抛给你",syscall 是"Unidbg 试着自己接球,没接住才抛给你"。这两类问题的心态完全不同。
通道 3:文件访问 — 读取虚拟文件系统
触发场景:SO 通过 open() / fopen() / access() 访问文件路径。
典型例子:
// 反调试: 读 /proc/self/status 检查 TracerPidFILE *fp = fopen("/proc/self/status", "r");char line[256];while (fgets(line, sizeof(line), fp)) {if (strncmp(line, "TracerPid:", 10) == 0) {int tracerPid = atoi(line + 10);if (tracerPid != 0) exit(1); // 检测到调试器 }}Unidbg 默认行为:对真实文件返回"不存在";对部分常见路径(/proc/self/cmdline、/proc/self/maps)有兜底实现。
你的工作:实现一个 IOResolver,对 SO 关心的路径返回伪造的内容。第八篇会专门讲。
通道 4:库函数调用 — 截获 libc 之外的细节
触发场景:SO 调用 libc.so / liblog.so / libdl.so 中的具体函数(不是直接 svc,而是带函数符号的调用)。
典型例子:
char prop[PROP_VALUE_MAX];__system_property_get("ro.build.version.sdk", prop); // 读 SDK 版本Unidbg 默认行为:libc 的常用函数(malloc、memcpy、strlen 等)有内置实现;不常用的可能未实现,或行为与真机不一致。
你的工作:用 Hook 框架(xHook / HookZz / SystemPropertyHook)拦截。第十篇会专门讲。
优先级原则:能不补就不补
四个通道理论上都需要响应,但实践中响应的顺序不应该是平摊的。这里有一条非常关键的原则:
最小化干预原则:能让 Unidbg 默认处理的事情,绝对不要手动干预。
理由有三:
理由 1:你写的代码一定不如 Unidbg 的实现完整
Unidbg 内置的 syscall 实现处理了大量边界情况(参数校验、错误码返回、相关 fd 状态更新)。你随手写一个 hook 替换掉它,很可能漏掉某个细节,导致后面的执行流偏离。
理由 2:你写的代码会成为新的 bug 来源
每补一个 case,你就引入了一个潜在的 bug 点。一年后回头维护时,你可能根本不记得当时为什么这样补,但移除它又怕崩。代码量越少,长期维护越容易。
理由 3:过度干预会掩盖真正的问题
最危险的情况:你 hook 了一个实际上 Unidbg 处理得很好的函数,把它换成你自己的实现,结果遮蔽掉了一个真正的问题(比如某个返回值在 Unidbg 默认实现里是对的,你重写后是错的)。这种 bug 极难定位。
一个具体的例子
假设 SO 调用 gettimeofday(),你想"补一下"让它返回固定值。两种做法:
做法 A(过度干预):在 AbstractJni 里全局 hook gettimeofday 系统调用,每次都返回固定时间戳。
做法 B(最小干预):什么都不做,让 Unidbg 用内置实现(返回宿主机系统时间)。如果发现签名结果和 Frida 不一致,再回头处理。
90% 的情况下,做法 B 是对的:很多 SO 用 gettimeofday 是为了打日志或者算时间戳偏移,不影响最终结果。你 hook 了反而引入了一个潜在的失败点。
优先级口诀
记一个简单的口诀:
跑、看、判、补、验
跑:先让 Unidbg 自己跑 看:跑不动时看报错 判:判断报错属于哪一层 补:只补必须补的那一行 验:补完之后立刻验证还能不能跑
每个环节都对应一个明确的动作,不要跳步。最常见的错误就是省略"跑"和"看",直接进入"补" — 结果补了一堆 SO 根本不调用的方法。
决策树:补什么值
OK,假设你判断出了"这是一个 JNI 调用,需要 override callObjectMethodV,方法签名是 xxx"。下一个问题是:应该返回什么值?
这是补环境最让新手头疼的问题。这里给一棵决策树。
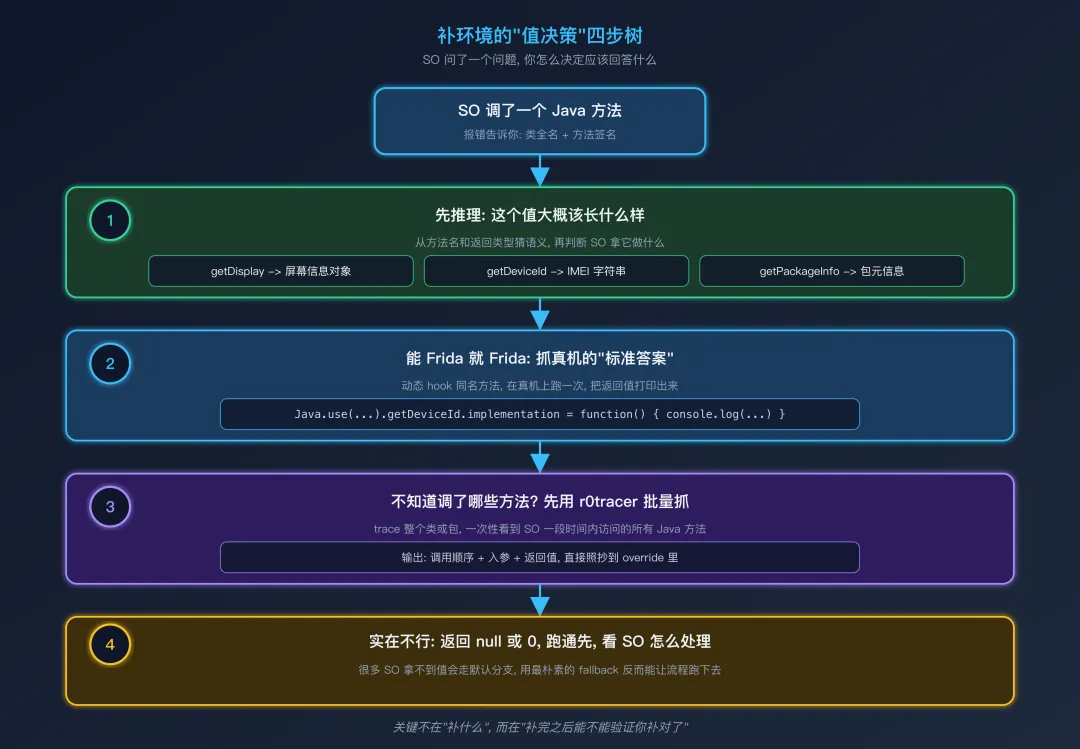
Step 1:方法名 / 字段名能看懂含义吗?
90% 的方法名是有语义的:
Display->getHeight()I | 19202400(主流分辨率) | |
Display->getWidth()I | 10801440 | |
Build->VERSION_RELEASE | "11""12" | |
TelephonyManager->getDeviceId() | ||
PackageManager->getPackageName() | ||
Settings$Secure->ANDROID_ID |
只要方法名能看懂含义,就直接推理一个合理值返回。不需要查任何资料。
具体代码模式:
case"android/view/Display->getHeight()I":// 屏幕高度, 主流 Android 设备 1920 或 2400, 这里给个中等值return1920;case"android/os/Build$VERSION->RELEASE:Ljava/lang/String;":// Android 版本号, App 通常用它判断 API 兼容性returnnew StringObject(vm, "11");Step 2:方法名看不懂时,去真机查
看不懂的情况主要有两类:
类型 A:方法名混淆了
case"com/example/obfuscated/aB->c()Ljava/lang/String;":// ??? 方法名是单字母, 完全看不出含义类型 B:方法名能看懂但你不确定真机返回什么
case"android/os/Build->FINGERPRINT:Ljava/lang/String;":// 指纹字符串, 不同设备格式不一样, 不能瞎猜这两种情况都用同一个解决方案:Frida hook 真机,把真实返回值复制下来。
// 简洁的 Frida 模板Java.perform(function () {// 类型 A: 直接 hook 那个混淆方法var aB = Java.use("com.example.obfuscated.aB"); aB.c.implementation = function () {var ret = this.c();console.log("[+] aB.c() = " + ret);return ret; };// 类型 B: 直接读字段var Build = Java.use("android.os.Build");console.log("FINGERPRINT = " + Build.FINGERPRINT.value);});跑一次目标 App,把控制台输出的值复制到 Unidbg 的 case 里。不要瞎猜不可推理的值。
Step 3:补的字段太多时,用 r0tracer 批量获取
如果一个类有几十个字段需要补(典型情况:Build、TelephonyManager),一个个 Frida 太慢。这时用 r0tracer 批量 Trace:
// r0tracer 用法 (简化, 实际配置项更多)var config = {name: "android.os.Build",is_blacklist: false,fields: true, // 同时打印字段值methods: true// 同时打印方法返回值};跑一次,控制台会输出 Build 类的所有字段当前值和所有方法的返回值。把日志保存下来,需要哪个直接复制粘贴。
小技巧:r0tracer 默认会打印每个字段访问的调用栈,输出会非常长。在配置里关掉 stack trace(
stack: false),日志会清爽很多。第七篇会展开讲 r0tracer 的具体用法。
Step 4:怎么补都不影响时,返回 null
有些方法是 SO 的"非关键路径",它调用了,但你返回 null 它也能继续跑。这种情况直接 return null:
case"com/example/SomeAnalytics->log(Ljava/lang/String;)V":// 这是个埋点上报方法, 返回 void, 跟核心逻辑无关 System.out.println("[NULL-CALL] " + signature);returnnull;判断一个方法是不是"非关键路径"的简单办法:先返回 null,跑一遍。
如果 SO 继续跑且最终结果正确 → 这就是非关键路径,永远 null 如果 SO 崩溃或结果错误 → 关键路径,回头按 Step 1-3 补
这是最经济的补环境策略。绝大多数 App 的 SO 里都有大量埋点、日志、analytics 调用,它们对核心算法没有任何影响。如果你在每一个上面都花时间研究真机返回值,你会浪费 80% 的精力。
推理示范:从"查"到"想"
让我们用三个真实场景,演示"主动推理"和"被动查询"的差异。
场景 1:屏幕信息
报错:
UnsupportedOperationException: android/view/WindowManager->getDefaultDisplay()Landroid/view/Display;被动模式(菜鸟做法):
"Display? 这是什么?我去 Stack Overflow 搜一下 WindowManager.getDefaultDisplay 怎么用..."(半小时过去)
主动模式(推理做法):
它是什么: getDefaultDisplay返回Display对象 → SO 八成是要拿屏幕信息接下来 SO 会做什么:拿到 Display 后会调 getWidth/getHeight/getRefreshRate之类我需要做什么:返回一个 Display 占位对象,等下一个报错再决定具体补什么字段
case"android/view/WindowManager->getDefaultDisplay()Landroid/view/Display;":// 返回一个 Display 占位, SO 接下来会调 getWidth/getHeight, 到时候再补return vm.resolveClass("android/view/Display").newObject(null);跑一次。果然,下一个报错是 Display->getRealMetrics(DisplayMetrics)V。继续推理:DisplayMetrics 是一个数据容器,会被 SO 读取里面的 widthPixels / heightPixels 字段。再补 getObjectField。整个推理过程不超过 5 分钟,不需要查任何资料。
场景 2:包签名
报错:
UnsupportedOperationException: android/content/pm/PackageInfo->signatures:[Landroid/content/pm/Signature;主动推理:
它是什么: PackageInfo.signatures是 App 的签名信息数组SO 为什么读它:99% 概率是做"包签名校验" — 算签名 hash 和硬编码值对比 如果我返回一个空数组:SO 拿到 0 长度的数组,可能崩溃或者认为校验失败 → SO 拒绝继续算签名 我需要怎么做:返回 1 个 Signature 对象,里面是真实 APK 签名 byte
到这一步你已经知道下一步是"从 APK 里提取真实签名 byte 装进去"。具体提取方法可以查(apksigner verify --print-certs),但整个分析过程是推理出来的,不是查到的。
场景 3:IMEI
报错:
UnsupportedOperationException: android/telephony/TelephonyManager->getDeviceId()Ljava/lang/String;主动推理:
它是什么:IMEI,15 位数字 SO 为什么要它:99% 概率作为设备唯一标识,参与签名/加密计算 能不能瞎写一个 15 位数字:不能。因为 Frida 在真机上跑同样入参时,SO 用的是真机 IMEI。两边 IMEI 不一致 → 签名结果不一致 → 你的对照验证会失败
结论:必须用 Frida 抓真机 IMEI,复制到 Unidbg 里:
case"android/telephony/TelephonyManager->getDeviceId()Ljava/lang/String;":// 必须用真机 IMEI, 否则签名结果不会和 Frida 抓的一致returnnew StringObject(vm, "861234567890123"); // 从 Frida 抓的真值这就是推理的力量:你不是机械地补 case,你在每一步都问自己"SO 为什么需要这个?我返回的值会不会影响最终结果?"
真正危险的:补错了不知道
到这里你应该理解:不会补不可怕,怕的是补错了你不知道。
补错的形式有几种:
形式 1:返回值类型对,但内容错
case"android/os/Build->MODEL:Ljava/lang/String;":returnnew StringObject(vm, "MyDevice"); // ← 类型对, 但 SO 期望的是真实机型字符串SO 不会因此报错(它接到一个非空字符串就继续往下跑),但如果"机型"参与了签名计算,最终结果会和 Frida 不一致 — 这种 bug 极难定位。
形式 2:返回值"看似合理"但语义错
case"android/content/pm/PackageManager->getPackageInfo(Ljava/lang/String;I)Landroid/content/pm/PackageInfo;": {// 返回了 PackageInfo 占位return vm.resolveClass("android/content/pm/PackageInfo").newObject(null);}但是 — getPackageInfo 的第二个参数是 flags。如果 SO 传的是 GET_SIGNATURES(值 64),SO 期待 PackageInfo.signatures 字段被填充;如果 SO 传的是 GET_META_DATA(值 128),SO 期待 metadata 字段被填充。你忽略了 flags 的语义,直接返回一个空对象,SO 后续读字段时就会拿到错的值。
形式 3:补了 SO 根本不调用的方法
这个不会引起 bug,但是浪费精力。你研究了半天 getNetworkOperatorName 的真机返回值,结果跑下来 SO 根本没调它。
如何避免补错
方法 1:每次补完立刻和 Frida 对照
第五篇结尾强调过这一点。一个最朴素但最有效的工作流:
publicstaticvoidmain(String[] args){ SignDemo demo = new SignDemo();// 用同一组入参跑 String unidbgResult = demo.callSign("test_input"); String fridaResult = "ad9f8a7c..."; // 从 Frida 抓的标准答案if (unidbgResult.equals(fridaResult)) { System.out.println("[OK] 完全匹配"); } else { System.out.println("[FAIL] Unidbg=" + unidbgResult); System.out.println(" Frida= " + fridaResult);// 这时候你知道某个补的值有问题, 二分法回退最近补的几个 case }}方法 2:从 Frida 抓多组样本
只用一组入参对照容易"巧合通过"。建议至少抓 3-5 组不同入参的真机结果。3 组都对 → 你补的环境基本是对的;任何一组对不上 → 还有问题。
方法 3:开 verbose 日志,对比两边的 JNI 调用序列
把 Unidbg 和 Frida 在同一组入参下的 JNI 调用日志都打印出来,做 diff。如果两边的调用序列一致 → 补环境正确性高度可信;如果某一步 Unidbg 有调用而 Frida 没有 → 说明你的某个补的方法触发了一个本不该走的分支。
// Unidbg 这边开 verbosevm.setVerbose(true);// 输出会包括每一次 JNI 调用 + 参数 + 返回值// Frida 这边写一个全局 hook 记录所有 JNI 调用Interceptor.attach(Module.findExportByName(null, "JNI_OnLoad"), {onEnter: function (args) {// 这里可以挂一个全局 JNI 日志, 略 }});把两边日志做 diff,差异点就是你需要重点查看的地方。
心智模型小结
把这一篇的核心思想压缩成几句话:
你不是在调代码,你是在扮演 Android 系统 SO 的所有外部交互只有四种:JNI / syscall / 文件 / 库函数 能让 Unidbg 默认处理的就不要手动补(最小干预原则) 看到方法名先推理含义,推理不出来再查 Frida 跑通不等于跑对,每次补完都要和 Frida 对照 危险的不是不会补,是补错了不知道
这六条加起来,构成了一套可以主动思考的工作流。你不再是被报错牵着走,你预判 SO 需要什么、判断哪些值是关键、决定哪些可以省力。
类比一次:被动模式下你像在做迷宫,拿手电筒一格一格摸;主动模式下你像在开飞机,事先看了地图,知道目的地在哪,途中只是不时校准航向。前者是体力活,后者才是工程师的工作。
总结:从填空题到角色扮演
这一篇没讲新 API、没演示新代码,只重构了一个观念:补环境是角色扮演,不是填空。
如果你能把这个心智模型用熟,下面几篇会变得顺畅很多:
第七篇会带你深入 JNI 层补环境的具体技巧 — 但有了这一篇的框架,那些技巧不再是孤立的"招式",而是同一套思想下的具体实现 第八篇讲文件系统补环境,会反复用到"最小干预"和"推理含义"的原则 第十一篇讲初始化问题,那是这套思维框架的极致考验 — 因为初始化函数的报错往往是"返回值是空",没有 stack trace 给你看
带着"我是 Android 系统的替身演员"的心态去读后面的内容,你会发现一切都顺了起来。

