前面基于RLHF(基于人类反馈的强化学习)中的PPO算法训练了一个mini版InstructGPT。
此处学习RLHF中的DPO算法并基于此方法微调Qwen2.5-0.5B模型。
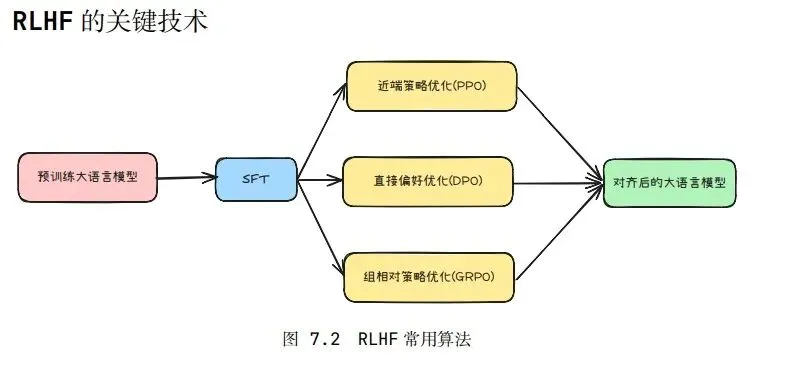
整体流程
DPO(Direct Preference Optimization,直接偏好优化)算法虽然归类于RLHF,但是却没有奖励模型和强化学习。
使用传统的监督学习技巧来实现微调。

上述推导环节中用到的Bradley-Terry 公式用来建模成对的公式。

由上述公式可知,基于偏好数据集最小化损失函数就能取得较优的策略。
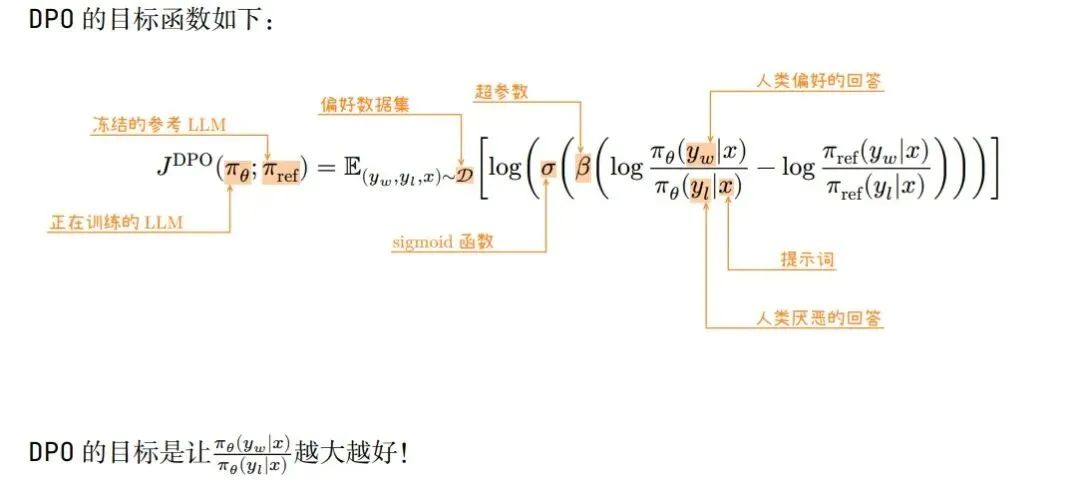
使用DPO微调的大致流程如下:先微调基础模型,在此基础上使用DPO算法继续优化。
此处学习案例选用Qwen2.5-0.5B作为基础模型。
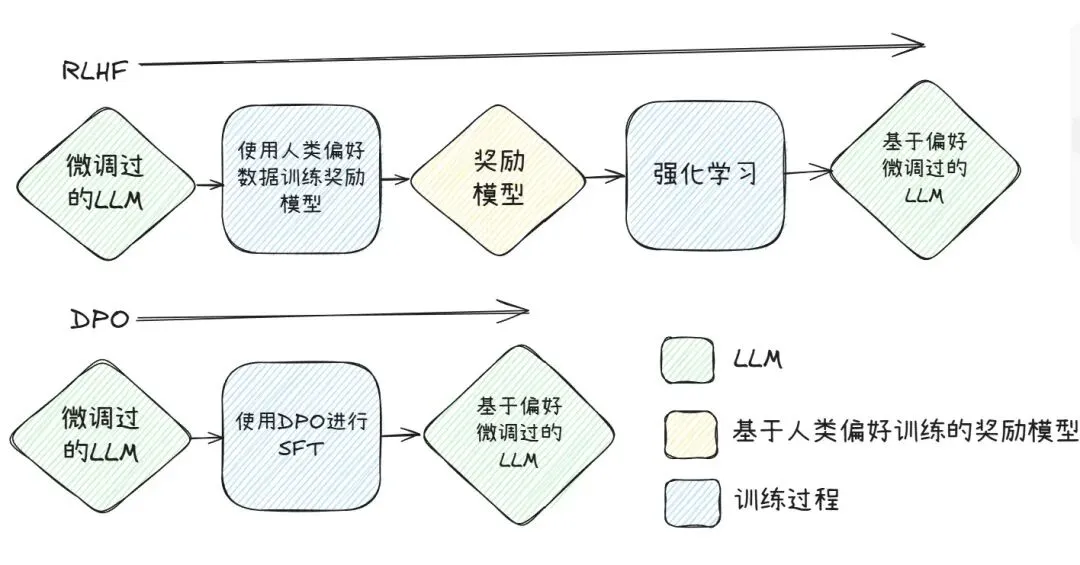
实现细节
数据集
SFT数据集:https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k
数据集messages列为多轮对话。
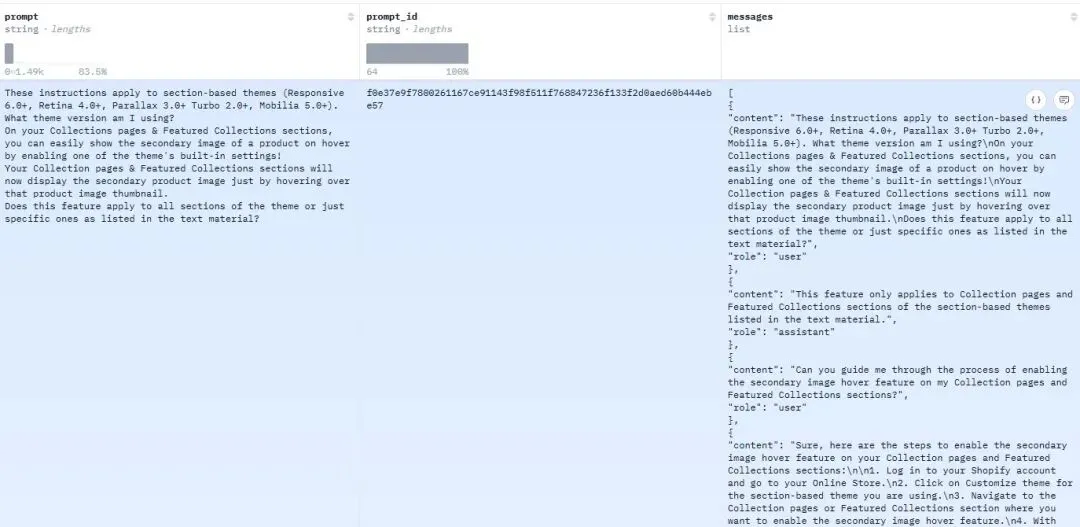
DPO数据集:https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized
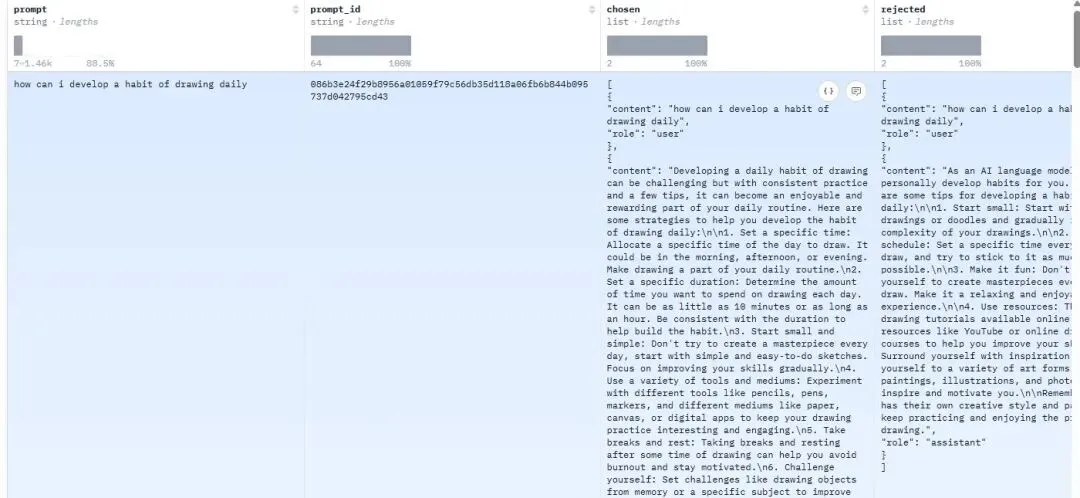
数据集中chosen列为偏好回答,rejected列为非偏好回答。
损失计算
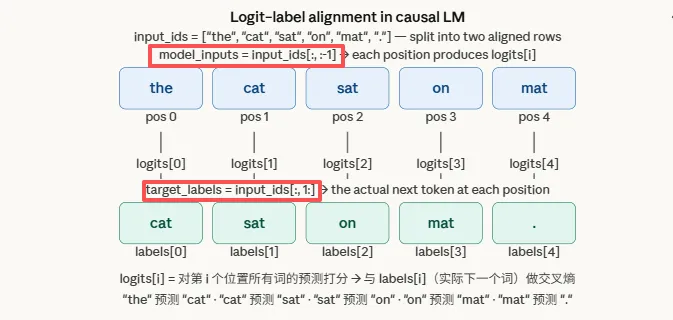
将数据集中的文本错位一位构成输入与标签:输入取 [:-1],标签取 [1:],构成输入-标签自回归数据集。
 img
img完整输入序列传给模型使得模型理解上下文,但是计算损失时均只考虑模型的回答部分。
即从数据集中先找到模型的回答部分(即assistant部分)再计算损失,因为只有模型回答部分是学习目标。
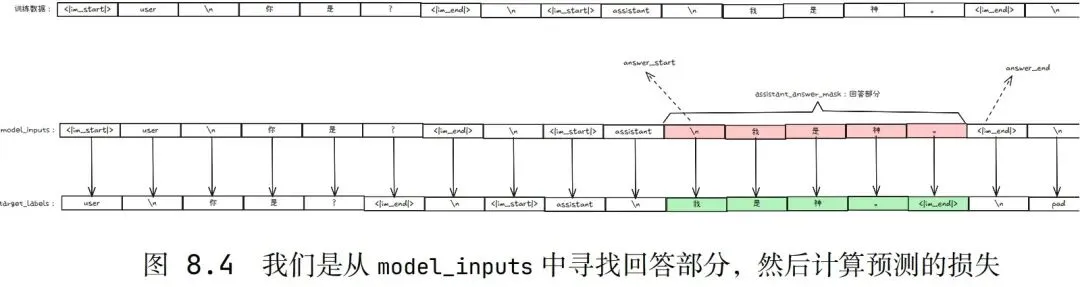
其中SFT和DPO两个阶段对数据集的处理稍有不同。
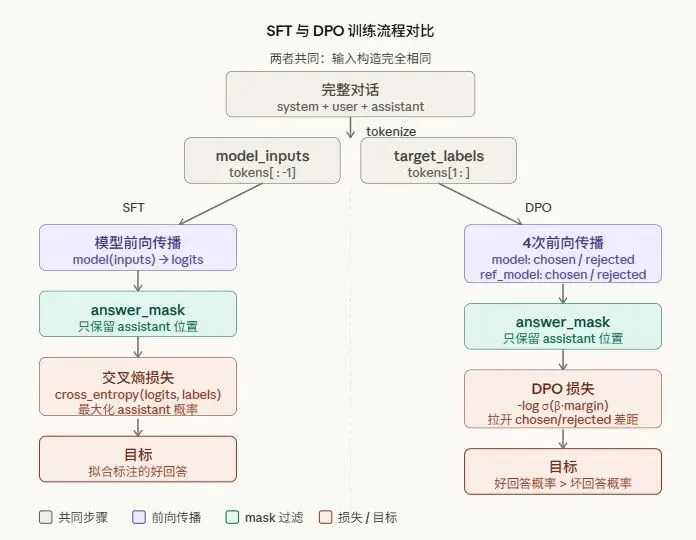
效果
相比原始的Qwen2.5-0.5B-SFT模型,Qwen2.5-0.5B-SFT-DPO模型理论让模型输出偏好文本。
以"问题:What is AI?"为例,SFT模型和DPO模型的区别如下。
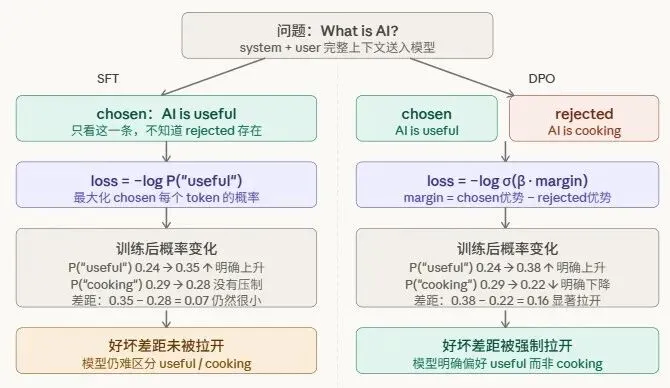
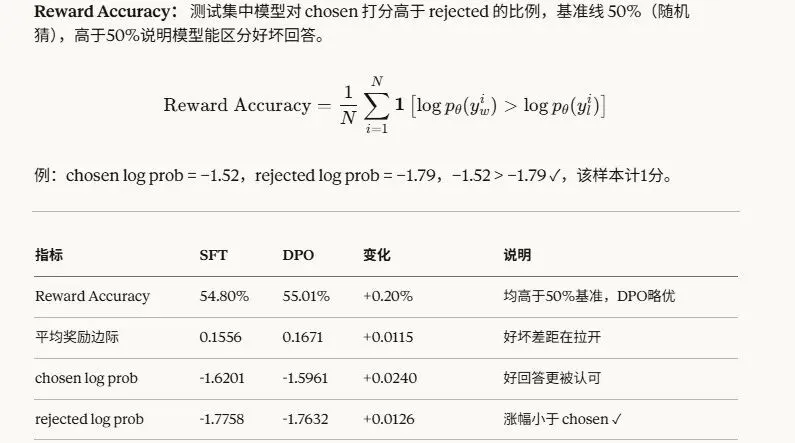
用ultrafeedback_binarized中的1千条测试数据验证,发现DPO模型稍有提升(但提升幅度较小)。