前面已初步学习了PPO算法,此处使用PPO方法获得一个mini版的InstructGPT。
整体流程
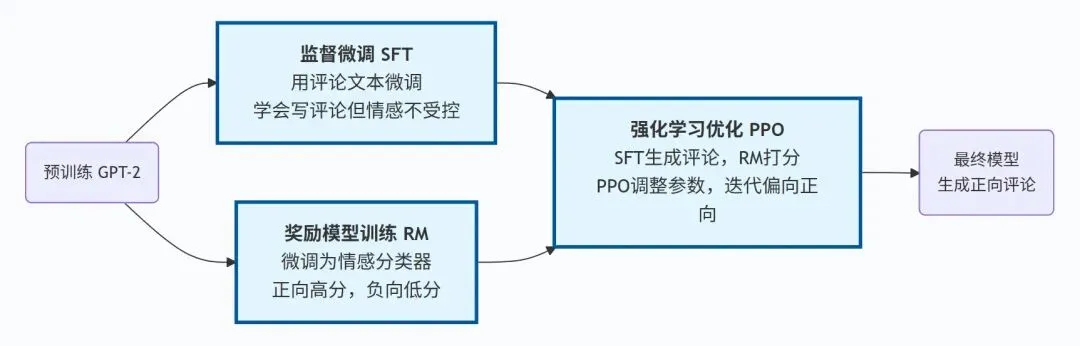
一般预训练模型经过SFT(Supervised Fine-tuning,监督微调)和RLHF(Reinforcement Learning From Human Feedback,基于人类反馈的强化学习)方法处理后,输出更符合人类偏好。
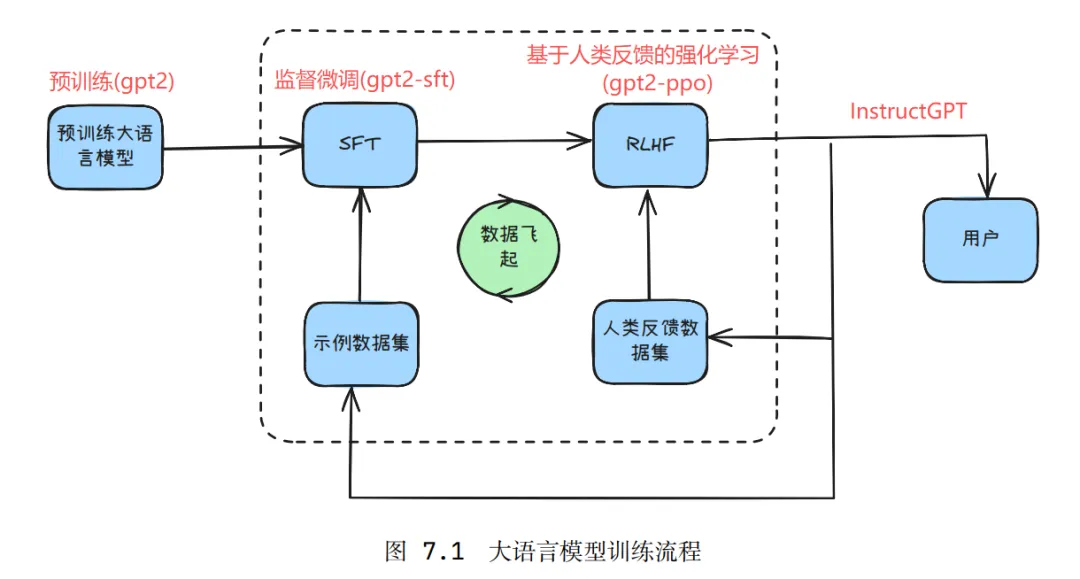
预训练(Pre-train)
从强化学习的角度来看预训练模型(gpt2),其中策略、状态等角色对应如下。

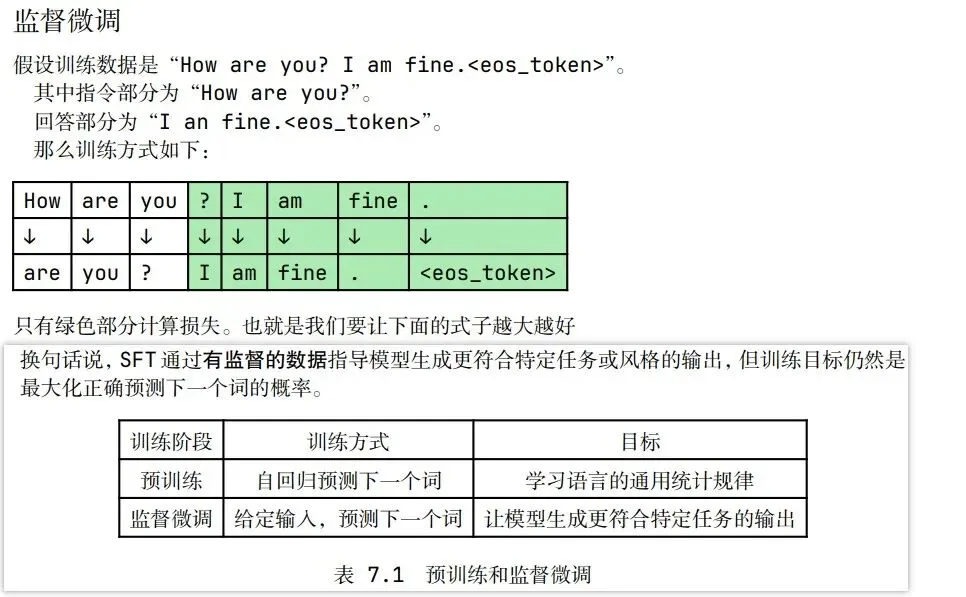
监督微调(SFT)
在选定电影评论数据集中用预训练模型训练一轮,使得模型的输出内容更贴近数据集,保存模型为gpt2-sft.
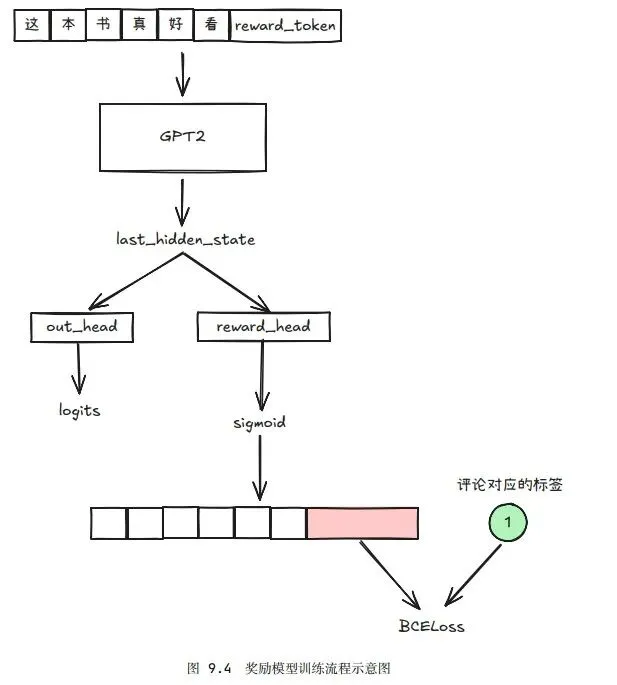
奖励模型(RM)
电影评论数据集中有评论和标签,这样就可以基于预训练gpt2训练一个奖励模型(也是分类模型)。
保存模型为Reward_Model,可以给输入的评论输出一个评分(即奖励)。

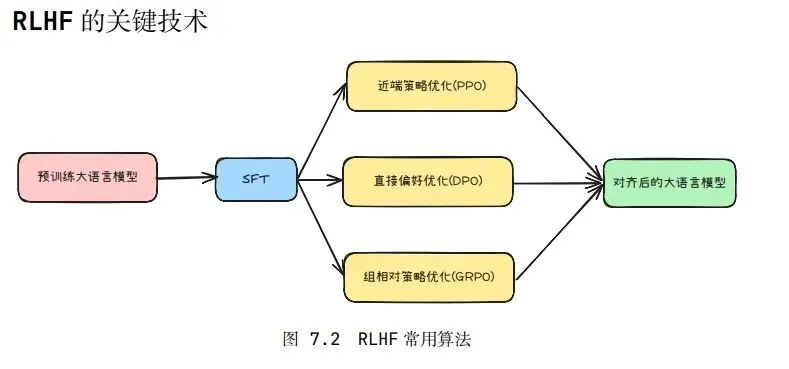
RLHF
此处从RLHF方法集中选择之前学习过的PPO算法。
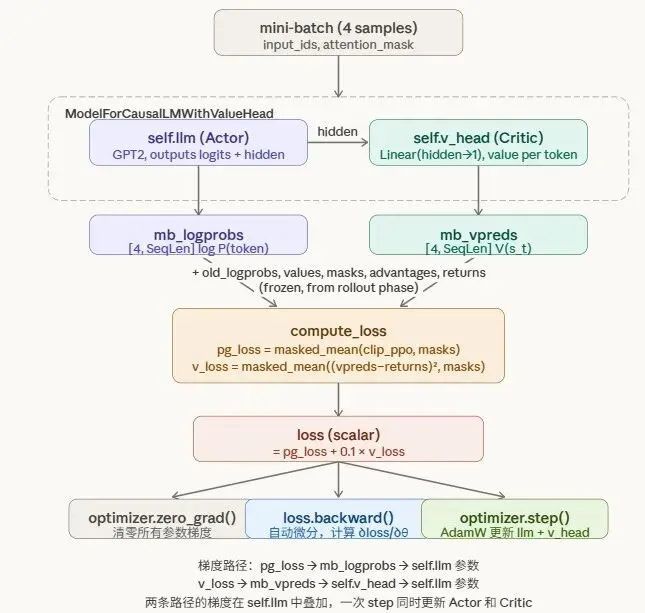
本次的PPO算法案例中,将actor模型和critic模型放到了一个模型中,两者共享 gpt2-sft 模型的权重。
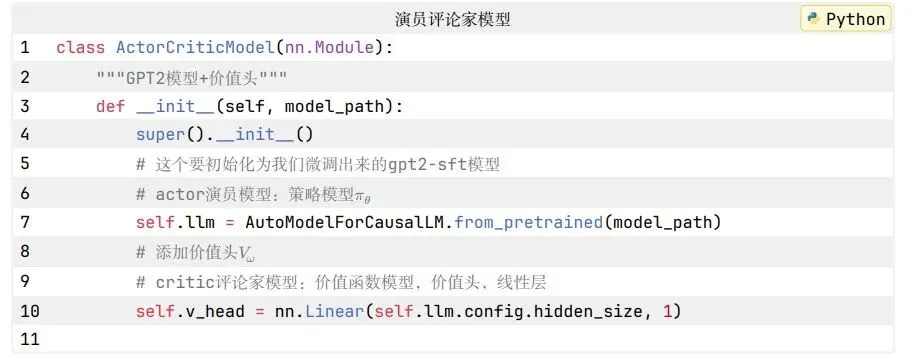
整理一下,可得本次案例学习的整体流程如下。
实现细节
奖励和价值
- • 奖励:一般由环境给出奖励,此处是训练的奖励模型Reward_Model
- • 价值:训练出来的价值函数模型(critic层)对大模型的输出评估价值即状态值。
计算奖励和价值时均只考虑输出token部分,不考虑输入部分。
奖励
在 InstructGPT的PPO 阶段,设计奖励函数为奖励模型和惩罚项的组合。
假设输入是"这本书",输出为"这本书真好看",则每个token的奖励如下所示。
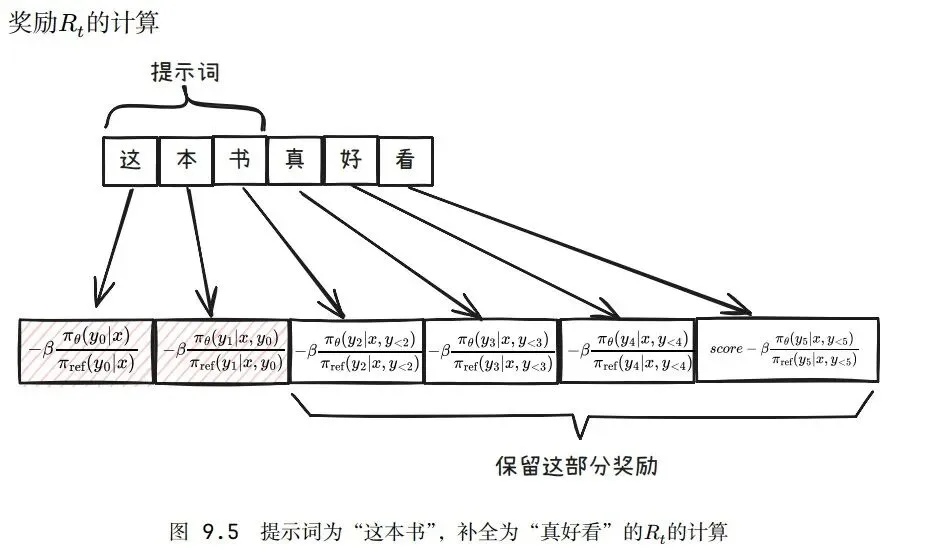
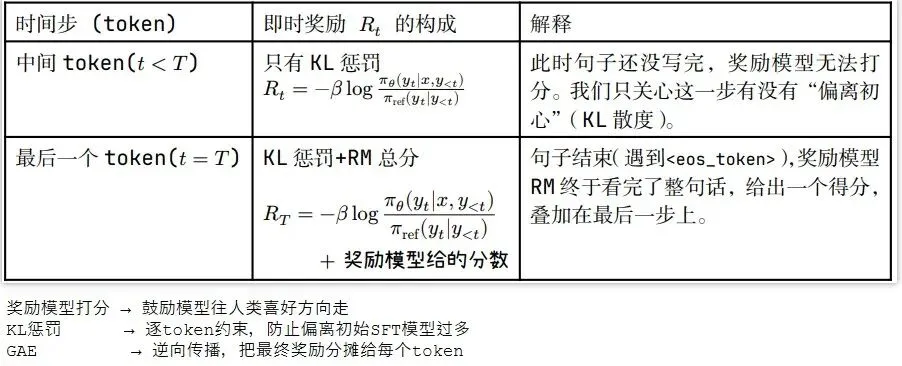
价值
critic层(gpt-sft层中的ValueHead)对输出的token给出评分(状态值)。
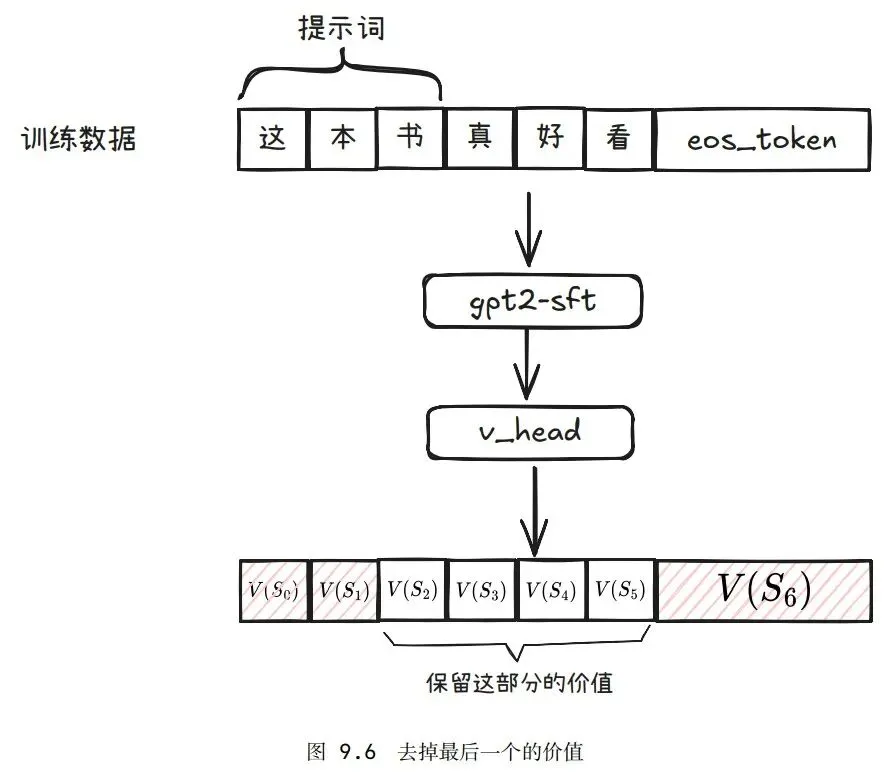
训练批次
加载数据集时,起始设置32条样本为一批。考虑实际资源,设置每4条样本作为微批更新一次参数。
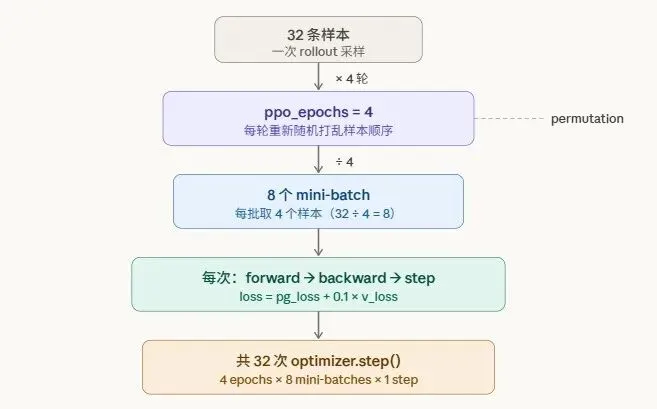
损失
加权求和actor、critic的loss,回传到gpt-sft中更新参数。
KL 散度 和 GAE中比率
计算时KL散度和GAE中的新旧策略比率ratio公式有些类似,但是基准不同。

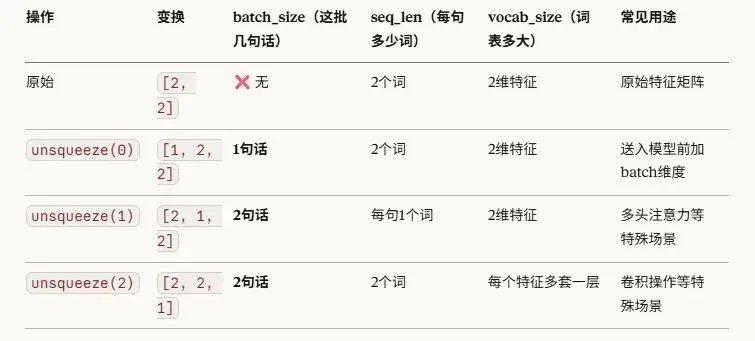
unsqueeze用法
计算时有时需要通过unsqueeze/squeeze变换矩阵维度。
以一个2*2的张量为例,参照常见三维张量batch_sizeseq_len*vocan_size要求,unsqueeze处理后含义如下。
标准PPO和RLHF-PPO对比
相比较之前学习的PPO算法,RLHF-PPO有一些差别。

效果
相比原始的gpt-sft模型,经过ppo处理后的gpt-ppo模型在验证集上分数明显提升,即输出的评论更偏正向。


