2.2 Transformer
由 Google Brain 团队的Vaswani等人提出的的开创性工作Attention Is All You Need引入了一种能够分析大规模数据集的 Transformer 模型。Transformer最初是为自然语言处理(NLP)而开发的,但随后被改编应用于机器学习的其他领域,如计算机视觉等。该模型旨在解决 RNN 和 CNN 的一些缺陷,例如长程依赖、梯度消失、梯度爆炸、需要更多训练步才能达到局部/全局最小值,以及无法进行并行计算等问题。因此,该模型提出的解决方案为处理神经网络任务(如翻译、内容生成和情感分析)提供了一种新的方法。
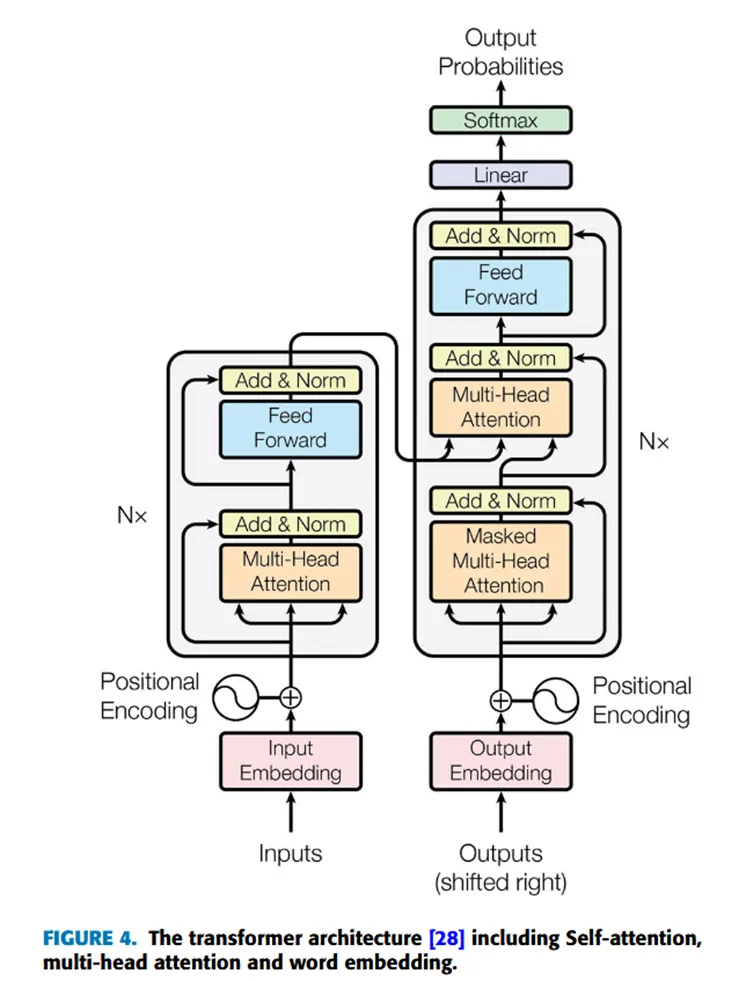
Transformer 架构:Vaswani 等人在他们的研究中提出了三个主要概念,如FIGURE 4 所示,包括自注意力机制(self-attention),该机制允许模型根据输入序列的重要性进行评估,从而减少长程依赖;多头注意力机制(multi-head attention),使模型能够以多种方式学习输入序列;以及词嵌入(word embedding),将输入转换为向量表示。
编码器和解码器(Encoder and Decoder):值得一提的是,Transformer 架构继承了编码器-解码器结构,该结构在编码器和解码器中都使用了堆叠的自注意力和逐点全连接层。编码器由 N = 6 个相同的层堆叠而成,每个层包含两个子层:一个多头自注意力机制和一个全连接前馈网络。解码器与编码器类似,但多了一个额外的子层,用于对多头注意力进行掩码操作。编码器和解码器都对其子层应用残差连接(residual connections),然后对层进行归一化(normalization)。
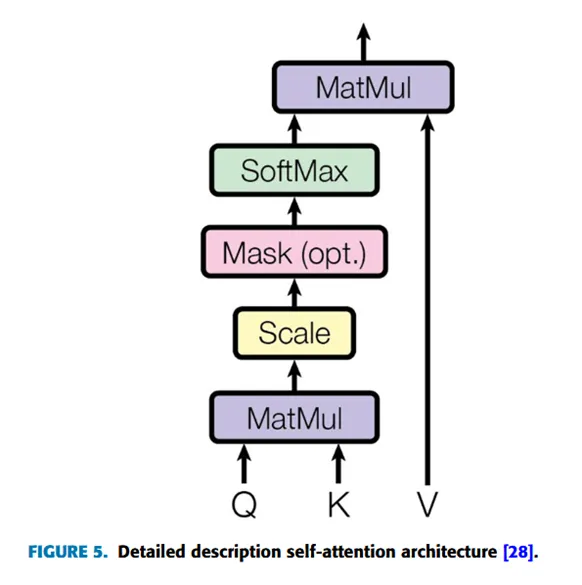
自注意力机制(Self-Attention):注意力机制是一种通过关注句子或任意输入中的关键部分,以更好地理解词语上下文的机制。它的基本思想是将一个查询向量(query)与一组键-值对(key-value pairs)映射到一个输出向量。根据文献“Attention is all you need”,自注意力机制指的是缩放点积注意力(Scaled Dot-Product Attention),它由查询(query)、键(key)维度dk和值(value)维度dv组成,其计算公式如下:
图5展示了注意力结构,其中使用SoftMax激活函数来计算值的权重分布。
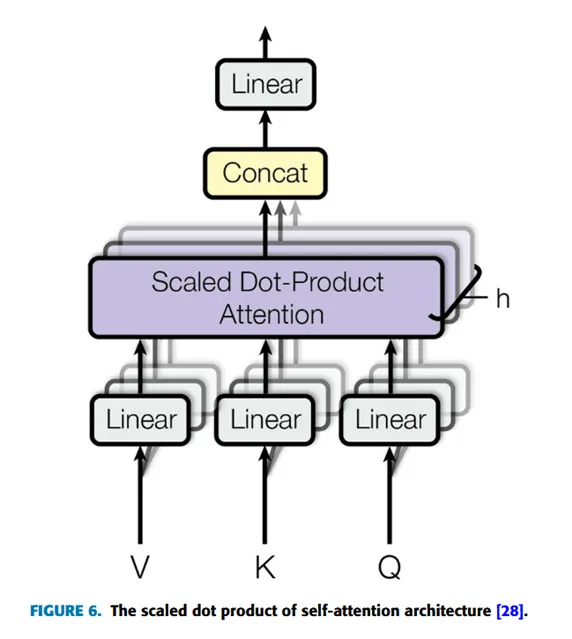
多头注意力机制(Multi-Head Attention):多头注意力机制提出,自注意力可以以并行的方式运行多次,通过不同表示子空间(representation subspaces)中的查询(query)、键(key)和值(value)组合同一注意力池化机制的多种信息。随后,这些独立的注意力输出会被拼接(concatenate),并线性变换为期望的维度,如下方公式和图6所示。
其中每个注意力头的计算方式为
自从 Transformer 被提出以来,已经开发出多个变体,用于解决计算机视觉和自然语言处理中的不同机器学习任务。必须指出的是,当前最先进的模型都是建立在基础的 Transformer 架构之上的。在接下来的小节中,我们将讨论当代的生成式模型。
1) 生成式预训练变换器(Generative Pre-trained Transformer, GPT)
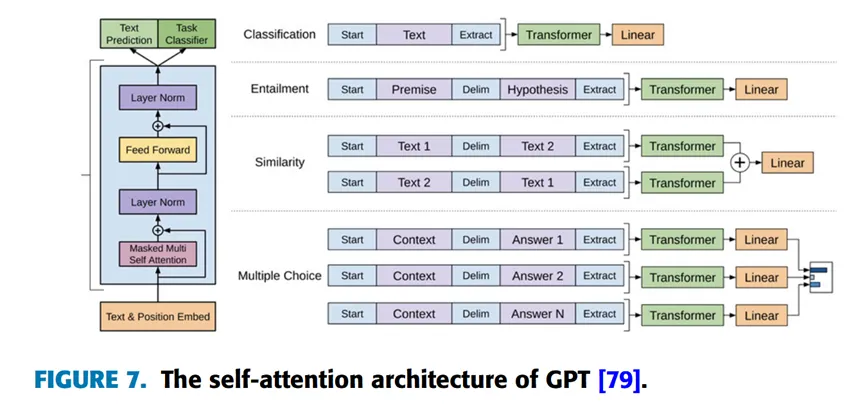
GPT是指一种基于Transformer架构的大语言模型(large language model,LLM),它利用深度学习技术生成类似人类语言的文本。该模型由OpenAI于2018年提出,是在Google于2017年提出的Transformer架构上发展的。GPT 模型由一组堆叠的 Transformer 解码器(decoder)组成。他们提出了一个由两个阶段构成的模型:首先在大规模文本语料库上学习高容量的语言模型;随后,在判别任务中使用带标签数据进行微调,如图 7 所示。
GPT(或称 GPT-1)是在 BooksCorpus 数据集上进行训练的,该数据集包含超过 7,000 本未发表的独特图书,涵盖多个类型,如冒险、奇幻和爱情小说,这些文本具有较长的连续性,使得生成式模型能够学习长距离的信息。模型的训练规范如下:
12 层仅含解码器的 Transformer;
掩码(masked)自注意力机制(768维状态向量,12个注意力头);
按位置的前馈神经网络;
Adam 优化器;
学习率:2.5e-4
3072维的内部状态
该模型的评估任务涵盖自然语言处理(NLP)中的四个主要类别:包括自然语言推理、问答与常识推理、语义相似度判断以及文本分类。在初始版本发布后,OpenAI 相继推出了一系列称为GPT-n系列的模型,每一代模型都在规模和效率上超越前一代。截至文章发表时,GPT-4是最新的版本,于2023年3月发布。(文章发表时GPT-4是最新的,目前已经到GPT-5系列啦)
2)GPT-2
在GPT-1取得巨大成功之后,OpenAI于2019年发布了第二个版本 —— GPT-2。该模型拥有 15 亿个可学习参数,其预训练语料和参数数量是前一代的 10 倍。GPT-2 是在 WebText 数据集上训练的,该数据集由数百万网页组成。因此,该模型能够处理复杂问题,并能在各种主题和风格中生成连贯且符合上下文的文本。
3)GPT-3
GPT-3 于 2020 年发布,支持 2048-token 的上下文长度,拥有 1750 亿个可学习参数,是前一代的 100 多倍,并需要 800GB 的存储空间。该模型基于 CommonCrawl 数据集进行训练,并被应用于自然语言处理的各个领域,展示了出色的 few-shot 和 zero-shot 表现。该版本后来被进一步改进为 GPT-3.5,并用于开发 ChatGPT。大量研究将 GPT-1 至 GPT-3.5 应用于多种任务,包括:语音识别、文本生成、密码学、计算机视觉、问答系统。
4)GPT-4
GPT-4 是 OpenAI 于 2023 年 3 月发布的最新模型。它是一个多模态的Transformer 模型,作为一种大规模语言模型,它可以接收图像和文本输入,并生成文本输出。
GPT-4 在多个专业和学术基准测试中展现出与人类相当的性能,例如通过律师资格考试和医学考试。其训练数据包括公开的互联网数据和第三方授权数据,并通过人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)进行微调。它还通过用于测量大规模多任务语言理解的基准测试 —— Measuring Massive Multitask Language Understanding (MMLU) 进行了对比评估。MMLU 覆盖了 57 个任务,涵盖小学数学、美国历史、计算机科学、法律等多个领域,GPT-4 在所有任务中均优于其他最先进的模型。