——chapter.11 能够理解自然语言的神经网络:国王-男人+女人=?
本章是笔者期待已久的章节,笔者读书时思路常飘忽,故记录之为免遗忘。


如果让笔者来完成,第一想法或许是:
1.预测单词的开始和结束或许是纯粹依赖数据库就能做到的事情,直接喂词库切分似乎可行。
2.接下来的几个任务比较直观的想法是类人类先进行语法学习,这样划分句子开头和结束以及词性都能一次性解决。
不过如果根据前几章学到的东西而言,或许多插几个隐藏层才更像训练时会采取的方法。

也就是说NLP任务的难点反而不完全处在数据集关联部分,更多的是自然语言与数字矩阵间的转化。
说到自然语言转数字笔者的第一反应是A1Z26,如果有二进制要求的话就是五位二进制,如果是中文的话或许中文电码?
不过由此观来问题反而不集中在这了,只是转码的话应当在计算机发明之初便解决了,更多的是含义转换吗?

问题是“长度不固定”和“含义是字符组合而成的,通过单一字符向量进行预测是不理智的”这两个啊。
第一个或许拆分?拆分成固定大小并补位?
第二个就可以用人类层级来分了,如果说是词向量的话那就是将最小单元确定为单词?
是值得一试的主意诶,如果以单词为单元的话同时也完成了拆分工作,包括用单词辨识褒贬也是很符合人类直觉的做法。

诶,连单词本身的表示也彻底脱离字母吗?
这个描述很让人想起之前搞聚类模型时要用的字典诶。
不过这样量级会太大了吧?就算不是根据词汇表中的索引,而是在词袋内的词汇自身索引,如果量级到万甚至更多不会降速以及巨量算力消耗吗?
不过确实,这样表示句子只用加起来就好,超级方便……就像每个评价都有一个表格,如果语段中有这个词汇就打勾的感觉。
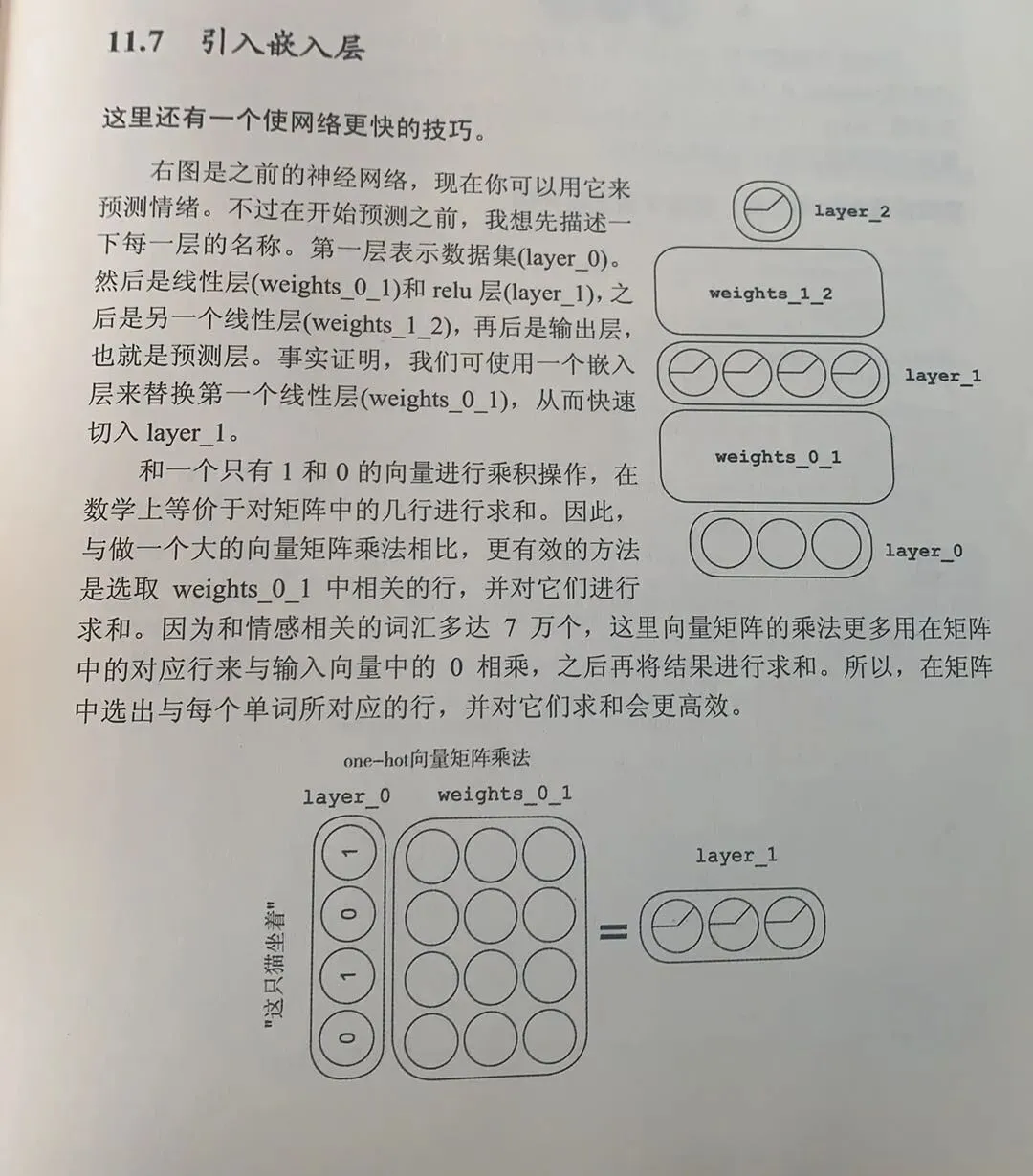
果然,连情感预测的词汇数都到了7万,吓哭了,不过有嵌入层之后看起来算力问题减轻了不少。
题外,笔者之前读到过有人的见解说英文字母比起中文的字,对应的更像是笔画,而中文字对应的才像是单词。那么如果是中文的话,或许字可以纳入最小单位考量范畴?
或者虽然会有部分失真,但是把中文词语翻译成英文再处理是否可以一试?


也就是说隐藏层是分组,或者更确切的说,是标签。
太好了!笔者曾经有尝试用自己的话概括对隐藏层的理解,几乎全对是非常值得高兴的事情!
——“隐藏层像是我们分辨图片里有没有猫的时候用来衡量的标准,如耳朵像不像、鼻子像不像,但是这些标准没有被我们明确建模出来,而是虚设了一些标准,只声明其是存在的,至于具体是什么、贴不贴合那不是我们工作,网络自己来进行调整。”

这个笔者之前曾在尝试理解无监督机器学习时了解过。
笔者曾对无监督机器学习的运行感到无法理解,因为无监督听起来就像机器在随机抽两个东西不知道以什么标准什么方式比较后判断相似度并归类,非常反直觉,这样的分类的意义值得质疑。
之后得知词向量和欧式距离的概念惊为天人,认为其的的确确为非常天才的算法。虽然仍对其与人类生活中的分类对接程度留有质疑,但至少为机器自身的判断而言提供了某些可供参考的准则。

是的,如我所想,机器聚类会随着需要的判断语境发生改变,不过这样的话机器聚类的感觉就更像贴标签了。
词与词之间有相似度,据相似度进行聚类。聚类时我们的需求只到“准确贴标签”,所以只要标签判断准了,标签内部相似度不与自然语言完全重合是完全可以接受的。

这太厉害了!虽然就推演和理论而言确实是可行的,但是真的有如此效果果然还是让人惊叹。
已完成今日份深度大学习。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
