Chunk Pre-fill 学习笔记
笔记整理自视频:https://www.youtube.com/watch?v=qBFENFjKE-M
背景知识
1.1 LLM 的工作原理
大语言模型是自回归(autoregressive)的,这意味着它们的工作过程分为两个阶段:
阶段一:Pre-fill(预填充阶段)
阶段二:Decode(解码阶段)
1.2 为什么需要批处理
GPU 拥有强大的计算能力,但要充分利用 GPU,必须进行批处理。
批处理的好处:
不批处理的问题:
二、技术演进
2.1 第一代:静态批处理(Static Batching)
工作原理
将一批请求的 pre-fill 阶段一次性全部完成,然后一起进入 decode 阶段。
关键问题:
实际场景
问题:用户A和C完成后,GPU 还在为用户B工作,无法处理用户D的请求,造成浪费!
2.2 第二代:连续批处理(Continuous Batching)
这是 VLM 的核心创新之一,基于 PagedAttention 技术。
工作原理
当一个请求完成后,立即放入新请求,充分利用 GPU 时间。
关键改进:
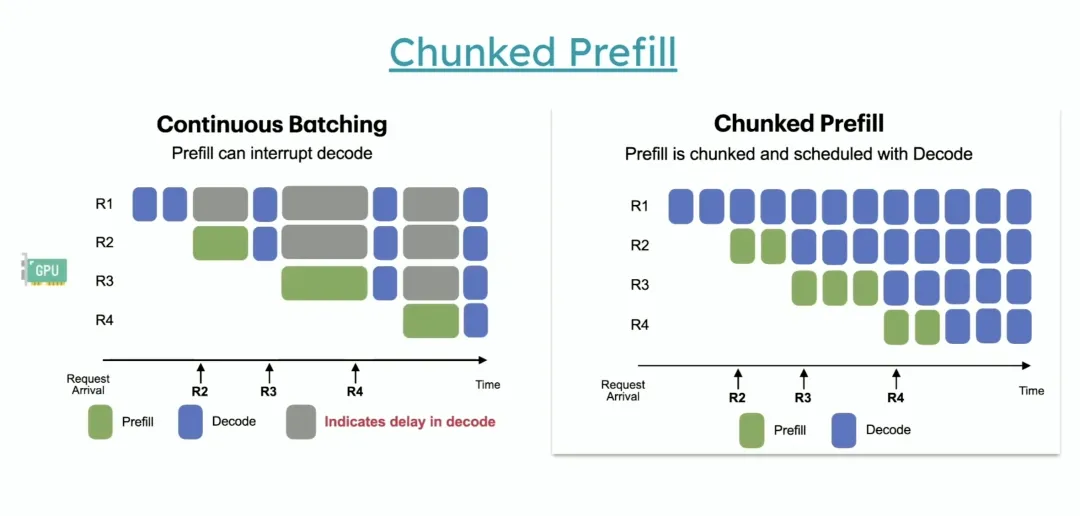
三、Chunk Pre-fill 详解
3.1 连续批处理面临的新问题
虽然连续批处理极大地提高了 GPU 利用率,但在实际应用中,它仍然存在一个用户体验问题。
问题场景
用户体验:
- • 请求1用户:获得3个token → 等待很长时间 → 获得2个token
用户体验:请求1用户:获得3个token → 等待很长时间 → 获得2个token感觉:"为什么会卡顿?"
问题严重性
3.2 Chunk Pre-fill 的工作原理
核心问题:传统LLM推理中的"等待延迟"
在传统的LLM推理系统中,通常会遇到这样一个问题:当有新请求到来时,模型需要先完成预填充(Pre-fill)阶段(处理完整的prompt上下文),然后才能开始解码(Decode)阶段(逐个生成tokens)。这会带来:
- 1. 批次间等待:解码中的请求必须暂停,让新请求先预填充
- 2. GPU利用率低:在处理短预填充时,GPU计算资源未被充分利用
Chunk Pre-fill的创新方法
Chunk Pre-fill通过以下方式解决了这些问题:
1. 混合批次处理
- • 而是将新请求的预填充分块,与正在进行的解码请求混合在同一个批次中
2. 分块预填充原理
传统方式:批次1: [解码请求1, 解码请求2, 解码请求3]批次2: [预填充新请求] ← 所有解码暂停批次3: [解码请求1, 解码请求2, 解码请求3, 解码新请求]Chunk Pre-fill:混合批次: [解码请求1, 解码请求2, 解码请求3, 预填充新请求-分块1, 预填充新请求-分块2]下一批次: [解码请求1, 解码请求2, 解码请求3, 解码新请求, 预填充另一个请求-分块1]
3. 技术优势
- • 消除等待延迟:解码请求无需暂停等待新请求预填充完成
- • 提高GPU利用率:GPU可以同时处理不同计算模式的任务
实际效果对比
传统方式的问题:
- • 系统必须暂停用户A的生成,先处理用户B的预填充
Chunk Pre-fill的优势:
- • 用户B的请求被分成小块,在用户A生成的间隙中处理
3.3 技术要点
1. 智能调度
2. Resource 管理
GPU 资源分配示例:假设 GPU 每步可以处理:- 16 个 decode 操作- or 4 个完整的 pre-fill 操作- or 混合:8 decode + 2 pre-fill chunks时间步 1: ┌─────────────────────────────────────┐ │ Decode: 请求1-10 (10个token) │ │ Pre-fill chunk: 请求11的1/4 │ └─────────────────────────────────────┘时间步 2: ┌─────────────────────────────────────┐ │ Decode: 请求1-8 + 请求11(第1个) │ │ Pre-fill chunk: 请求12的1/4 │ └─────────────────────────────────────┘时间步 3: ┌─────────────────────────────────────┐ │ Decode: 请求1-8 + 请求11-12 │ │ Pre-fill chunk: 请求13的1/4 │ └─────────────────────────────────────┘效果:- 正在解码的用户持续获得 token- 新请求也能快速开始处理- GPU 资源利用率最大化
通俗理解
用最简单的比喻理解 Chunk Pre-fill:━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━比喻:餐厅服务员❌ 没有优化(传统方式):服务员:"好的,我先给A倒水(完成)""然后给B倒水(完成)""给C倒水(完成)""好了,现在给A上菜"顾客A:(等待中...)"我的菜怎么还没来?"━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━✅ 优化后(Chunk Pre-fill 方式):服务员:"给A倒一点水""给A上第一道菜""给B倒一点水""给A上第二道菜""给C倒一点水""给B上菜""给A上第三道菜"...顾客A:连贯地吃菜,体验很好顾客B、C:很快也被服务到━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━关键区别:旧方式:一个任务完整做完,再做下一个新方式:任务交错进行,都不耽误这就是 Chunk Pre-fill 的本质!━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
