基于参考资料1第6&7章和参考资料2第五章,学习用时序差分算法求解最优策略。
基础概念
由参考资料可知,RM算法是一种求解方程的随机迭代算法,数学上可证明其收敛性。

大模型中常见的SGD算法、TD算法及其拓展算法(Sarsa、n-Step Sarsa、Q-learning,MC 算法)均是RM算法的变形。
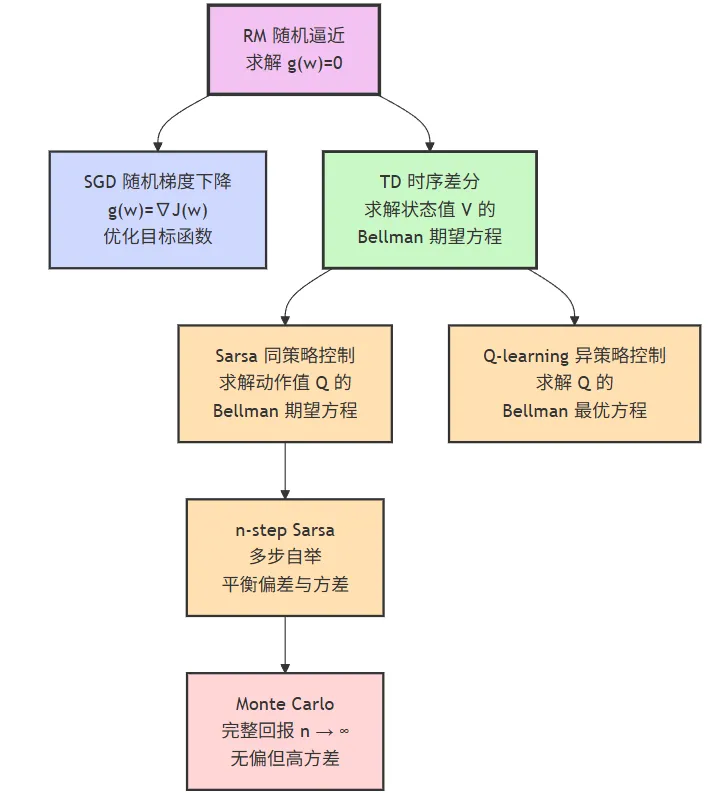
基于参考资料1第7章可知,经典的时序差分算法比如Sarsa,Q-learning,其表达式类似。
由公式可知,会使用t+1或之后时刻的样本或估计来修正t时刻的估计,故也称 时序差分法。

其中Sarsa,Q-learning算法步骤如下。

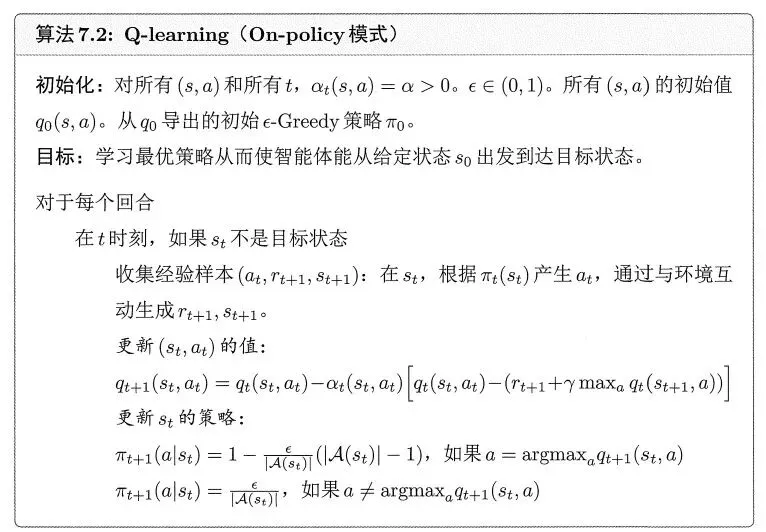
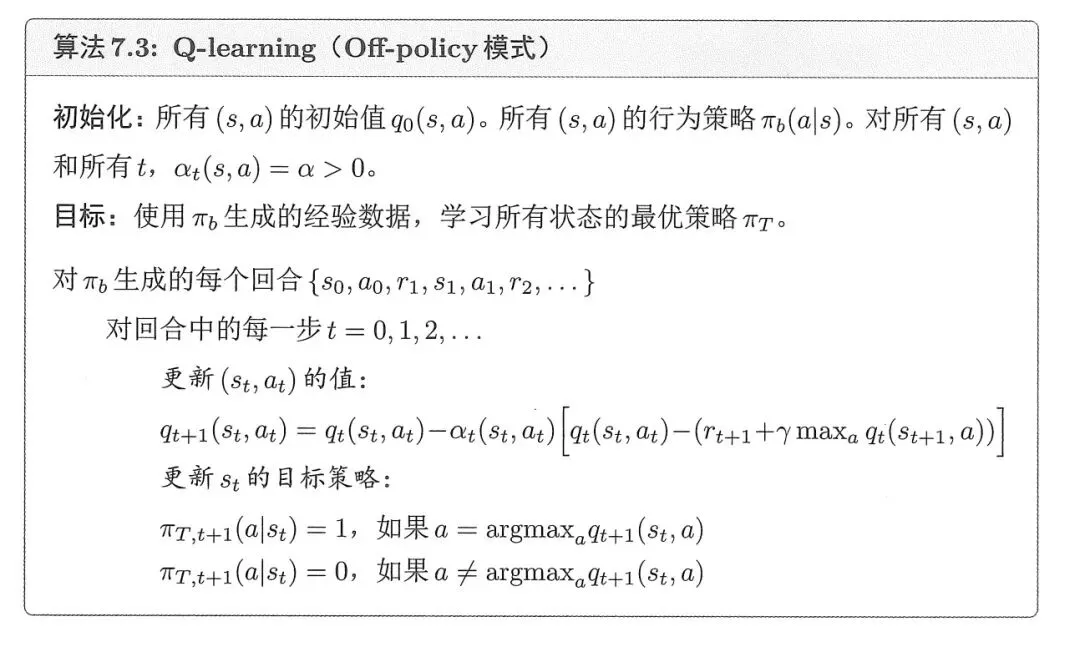
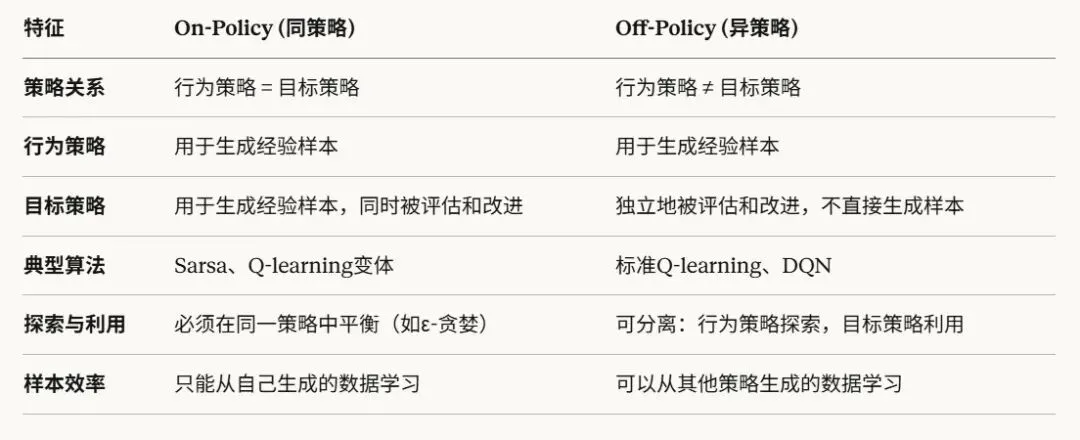
强化学习算法其行为策略、目标策略划分为On/Off-Policy策略。两者区别如下。
案例DemO
参考资料2第5章以悬崖漫步为例,给出了Sarsa,5-Step Sarsa,Q-learning(On-Policy模式)三种算法求解最优策略。
每个算法均运行500个回合(到达终点或者掉进悬崖则回合结束),Q(s,a)在每个回合的多次采样中迭代和修正。
每个位置(即状态s)取Q(s,a)的最大值,最终不同算法获得的策略如下,可看到稍有不同。

参考
- 2. 张伟楠、沈键、俞勇等《动手学强化学习》人民邮电出版社
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
