CUDA 学习笔记:Bank Conflict
- 2026-05-22 21:42:56
CUDA 学习笔记:Bank Conflict这里我们先来回答上一篇笔记《CUDA学习笔记:如何通过共享内存加速矩阵乘法运算》留下的思考问题:“同一个warp中的不同线程访问共享内存As的同一行数据时,多个线程同时读取同一个地址时,会发生硬件层面的访问冲突吗?” 我们先说答案:在硬件层面不会发生访问冲突。 至于为什么,这就是我们这篇笔记要讨论的主题—Bank Conflict(存储体冲突)。 我们知道共享内存(Shared Memory)在物理上是位于SM (Streaming Multiprocessor)内部的片上高速缓存。共享内存被划分为32个等宽的内存模块,这32个内存模块称为Banks(存储体),每4字节(32 bit)的数据按照行优先的排列顺序被映射到连续的Banks中,当同一个warp中的多个线程尝试访问同一个Bank中的不同地址时,就会发生Bank冲突,导致访问必须串行化,从而产生访问延迟。 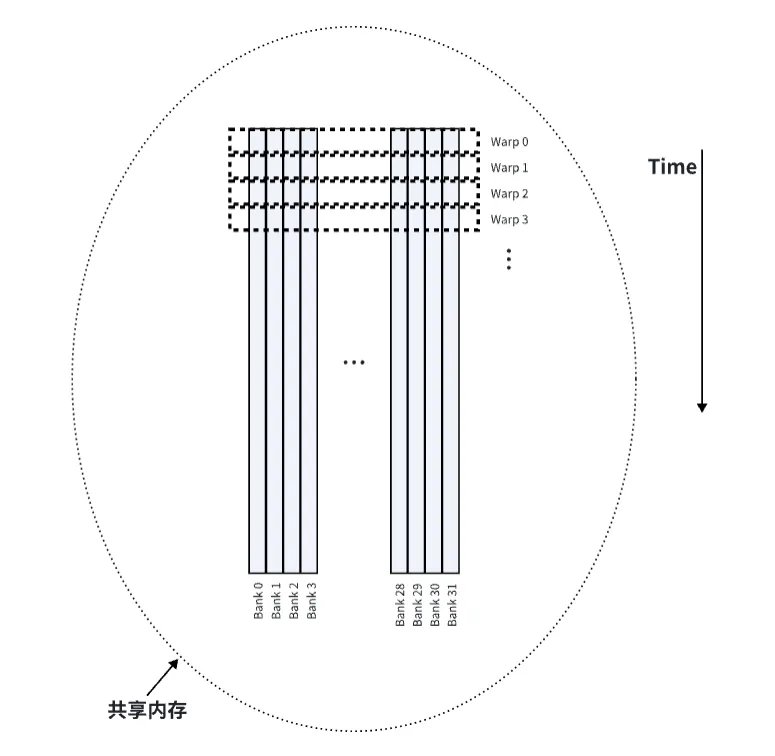
如图,是共享内存中数据存储和Warp调度时数据读取的示意图。这里我们要先明确一点,数据在线性内存中是按照行优先的方式存储的。 我们需要明确的一点是,共享内存上的32个Bank是在物理电路设计上被分成了32个独立的、可并行执行的Bank(存储体),这32个Bank涵盖了GPU SM能提供的最大共享内存(例如128KB)。 如图所示,对于整个SM来说,32个Bank是32个并排的窗口,它是所有运行在这个 SM 上的 Block共享的物理基础设施。 对于一个Block来说,当你的 Block 被分配到这个 SM 上时,它会获得这块物理空间的一部分(逻辑切片),比如上图所示的前4行(Warp0到Warp3)。 而对于一个Warp来说,Warp是使用Bank的最小单位,而Bank冲突之所以是Warp级的,是因为硬件调度器在同一个时钟周期内,只会把一个 Warp(32个线程)的访存请求发送到这 32 个 Banks 上。 我们可以用一个比喻来总结: Shared Memory(共享内存)是一个拥有32 个窗口的银行 (32 Banks)。 Block (线程块)是一大群来办业务的顾客。 Warp (线程束)是这群顾客中被分在同一组(32人)同时走到窗口前的人。 所以冲突的本质就是在这 32 个线程里,有两个线程同时要存、取同一个Bank里的不同数据(不同地址,对应到上图就是同一Bank的不同行),这个窗口就必须先给第一个线程存取,再给第二线程存取,这就因串行等待而产生了延迟,也就是Bank冲突。 Bank冲突有两个例外,即同一个 warp 中的多个线程访问同一个共享内存位置(无论是读取还是写入)。对于读取访问,该字会被广播给请求的线程。对于写入访问,每个共享内存地址只由一个线程写入(具体是哪个线程写入是不确定的)。 下图是一些步进(stride)访问的例子,bank 内的红色框表示共享内存中的一个唯一位置。 下图是32 位 bank 大小模式下的步进共享内存访问的例子: 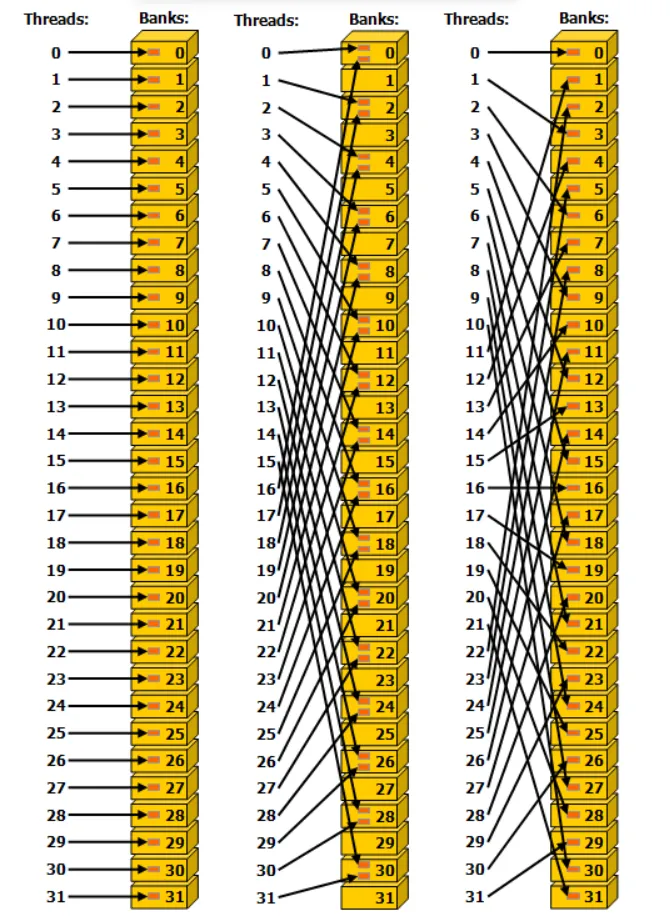
其中,左图表示使用步长为 1 个 32 位的线性寻址(无Bank冲突)。 中间的图表示使用步长为 2 个 32 位的线性寻址(双向Bank冲突)。 右边的图表示使用三字节的线性寻址(无Bank冲突)。 下图是广播机制的内存读取访问的示例。Bank内的红色框表示共享内存中的一个唯一位置。如果多个箭头指向同一位置,则数据会被广播给所有请求该数据的线程。 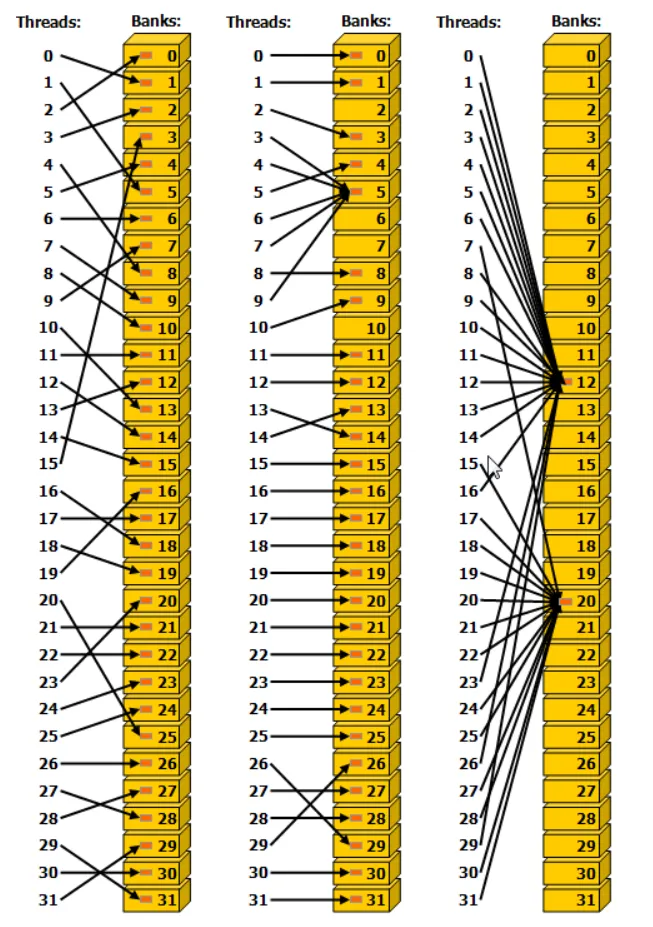
其中,左图,通过随机排列实现无冲突访问。 中图,由于线程 3、4、6、7 和 9 访问了同一组中的相同字,因此无冲突访问。 右图,由于线程访问和同一组中的相同字,因此可以通过广播实现无冲突访问,和中图介绍的情况类似。 上面的代码是上一节介绍的基于共享内存实现的矩阵乘法Kernel的部分代码,在这个Kernel中,一个warp有32个线程,假设threadx.x从0到31,此时threadRow相同(都为0),threadCol从0连续变化到31。 共享内存As和Bs分别通过如下两种方式访问: As[threadRow * BLOCKSIZE + dotIdx]:对于As的访问,会触发"广播"。因为一个warp中的所有32个线程在同一时刻会同时执行As[0*32+dotIdx],对于某个特定的dotIdx,这32个线程访问的是完全相同的内存地址。最终导致的结果就是硬件检测到地址相同,执行广播操作,不会产生Bank冲突。 Bs[dotIdx * BLOCKSIZE + threadCol]:对于Bs的访问,则是一种比较理想的访问模式。因为一个warp中的32个线程执行Bs[dotIdx*32+threadCol]。结果每个线程正好落在不同的Bank上,且地址是连续的,没有Bank冲突。 理解Bank冲突是从CUDA初学者迈向高性能计算高手的成人礼。 本质上,Bank冲突是硬件设计的物理必然与软件索引逻辑之间的一次碰撞。共享内存通过将物理存储划分为32个独立的Bank,为我们提供了极高的并行访问带宽。但正如银行中多个服务窗口一样,如果有多个人挤在同一个窗口来办理不同的业务,就只能在这个窗口进行排队了,原本同一个warp中SIMT产生的并行也只能变成串行了。 在共享内存优化的矩阵乘法Kernel中,我们通过巧妙的索引映射(让threadCol对应连续的地址),让32个线程恰好映射到32个不同的Bank上,完美避开了冲突。 在同一个warp内,我们需要注意: 只有真正理解这32个Bank的运作规律,才可以在CUDA Kernel中随心所欲地驾驭Shared Memory,将GPU的性能压榨到极致。 《2.2.4.2. Shared Memory Access Patterns》of
写在前面
什么是Bank冲突
Bank冲突的两种例外情况
共享内存Kernel中为什么没有Bank冲突
...const uint threadCol = threadIdx.x % BLOCKSIZE;const uint threadRow = threadIdx.x / BLOCKSIZE;...for (int dotIdx = 0; dotIdx < BLOCKSIZE; ++dotIdx) {tmp += As[threadRow * BLOCKSIZE + dotIdx] *Bs[dotIdx * BLOCKSIZE + threadCol];}...
结论
横向访问(连续线程访问连续地址)利用Bank的并行性,快如闪电。 纵向访问(跨步访问导致Bank重叠),触发Bank串行排队,产生Bank冲突,性能受损。 单一地址访问,触发硬件广播,同样很高效。
参考
https://docs.nvidia.com/cuda/cuda-programming-guide/02-basics/writing-cuda-kernels.html#
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 「0337-麻醉学」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+历年真题试卷及答案+题库及答案+复习重点
- 「0438-临床药学」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+历年真题试卷及答案+题库及答案
- 收藏 | 色谱分析法HPLC和GC学习笔记
- 建筑环境学(风水学)简易学习笔记(8)
- 【雷诺曼学习笔记】No.5 树牌:生命、健康与家族传承的根基
- 学习笔记:亚马逊的智能仓储与配送网络
- 【26版步步高高中英语人教版必修一学习笔记WelcomeUnit晨背二ReadingforWriting&OtherParts
- 「0238-公共行政学」电子版+学习笔记+知识点总结+期末考试重点+复习资料+习题集及答案+名词解释+知识总结+高清PDF可打印+免费分享!
- 你有过害怕恐惧吗(学习笔记)
- SOLAS学习笔记:SOLAS II-1第15条 客船舱壁甲板和货船干舷甲板以下外板上的开口
