学习笔记:《人工智能:结构与策略(第 6 版)》深度解析
1. 一段话总结
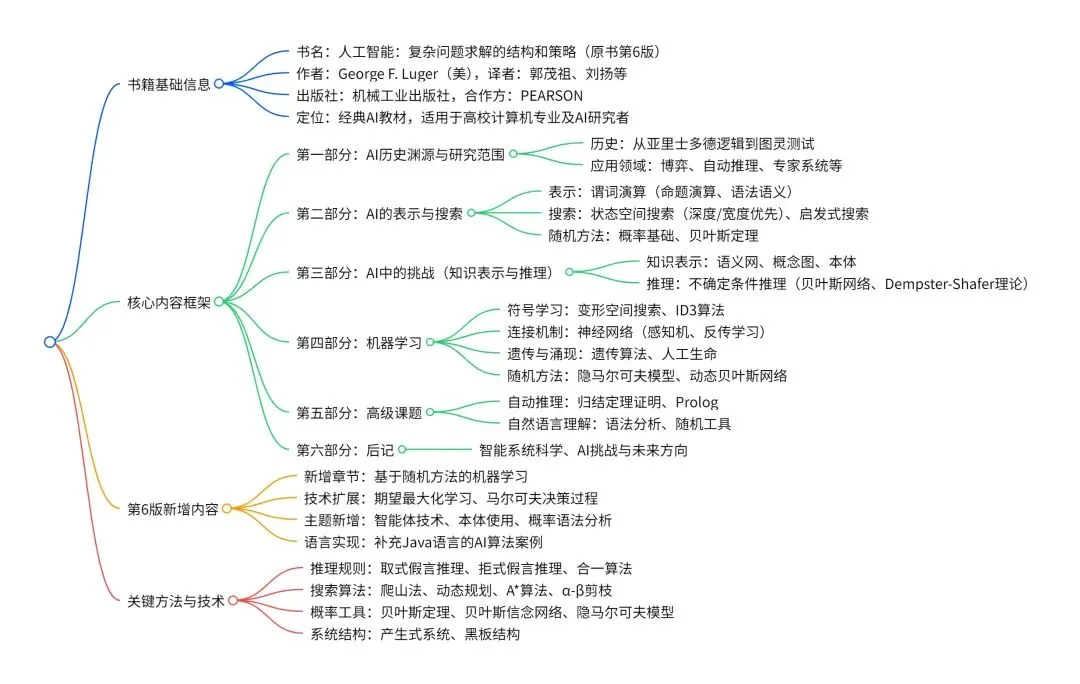
《人工智能:复杂问题求解的结构和策略(原书第6版)》是George F. Luger所著的经典AI教材,全面阐述人工智能基础理论,结合问题求解的数据结构与算法,将AI应用程序落地到实际环境,并从社会哲学、心理学、神经生理学多维度探讨AI;第6版新增基于随机方法的机器学习章节(含一阶贝叶斯网络、隐马尔可夫模型等),介绍智能体技术、本体使用及自然语言处理的动态规划技术,同时提供Prolog、LISP、Java实现的算法案例,适用于高校计算机专业教材及AI领域研究者参考。
2. 思维导图(mindmap)
3. 详细总结
一、书籍基础信息
类别 | 关键信息 |
书名 | 人工智能:复杂问题求解的结构和策略(原书第6版) |
作者 | 乔治·F·卢格(George F. Luger,新墨西哥大学教授) |
译者 | 郭茂祖、刘扬、玄萍、王春宇等 |
出版社 | 机械工业出版社,与PEARSON Education合作出版 |
ISBN | 中文版:978-7-111-28345-4;影印版:978-7-111-25656-4 |
适用人群 | 高等院校计算机专业本科生/研究生(AI课程教材)、AI领域研究者及工程技术人员 |
二、核心内容架构(共6部分16章)
1. 第一部分:人工智能的历史渊源及研究范围(第1章)
- 历史脉络:从亚里士多德的形式逻辑、培根的归纳法,到图灵1950年提出“图灵测试”,再到达特茅斯会议(1956年,AI正式诞生)。
博弈:如九宫游戏、国际象棋,用于研究启发式搜索。
自动推理:基于谓词演算的定理证明(如逻辑理论家程序)。
专家系统:DENDRAL(化学分子结构分析)、MYCIN(医疗诊断)。
自然语言理解:处理语义模糊性,如SHRDLU(积木世界对话系统)。
人类表现建模:模拟人类问题求解过程(如Newell和Simon的通用问题求解器)。
规划与机器人学:分层问题分解,如STRIPS规划系统。
AI语言与环境:LISP、Prolog、Java(第6版新增)。
机器学习:符号学习、神经网络、遗传算法。
神经网络与遗传算法:连接主义与进化计算模型。
AI与哲学:探讨智能本质、心身问题。
2. 第二部分:作为表示和搜索的人工智能(第2-6章)
基础:命题演算(真值表、逻辑恒等式)、谓词演算的语法(常量、变量、函数、谓词)与语义。
核心推理规则:取式假言推理、拒式假言推理、全称例化。
合一算法:求解变量替换使两个谓词表达式匹配,是推理的关键(如unify函数)。
应用:基于逻辑的财务顾问系统(判断投资策略)。
数据驱动vs目标驱动:前者从事实到目标,后者从目标反推事实。
深度优先搜索(DFS):用栈实现,可能陷人深度陷阱,需深度界限。
宽度优先搜索(BFS):用队列实现,保证最短路径,空间复杂度高。
迭代加深DFS:结合DFS与BFS优势,空间线性,时间接近BFS。
图论基础:有向图、树、有限状态自动机。
搜索策略:
应用:8格拼图游戏、巡回推销员问题(TSP)。
计数基础:加法/乘法规则、排列(P(n,r)=n!/(n-r)!)、组合(C(n,r)=n!/(r!(n-r)!))。
概率基础:样本空间、独立事件、条件概率(p(A|B)=p(A∩B)/p(B))。
贝叶斯定理:p(h_i|E)=[p(E|h_i)p(h_i)]/Σp(E|h_k)p(h_k),用于诊断推理(如疾病-症状关联)。
应用:概率有限状态自动机(如“tomato”发音识别)、交通故障诊断。
递归搜索:用递归激活记录替代显式open列表,简化DFS实现。
产生式系统:由规则库、数据库、控制策略组成,如专家系统的核心架构。
黑板结构:多知识源协同求解,适用于复杂问题(如语音识别)。
3. 第三部分:捕获智能:AI中的挑战(第7-9章)
第7章:知识表示:语义网、框架、脚本、概念图、本体(如Brooks的包容结构)。第8章:求解问题的强方法:专家系统(基于规则/模型/案例)、规划(teleo-reactive规划)。第9章:不确定条件下的推理:贝叶斯信念网络(BBN)、Dempster-Shafer证据理论、模糊集推理。4. 第四部分:机器学习(第10-13章)
学习类型 | 核心算法/模型 | 应用场景 |
基于符号的学习 | 变形空间搜索、ID3决策树(信息增益选择测试属性)、基于解释的学习(EBL) | 概念学习、分类任务 |
连接机制学习 | 感知机、反传学习(BP算法)、Kohonen网络、支持向量机(SVM) | 模式识别、函数逼近 |
遗传与涌现学习 | 遗传算法(选择、交叉、变异)、分类器系统、人工生命(如“生命游戏”) | 优化问题、自适应系统 |
随机学习 | 隐马尔可夫模型(HMM)、动态贝叶斯网络(DBN)、马尔可夫决策过程(MDP) | 语音识别、序列预测、强化学习 |
5. 第五部分:人工智能问题求解的高级课题(第14-15章)
第14章:自动推理:归结定理证明(子句形式、二元归结)、Prolog解释器(基于Horn子句)。第15章:自然语言理解:Earley解析器(动态规划)、概率上下文无关文法、信息抽取。6. 第六部分:后记(第16章)
探讨智能系统科学的可能性、AI当前挑战(如常识推理)及未来方向。三、第6版新增核心内容
- 新增章节:第13章“基于随机方法的机器学习”,涵盖一阶贝叶斯网络、隐马尔可夫模型(HMM)、马尔可夫随机场推理。
- 主题新增:智能体技术、本体的使用、自然语言处理的Viterbi概率语法分析。
- 语言支持:新增Java实现的AI算法(原支持Prolog、LISP)。
四、关键理论与方法总结
理论/方法 | 核心作用 | 关键特性/约束 |
谓词演算 | AI的基础表示语言,支持逻辑推理 | 需消除存在量化变量(斯柯伦化) |
A*算法 | 启发式搜索的最优算法 | 要求h(n)可采纳(h(n)≤h*(n)) |
贝叶斯定理 | 不确定推理的核心,融合先验知识与新证据 | 需假设证据条件独立(简单贝叶斯) |
极小极大+α-β剪枝 | 双人博弈的核心策略,减少搜索空间 | 依赖评估函数的准确性 |
产生式系统 | 专家系统的通用架构,分离知识与控制 | 规则匹配效率影响性能 |
4. 关键问题
问题1:A*算法为何能保证找到最优解?其核心约束条件是什么?答案:A*算法能保证最优解的本质是其评估函数f(n)=g(n)+h(n)满足“可采纳性”约束。核心逻辑:g(n)是从起始节点到n的实际路径代价,h(n)是n到目标节点的启发式估计代价。当h(n)是可采纳的(即对所有节点n,h(n)≤h*(n),h*为n到目标的实际最小代价)时,A*算法能确保:一旦找到目标节点,其路径代价必为最小(因为任何非最优路径的f值会大于最优路径的f值,不会先被选中);
算法不会遗漏最优路径(open列表中始终存在最优路径上的节点)。
补充约束:若h(n)满足单调性(对任意节点n及其后继n',h(n)-h(n')≤cost(n,n'),且目标节点h=0),则A*算法第一次访问节点时即找到最优路径,无需后续更新。问题2:贝叶斯定理在AI诊断推理中如何应用?为何实际场景中常使用“简单贝叶斯”?
,参数数量降至n*m(m为假设数),大幅降低计算成本,且在医疗、文本分类等场景中实践效果良好。
问题3:第6版新增的“基于随机方法的机器学习”章节,核心模型(如HMM、DBN)适用于哪些AI场景?其相比传统符号学习有何优势?隐马尔可夫模型(HMM):适用于序列数据处理,如语音识别(将语音信号映射为音素序列)、自然语言词性标注(给单词序列分配词性标签)、生物序列分析(DNA序列预测)。
动态贝叶斯网络(DBN):HMM的扩展,支持复杂时序依赖,适用于机器人定位(随时间跟踪机器人位置)、视频行为识别(分析连续帧中的动作序列)、金融时间序列预测(如股价波动)。
马尔可夫决策过程(MDP):适用于强化学习场景,如游戏AI(如Atari游戏策略优化)、机器人路径规划(在动态环境中选择最优动作)。
- 相比传统符号学习(如ID3决策树、变形空间搜索)的优势:
处理不确定性:符号学习依赖确定性规则,难以应对噪声数据(如模糊的语音信号、不完整的文本),而随机模型通过概率量化不确定性,鲁棒性更强;
适应时序数据:符号学习多处理静态数据(如固定的样本集),随机模型(HMM、DBN)天然支持时序依赖,能建模动态过程;
泛化能力:在数据稀疏场景(如罕见的语音片段),符号学习易过拟合,而随机模型通过先验概率和贝叶斯推断,泛化能力更优。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
