paper: https://arxiv.org/abs/2305.18290
为什么要有DPO
在大模型应用中,一般在sft训练完之后,会再进行强化训练,让大模型的数据更加如何人的偏好。其中,RLH F是最耳熟能详的强化学习方法。但RLHF主要存在以下两个问题:
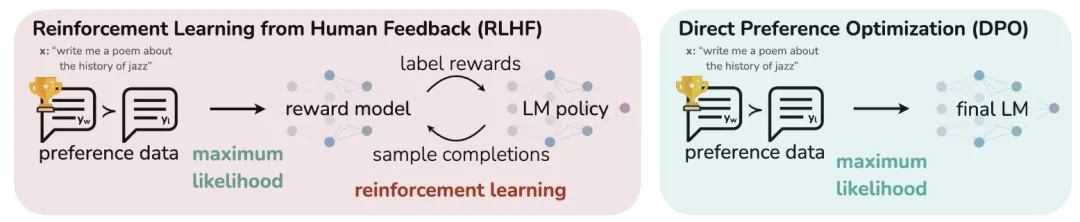
而DPO方法则只需要π_θ和π_ref,并且训练过程也更加稳定。以下是RLHF和DPO方法的流程对比:
下面从几个不同维度对RLHF和DPO进行对比:
| | |
| 需要大量无标注数据,用已有模型生成多个回复然后用奖励模型对数据进行打分 | 无需奖励模型打分,只需要给出偏好对(即只需要告诉模型两个回复哪个更好,不需要具体打分) |
| | |
| | |
| | |
相对来说,RLHF的天花板更高,但是由于起训练难度和成本较高,在很多有明确偏好信息的场景下(比如对话中,回复好与坏),还是使用DPO会更方便一些。
DPO如何对模型进行优化
DPO优化方法,核心就是其Loss函数:
接下来看一下这个Loss函数如何推导得到。
首先,我们看一下RLHF中的优化目标如下:
其中:
在DPO中,引入了一个Bradley-Terry偏好模型,用于刻画偏好数据(y_w, y_l)中,y_w比y_l更好的概率,如下:
其中:
- y_l: l,即loss,偏好数据中标注更好的数据
这个公式上下都除以exp(r*(x, y_w)),那么就可以转换成如下:
σ为sigmoid函数。
那么,如果我们想要训练一个奖励函数的话,那么我们希望这个奖励函数要保证上面这个公式的结果越大越好,因此,经过最大似然估计,我们可以得到最大似然损失函数:
然后,DPO中将最开始的RLHF的优化目标,改写重写为针对每个输入x寻找最优分布π(y|x)这个Z(x)是归一化配分函数,主要是为了保证π*是一个有效的概率分布。从奖励函数r(x,y)到最优策略π*的映射。那么,反过来,我可以将奖励函数r(x,y)用最优策略π*和参数策略π_ref来表达:隐式奖励。而第二项的βlogZ(x)一个仅与输入x有关,与输出y无关的项。因此,当我们要偏好对的计算奖励差的时候,βlogZ(x)就可以被消掉:从这个推导得到的Loss函数中,我们可以看到,这里面是只涉及π_θ和π_ref,而不涉及奖励函数的。至此,DPO就实现了通过数学公式来完成Loss函数的重构,将奖励函数从优化过程中去掉,简化了RLHF的优化过程。DPO的缺点
- 从Loss函数上可以看到,DPO只是关注y_w和y_l在差值,但是没有对y_w本身进行打分,那么有可能y_w本身也不怎么痒,只不过y_l更差,属于矮子里面拔将军。
- DPO训练,需要y_w和y_l构成pair数据。但是pair数据其实不太好收集,互联网中更多的是通过点赞👍或点踩👎得到的point数据
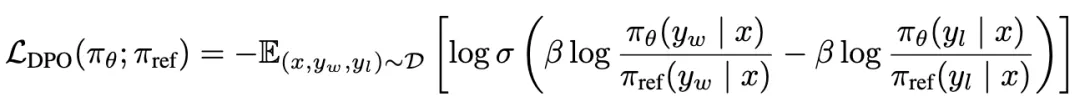
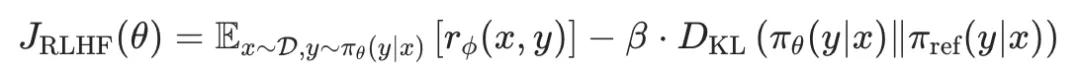
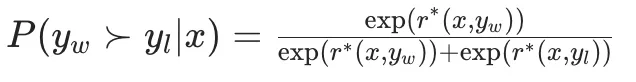
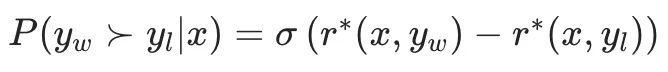
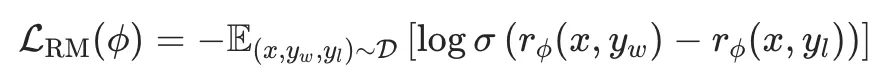
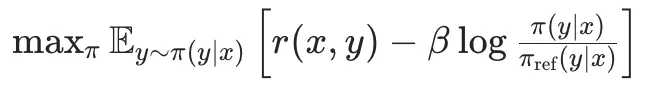
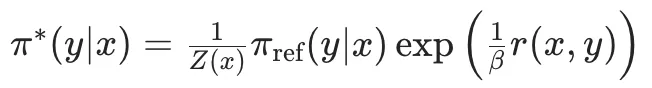
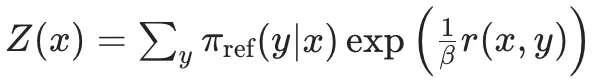
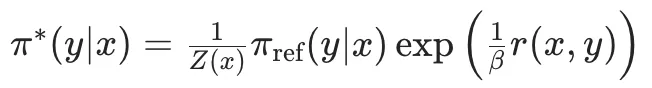
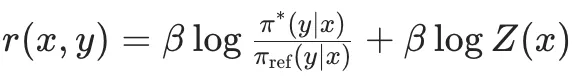
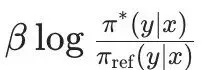
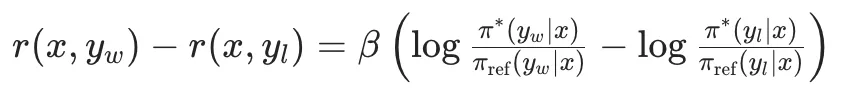
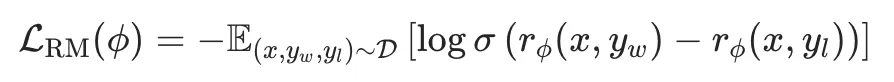
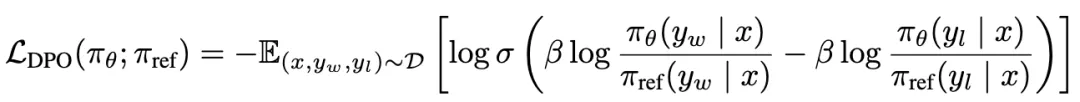
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
