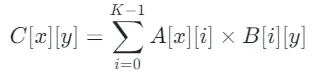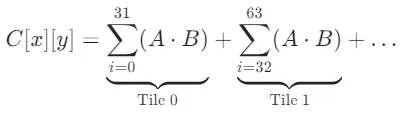1. 写在前面
咱们书接上文,在上一篇文章《CUDA学习笔记:紧凑的全局内存访问》中,我们一起深入研究了全局内存访问合并如何加速矩阵乘法运算的。
CUDA学习笔记:紧凑的全局内存访问
在上一篇文章中我们也提到了,实际上矩阵运算的瓶颈不在运算速度,而是在访存速度,而优化访存的核心原则就是:1)提高访存利用率,全局内存访问合并就是这个思路;2)使用高速内存,这篇文章中我们要介绍的利用共享内存来加速矩阵乘法运算就是这种思路的代表。
在看怎么使用共享内存加速矩阵运算之前,我们先来深入了解下什么是共享内存(shared memory)。
2. 什么是共享内存
在前面的文章中,我们也提到过,共享内存位于片上SM(Strem Multiprocessor, 流式多处理器)上,每个SM都有一块共享内存,逻辑上划分给各个线程块,同一线程块中的线程可以访问同一块共享内存,因此线程块上的线程可以(严格来说应该是同一个warp)通过共享内存实现通信。
需要注意的是共享内存仅在Kernel的生命周期有效,共享内存比全局内存具有更快的读取速度,但内存空间相比全局内存就要小很多了(KB级别)。
以NVIDIA 2017 年发布Volta 架构为例,全局内存带宽为 750GiB/s,共享内存带宽为 12,080GiB/s,两者在带宽上有10倍以上的差距。
共享内存有两种常见用法:
共享内存用于暂存全局内存中的数据,以确保从全局内存的读取和写入都能正确合并。
共享内存用于允许同一个线程块内的线程之间共享数据。
3. 如何利用共享内存加速矩阵乘法运算
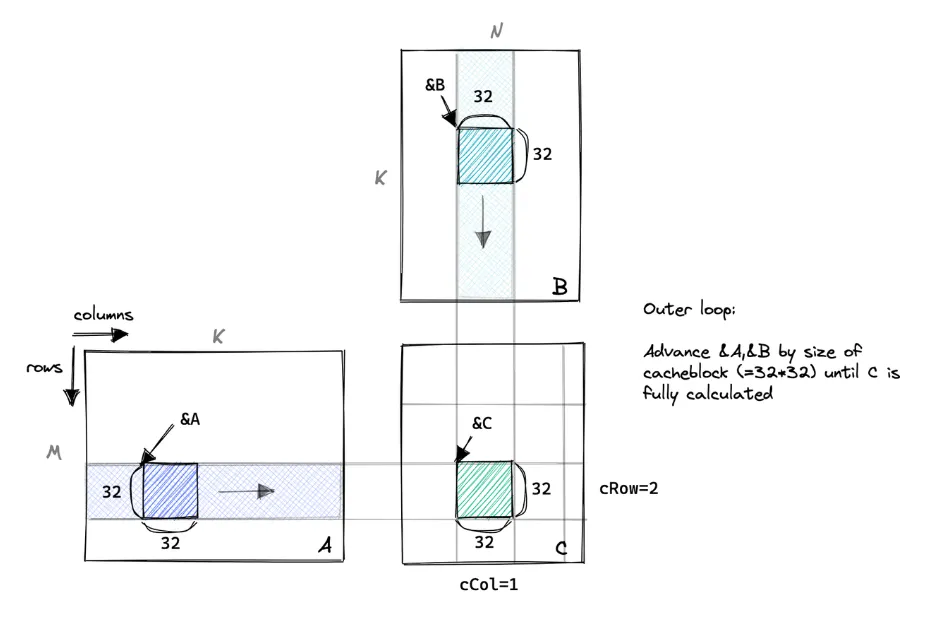
所以对于之前介绍的矩阵乘法的内核,为了实现加速计算,我们将从全局内存中加载 A 的一部分和 B 的一部分到共享内存中。然后我们将尽可能在共享内存上执行运算,每个线程仍然被分配 C 的一个元素。如下图示,我们将沿着 A矩阵 的垂直方向和 B矩阵 的水平方向移动,对 C 进行部分和计算,直到结果计算完成。
3.1 分块运算的数学原理
我们这里再来明确一下前提:
A 矩阵shape:M x K
B 矩阵shape:K x N
C 矩阵 = A 矩阵 * B 矩阵
分块的大小 BLOCKSIZE = 32
我们知道,在朴素内核中,计算 C[x][y] 是一个长点积的过程:
分块的逻辑是: 既然 K 很大(比如 4096),我们不需要一次性把这 4096 个乘法全做了。我们可以把它切成一段一段的。
阶段 0:计算 i 从0到31 的部分和。
阶段 1:计算 i 从32到63 的部分和。
……以此类推。
公式演变为:
所以根据加法结合律,将长向量点积拆分成若干个短向量点积并累加,结果与原始点积完全等效。
3.2 分块运算的步骤
上面我们论述了分块运算在数学上的等效性,下面我们具体来看看,分块运算的具体实现步骤是怎样的?从而为后面kernel代码的理解打好基础。
分块的核心思想是:之前每个线程都要从全局显存上搬运数据参数运算,且这个搬运过程存在重复,比如我们考虑下C[0][1]和C[0][2]的计算过程,A矩阵的第一行就会被搬运两次分别与B矩阵的第一列和第二列相乘。所以分块后,我们一个核心的诉求和想法就是:与其让每个线程去显存搬运数据,不如让整个线程块把一块数据搬到共享内存上,在进行高速运算的同时避免重复的数据搬运。
下面我们来看详细的步骤。
3.2.1 第一阶段:矩阵逻辑上的分块
在全局视角下,矩阵乘法不再是简单的“行乘列”,而被看作是矩阵分块后块与块之间的运算。
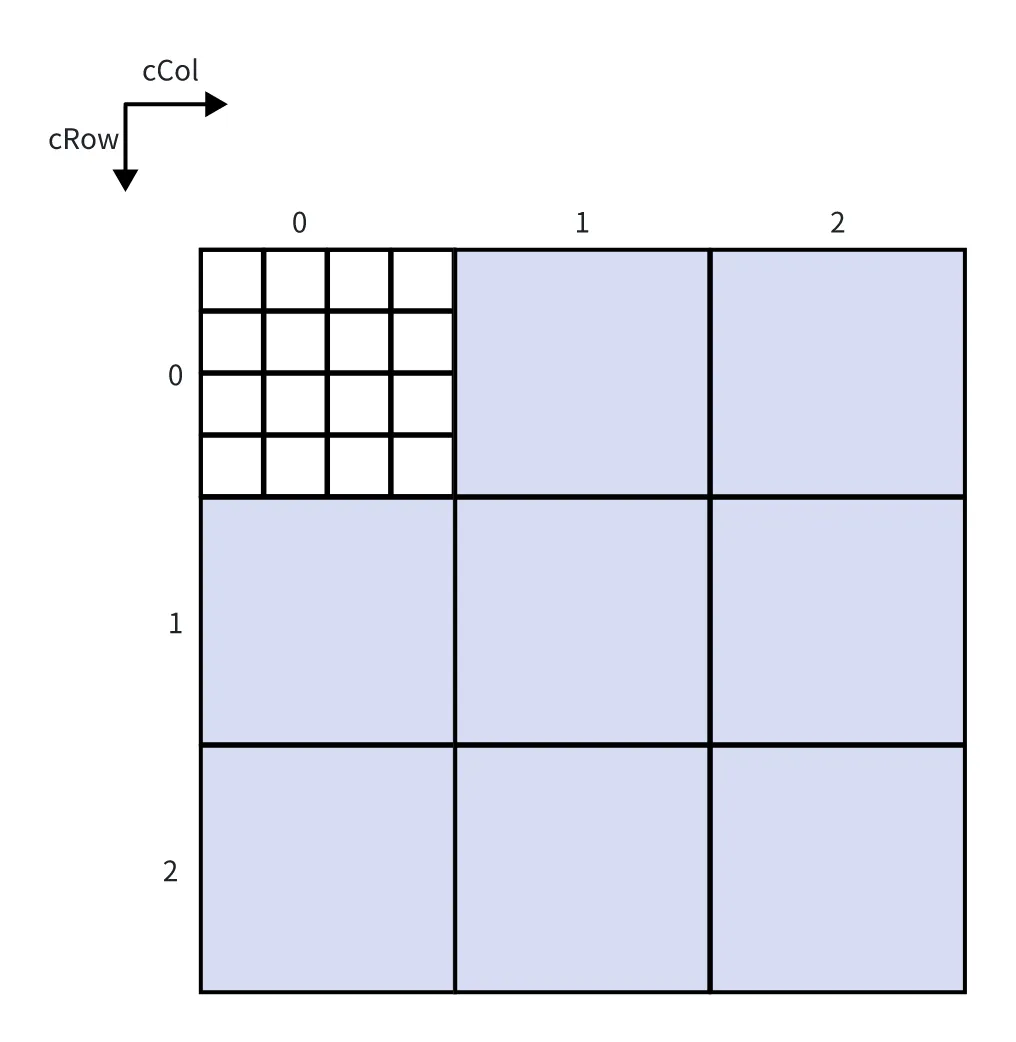
目标块:线程块(Thread Block)负责计算C矩阵中的一个 32*32 的区域(块)。
数据源:为了算出这个32*32 的 C 矩阵中的块,我们需要遍历 A 矩阵对应的“行条”和 B 矩阵对应的“列条”。这里可以参考上面的图形理解,理解这里是理解整个共享内存加速矩阵运算的核心,不懂得可以多看几遍,确保这部分理解后再往后看,否则整个过程可能就看得比较模糊。
滑动块:程序并不是一次性处理整个条带,而是每次移动一个 32*32 的块。
3.2.2 第二阶段:数据搬运
结果:结合前面学习的合并内存访问的知识,一个线程束里1024 个线程同时搬运数据,仅用一次访存周期,就将显存中的 32x32 大小的矩阵块完美地搬运到了片上的共享内存中。
3.2.3 第三阶段:点积计算
Shared Memor准备就绪后,我们就可以分块进行点积计算了。
我们这里现有一个大致的印象即可,这几个阶段只有文字描述会比较抽象,我们下面结合代码来进行说明。
3.3 内核实现
我们先给出整个内核实现,然后再结合内核代码以及上面描述的三个阶段进行深入的理解。
内核代码如下,变量名与上图所对应:
#pragma once#include<algorithm>#include<cstdio>#include<cstdlib>#include<cublas_v2.h>#include<cuda_runtime.h>#define CEIL_DIV(M, N) (((M) + (N)-1) / (N))template <const int BLOCKSIZE>__global__ voidsgemm_shared_mem_block(int M, int N, int K, float alpha, const float *A, const float *B, float beta, float *C) { // 一个线程块负责计算数据C矩阵中的一个BLOCKSIZE * BLOCKSIZE的块 // 将C矩阵按照BLOCKSIZE * BLOCKSIZE分块进行编号 // cRow表示这个线程块想计算的C矩阵块的行号, cCol表示这个线程块想计算的C矩阵的列号 const uint cRow = blockIdx.x; const uint cCol = blockIdx.y; // allocate buffer for current block in fast shared mem // shared mem is shared between all threads in a block __shared__ float As[BLOCKSIZE * BLOCKSIZE]; __shared__ float Bs[BLOCKSIZE * BLOCKSIZE]; // the inner row & col that we're accessing in this thread const uint threadCol = threadIdx.x % BLOCKSIZE; const uint threadRow = threadIdx.x / BLOCKSIZE; // advance pointers to the starting positions A += cRow * BLOCKSIZE * K; // row=cRow, col=0 B += cCol * BLOCKSIZE; // row=0, col=cCol C += cRow * BLOCKSIZE * N + cCol * BLOCKSIZE; // row=cRow, col=cCol float tmp = 0.0; for (int bkIdx = 0; bkIdx < K; bkIdx += BLOCKSIZE) { // Have each thread load one of the elements in A & B // Make the threadCol (=threadIdx.x) the consecutive index // to allow global memory access coalescing As[threadRow * BLOCKSIZE + threadCol] = A[threadRow * K + threadCol]; Bs[threadRow * BLOCKSIZE + threadCol] = B[threadRow * N + threadCol]; // 这里sync的作用是确保当前矩阵A中和B中参与此次计算的块中的元素都搬运到共享内存中 __syncthreads(); A += BLOCKSIZE; B += BLOCKSIZE * N; // 执行当前共享内存中的矩阵块A和B中块的点积运算 for (int dotIdx = 0; dotIdx < BLOCKSIZE; ++dotIdx) { tmp += As[threadRow * BLOCKSIZE + dotIdx] * Bs[dotIdx * BLOCKSIZE + threadCol]; } // 这里还需要进行一次同步,来避免不同线程块中的元素产生错乱 __syncthreads(); } C[threadRow * N + threadCol] = alpha * tmp + beta * C[threadRow * N + threadCol];}
看到这里,大家不妨先结合前面的论述,来看这个kernel的实现,看能不能理清逻辑。如果可以看明白这个kernel逻辑的话,本章后面的内容就可以不用看了,直接看结论和总结部分即可。
如果对这个kernel的逻辑还有不清楚的地方,也没有关系,我们一起来详细拆解下:
我们先来看看矩阵分块是怎么进行的? 将C矩阵按照BLOCKSIZE * BLOCKSIZE分块进行编号,cRow和cCol分别表示目标矩阵C中块的行、列索引,按照我们的设计,一个线程束(warp)负责计算 C 矩阵 中的一个大小为 BLOCKSIZE * BLOCKSIZE 的块。
如下图所示:
注:每个块中元素的数量为BLOCKSIZE * BLOCKSIZE,图中数量均不是真实数量,仅供示意
所以首先就有了:
const uint cRow = blockIdx.x;const uint cCol = blockIdx.y;
再往下看:
__shared__ float As[BLOCKSIZE * BLOCKSIZE];__shared__ float Bs[BLOCKSIZE * BLOCKSIZE];
这里比较好理解,分别申请两块大小为BLOCKSIZE * BLOCKSIZE的共享内存空间用于存放A矩阵的块和B矩阵的块。
继续往下看:
// advance pointers to the starting positionsA += cRow * BLOCKSIZE * K; // row=cRow, col=0B += cCol * BLOCKSIZE; // row=0, col=cColC += cRow * BLOCKSIZE * N + cCol * BLOCKSIZE; // row=cRow, col=cCol
这几行代码是理解分块计算流程的其中一个关键所在,这里分别是在计算A矩阵、B矩阵和C矩阵在当前分块计算中所处的位置。
其中,cRow我们可以理解为在垂直方向上滑过的块的数量,所以cRow*BLOCKSIZE就表示实际滑过的矩阵的行数,cRow*BLOCKSIZE*K就表示当前线程块的起始行的位置。
矩阵B可以按类似的思路进行理解,所以cCol我们就可以理解为在水平方向滑过的块的数量,那么cCol * BLOCKSIZE就表示当前线程块的起始列的位置。
矩阵C中当前块的位置则由矩阵A和矩阵B的位置共同决定,也就是A矩阵滑过的行数加上B矩阵滑过的列数:cRow * BLOCKSIZE * N + cCol * BLOCKSIZE。
再往下就到了计算的核心逻辑—两层for循环了。
外层的for循环是为了计算C矩阵中的一个BLOCKSIZE*BLOCKSIZE大小的块,在A矩阵的行”条带“和B矩阵的列”条带“上分别滑动,确保整个条带的所有元素都参与计算,这样在数学上C矩阵中大小为BLOCKSIZE*BLOCKSIZE的块内元素在数学上才是正确的。
而内层的for循环是负责A矩阵和B矩阵的”条带“在共享内存中的块对应元素的具体点积运算。
最终算得的tmp是C[threadRow, threadCol]位置的元素,最终实现的效果还是一个线程负责计算矩阵C中的一个元素。
现在我们来看其中的某一个线程(假设是坐标为 (threadRow, threadCol) 的线程):
它要负责算出 C 矩阵中对应位置的那个值。
它会从 As 里取走一整行(32 个数),从 Bs 里取走一整列(32 个数)。
它在本地共享内存里快速完成这 32 次乘加运算。
关键点:注意看,As 中的这一行数据,不仅被这个线程用了,也被同行的其他 31 个线程共用了;Bs 中的这一列数据同理。这就是数据复用,它把显存压力降低了 32 倍。这也是分块可以加速矩阵运算的核心所在。
3.4 整个过程的总结
我们可以把代码里的 for 循环想象成下面的动态过程:
对齐:线程块定位到 A行条 的第一个块和 B列条 的第一个块。
搬运:1024 个线程同时搬砖 -> __syncthreads()(等所有人搬完)。
内积:每个线程在 Shared Memory 内部完成小块的点积累加。
同步:__syncthreads()(等所有人算完,防止有人提前去搬下一块)。
滑动:A += BLOCKSIZE,B += BLOCKSIZE * N,移动到下一个分块。
重复:重复上述过程直到 K 维度遍历完毕。
写回:将积攒在 tmp 里的最终结果一次性存入 C 矩阵。
3.5 测试结果
通过在 RTX5060Ti 上测试大小为 4096 的矩阵,我们发现这个内核实现了 1855.5 GLOPS 的 性能表现,比之前介绍的全局内存合并访问的版本的 1522.2 GFLOPS 提高了约 22%。
4. 思考
在上面的计算过程中,你有没有注意到一个细节:既然同一个warp中每个线程都要读 As 的一行,那这 32 个线程同时读同一个地址时,会发生硬件层面的“访问冲突”吗?
5. 参考
https://docs.nvidia.com/cuda/cuda-programming-guide/02-basics/writing-cuda-kernels.html#
https://siboehm.com/articles/22/CUDA-MMM