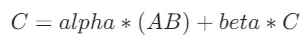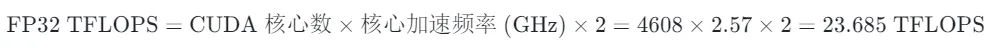1. 写在前面
CUDA 作为基于 SIMT(Single Instruction, Multiple Threads,单指令多线程)架构的并行编程模型,其内存系统的设计堪称核心亮点 —— 全局内存、共享内存、本地内存、寄存器等多种内存类型各司其职,不仅容量差异显著,访问速度更是相差数个数量级。在现代并行计算场景中,尤其是大语言模型(LLM)相关算子这类高算力需求场景下,性能瓶颈早已不再局限于硬件算力本身,而是更多地受制于内存容量的上限与访问效率的高低。可以说,CUDA Kernel 的性能表现,与内存的选型策略、访问模式密切相关,能否合理运用不同层级的内存,直接决定了能否写出真正高性能的 CUDA 内核。
2. CUDA内存层次结构
接下来,我们先来系统梳理 CUDA 的内存层次结构,建立对各类内存特性的清晰认知;随后聚焦一个关键优化点 ——紧凑的全局内存访问(Coalesced Global Memory Access),通过具体案例拆解如何通过调整内存访问方式,显著提升矩阵乘法 Kernel 的执行性能。
在《CUDA 学习笔记》系列中,我会持续记录 CUDA 学习过程中的核心概念、设计原则与实践技巧,和大家一起一步步解锁高性能 CUDA Kernel 的编写逻辑。
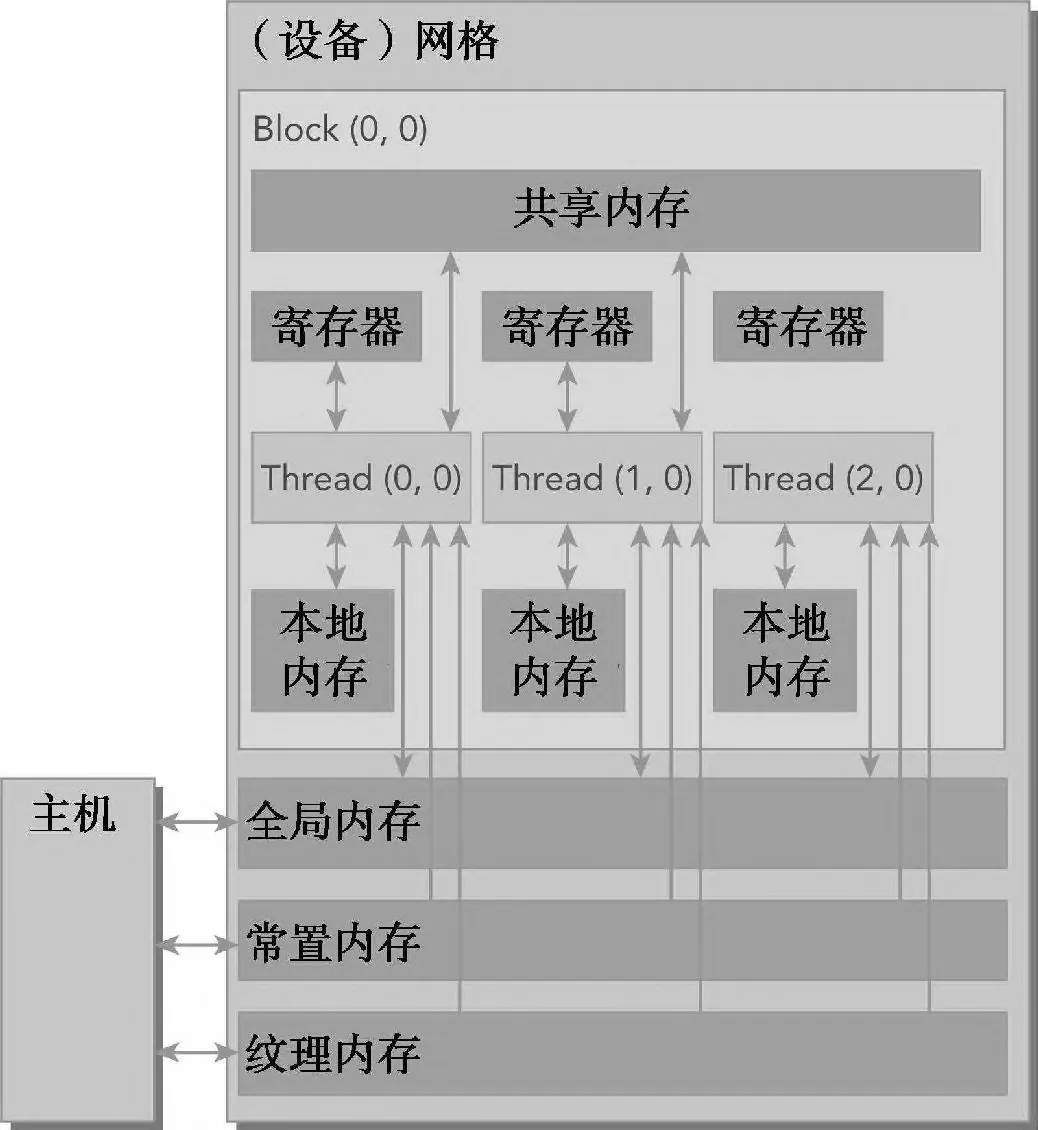
图1 CUDA内存的层次结构
如图1所示,CUDA 设备拥有多级独立的内存空间,CUDA 内核中的线程可按需访问不同的内存空间。下表对 CUDA 中常用的显存类型做了完整总结,涵盖各类显存的线程作用域、生命周期与物理位置。
内存类型 | 作用域 | 生命周期 | 位置 |
全局显存 | Grid | 应用 | 设备 |
常量显存 | Grid | 应用 | 设备 |
共享显存 | Block | 内核 | SM |
本地显存 | Thread | 内核 | 设备 |
寄存器 | Thread | 内核 | SM |
其中,在 CUDA 编程的性能优化实践中,全局显存、共享显存与寄存器是我们应该重点关注的三类核心显存层级。三者共同构成了 GPU 核心的内存层次体系,在存储容量与访问速度上呈现出鲜明且规律的层级特征:
从存储容量维度:寄存器的容量最小,共享显存次之,全局显存则拥有 GPU 中最大的存储空间;
从数据访问速度维度:寄存器的访问速度最快,共享显存次之,全局显存的访问速度则相对最慢。
除此之外,这三类核心内存的线程可见范围(作用域),也遵循着由窄到宽的逐级拓展规律:
寄存器:属于线程私有内存,仅能被当前线程独立访问,是 CUDA 核函数中用于存储临时变量的;
共享显存:作用域覆盖同一个线程块 (Block),可供块内所有线程共同访问与读写,是实现线程间高效协作通信的核心机制;
全局显存:作用域覆盖整个 GPU 设备,我们日常提及的显卡显存容量(如 16GB、24GB、32GB 显存),所指的就是全局显存的容量,它能被设备上的所有线程无差别访问。
也正是基于这样的内存层级特性,高性能 CUDA Kernel 的核心优化思路之一,就是尽可能让数据的访问向「速度更快、容量更小」的内存层级靠拢,减少对低速以及全局显存的无效访问。这也是我们接下来要探讨的紧凑全局内存访问(Coalesced Global Memory Access)优化的核心出发点。
3. 如何使用CUDA实现矩阵乘法的计算
矩阵乘法是 LLM 训练和推理的核心算子,了解矩阵乘法是如何实现和优化的,对深入了解LLM 训练和推理中的 Infra 细节实现是有很大帮助的。
我们的目标是高效进行下列的矩阵运算:
我们先来看一个只实现基础功能的最 Naive Kernel 实现:
3.1 Naive Kernel 代码
#pragma once#include<cstdio>#include<cstdlib>#include<cublas_v2.h>#include<cuda_runtime.h>/*Matrix sizes:MxK * KxN = MxN相乘的A矩阵和B矩阵的形状分别为:MxK,KxNC矩阵形状为:MxN*/__global__ voidsgemm_naive(int M, int N, int K, float alpha, constfloat *A, const float *B, float beta, float *C) { // 这里的x,y分别指的是当前线程负责计算的C矩阵中元素的位置C[x][y] // 描述了线程编号和该线程负责计算矩阵元素的对应关系 const uint x = blockIdx.x * blockDim.x + threadIdx.x; const uint y = blockIdx.y * blockDim.y + threadIdx.y; // if statement is necessary to make things work under tile quantization if (x < M && y < N) { float tmp = 0.0; // 这个for循环是在计算A矩阵的第x行(shape:1xK)和B矩阵的第i列(shape:Kx1)的点积结果(对应C矩阵[x,y]位置(x*N+y)的元素) for (int i = 0; i < K; ++i) { tmp += A[x * K + i] * B[i * N + y]; } // C = α*(A@B)+β*C C[x * N + y] = alpha * tmp + beta * C[x * N + y]; }}
3.2 Naive Kernel 的内存访问模式
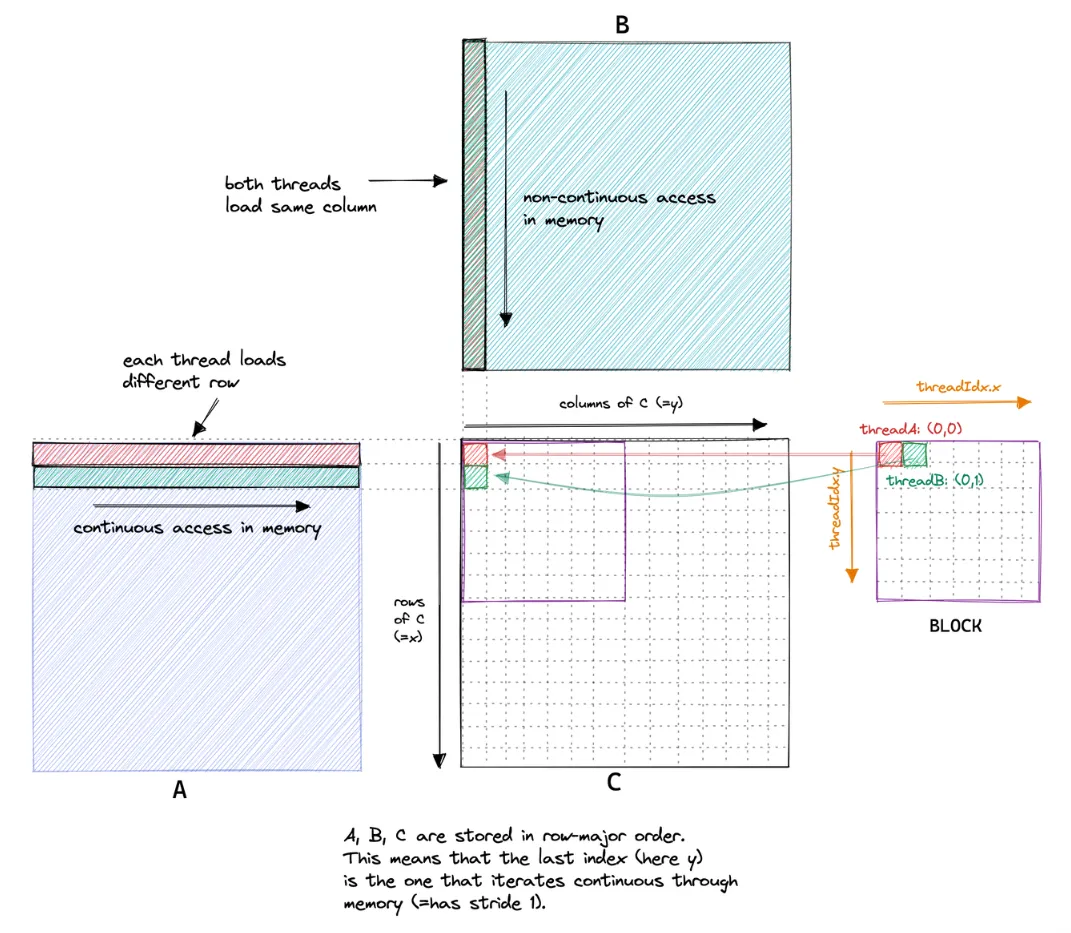
在上述的 Naive Kernel 中,同一个block中的两个线程,比如第一行Thread(0, 0)和Thread(0, 1)这两个线程,按照我们前面的定义,分别负责计算 C[0, 0] 和 C[1, 0] 位置的元素;而 C[0, 0] 是通过加载 A[0, :] 和 B[:, 0] 计算而来;C[1, 0] 是通过加载 A[1, :] 和B[:, 0] 计算而来;也就是说C矩阵中的一行需要加载A矩阵不同的行和B矩阵中的同一列计算而得。
假设矩阵A、B的维度都是(4096,4096),我们借一张图来展示这个过程以及目标C矩阵和线程布局的对应关系:
图2 Naive Kernel矩阵乘法示意图
总的计算量:(4096x4096)x(2x4096+1)= 137 GFLOPs
在 RTX5060 Ti 平台上进行测试,执行时间:0.69s
所以,计算性能 = 总的计算量 / 计算时间 = 137 GFLOPs / 0.69s = 198.55 GFLOPS
而 RTX5060 Ti 官方理论性能为:
通过实际测试可以发现,我们这个 Naive Kernel 目前达到的计算性能和官方理论性能有太大差距。
那么我们要如何来提升这个矩阵乘法的性能呢?一种可行的方法是通过优化内核的内存访问模式,来使得对于全局内存(显存)的访问合并为更少的访问次数,从而提升矩阵乘法 CUDA Kernel 的计算性能。
3.3 Naive Kernel 的启动方式
在这个内核中,我们使用网格(grid)、块(block)、线程(Thread)的层次结构,为每个线程分配目标矩阵C中的一个唯一位置,然后使用该线程计算矩阵A对应行与矩阵B对应列的点积结果,并将结果写入C矩阵。由于C矩阵中的每个位置仅由一个线程写入,所以我们在这里不需要进行同步,启动内核的方式如下:
// 创建必要数量的块以映射整个C矩阵dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1); // 32 * 32 = 1024 线程每个块dim3 blockDim(32, 32, 1); // 在设备端异步启动 kernel 的执行// 在主机端启动 kernel,并立即返回(异步)sgemm_naive<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
4. 如何通过全局内存合并访问优化矩阵乘法的性能
在深入探讨全局内存访问合并之前,我们需要首先了解“warp”(线程束)这一概念。在具体的计算过程中,一个线程块中相邻的线程会被分组成warp,每个warp通常包含32个线程,同一个warp内的线程执行相同的指令。
全局内存通过 32 字节的内存事务进行访问。当一个 CUDA 线程请求全局内存中的一个字节数据时,相关的 warp 会将该 warp 中所有线程的内存请求合并成满足请求所需数量的内存事务,具体取决于每个线程访问的字节大小以及内存地址在各个线程中的分布。例如,如果一个线程请求一个 4 字节的数据,但该 warp 会向全局内存请求的实际内存事务总共会有 32 字节。为了最有效地使用内存系统,warp 应该使用单个内存事务中获取的所有内存数据(32字节)。也就是说,如果一个线程正在请求全局内存中的一个 4 字节的数据,而内存事务大小是 32 字节,如果该 warp 中的其他线程可以使用从这 32 字节请求中获得的其他 4 字节数据,这样内存系统才能得到最有效的使用。
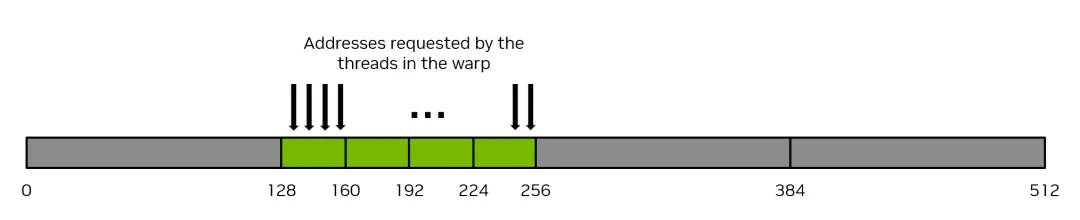
举一个简单的例子,如果 warp 中的连续线程请求内存中的连续 4 字节字,那么 warp 将总共请求 128 字节的内存,这 128 字节所需的内存将通过四次 32 字节的内存事务获取,这样内存系统的利用率是 100%。也就是说,warp 100% 利用了内存带宽。下图说明了这种完美合并的内存访问示例。
图3 完美合并的内存访问示例
相反,最糟糕的情况是当连续的线程访问内存中彼此相距 32 字节或更远的元素时。在这种情况下,warp 将被迫为每个线程发出一个 32 字节的内存事务,内存传输的总字节数将是 32 字节乘以 32 线程/warp = 1024 字节。然而,使用的内存量只有 128 字节(warp 中每个线程 4 字节),因此内存利用率仅为 128 / 1024 = 12.5%。这是对内存系统非常低效的使用。下图说明了这种未对齐的内存访问示例。
图4 未对齐的内存访问示例
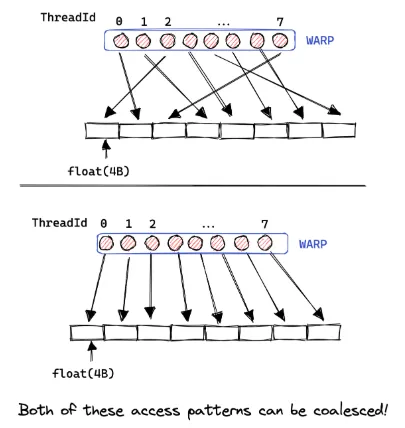
实现连续内存访问最直接的方法是让连续的线程访问内存中的连续元素,但实现连续内存访问并不要求连续的线程访问内存中的连续元素,这只是实现连续访问的典型方式。只要 warps 中的所有线程以某种线性或排列方式访问来自相同 32 字节内存段的元素,就会发生连续内存访问。如下如所示的两种方式,都可以实现连续内存访问。
图5 来自相同32字节内存段内的元素都可以进行连续内存访问
总结来说,实现连续内存访问的最佳方法是最大化使用字节数与传输字节数的比率。
4.1 线程的层次结构
线程被组织成线程块,线程块再被组织成网格。网格可以是 1、2 或 3 维的,网格的大小可以在内核中通过 gridDim 内置变量查询。线程块也可以是 1、2 或 3 维的。线程块的大小可以在内核中通过 blockDim 内置变量查询。线程块的索引可以通过 blockIdx 内置变量查询。在线程块内,线程的索引使用 threadIdx 内置变量获取。这些内置变量用于为每个线程计算唯一的全局线程索引,从而使每个线程能够根据需要从全局内存加载/存储特定数据并执行不同的代码路径。
gridDim.[x|y|z] : 在 x 、 y 和 z 维度上的网格大小。这些值在内核启动时设置。
blockDim.[x|y|z] : 在 x 、 y 和 z 维度上的块大小。这些值在内核启动时设置。
blockIdx.[x|y|z] : 在 x 、 y 和 z 维度上的块索引。这些值根据正在执行的块而变化。
threadIdx.[x|y|z] : 在 x 、 y 和 z 维度中的线程索引。这些值会根据正在执行的线程而变化。
下图是一个简单的二维网络和一维线程块示例:
图6 网格-线程块简单示例
假设有这样一个线程块:
blockDim.x = 4
blockDim.x = 16
blockDim.z = 64
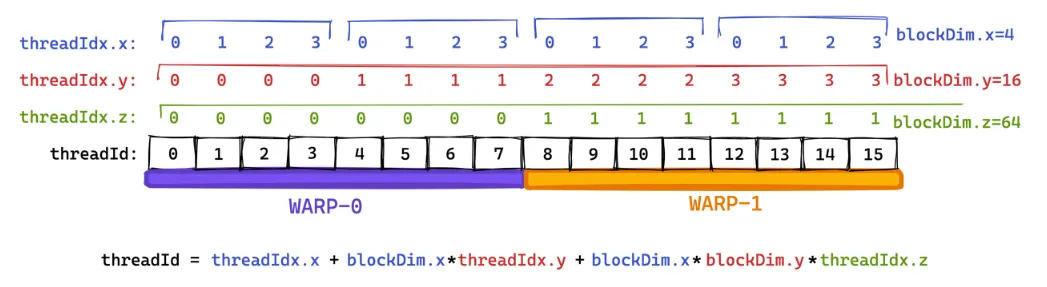
同时为了便于画图表示,我们还假设一个warp有8个线程(实际上总是32个)。
图7 全局线程Id的表示
通过上面的分析和图示,我们可以知道在多维线程块和网格表示方法中, thread、block、grid都有x, y, z三个维度,其中第一个维度索引 x 移动最快,其次是 y ,然后是 z ,这意味着在线程索引的线性化中, threadIdx.x 的连续值表示连续的线程,threadIdx.y 的步长为 blockDim.x , threadIdx.z 的步长为 blockDim.x * blockDim.y。
线程被分组为 warp 的方式是基于连续的全局threadId,如果我们的线程块(block)是三维的,那么全局 threadId 的计算方式如下:
threadId = blockDim.x*blockDim.y*threadIdx.z + blockDim.x*threadIdx.y + threadIdx.x
全局threadId和网格-线程块表示法的转换过程我们可以这样理解:
本质上是按照 “面 --> 行 --> 点” 的次序,将三维空间内的位置进行线性累加:
首先,是“面”的堆叠:通过 (blockDim.x * blockDim.y) * threadIdx.z,我们将当前线程之前所有完整的 X-Y平面扁平化。这相当于在 Z 轴方向上完成了一次跨越,算出了前面所有“层”的总线程数。
然后,是“行”偏移的累加:进入当前的 X-Y 平面后,利用 blockDim.x * threadIdx.y 进一步定位。它表示在当前层内,跳过前面所有完整的 X轴行,将纵向位置转化为数量。
最后,锁定“点”的位置:加上末尾的 threadIdx.x,即在当前X轴行中的具体偏移量,从而精准定位到目标线程。
将这三部分相加,便得到了该线程唯一的一维全局索引。
三维线程块可参考下图来理解:
图8 三维线程块
4.2 全局内存访问如何进行合并
通过上面的分析,我们知道确保全局内存访问的正确合并是编写高性能 CUDA 内核时最重要的性能考虑之一。下面我们结合例子来具体分析。
通过上述一维全局线程ID的计算方式,我们发现了一个非常重要的内存访问规则:
因为 threadIdx.x 是公式里唯一没有乘数、变动最快的一项,这意味着:在硬件执行时,threadIdx.x 相邻的线程,其计算出的一维 ID 也是连续的。
按照这个思路,我们分析 Naive Kernel 会发现,随着threadIdx.x的连续变化,同一warp内不同线程分别读取A矩阵同一列不同行的数据,读取和写入C矩阵同一列不同行的数据,这对于按行优先顺序存储的矩阵,在内存访问上就是不连续的,也就无法通过内存事务进行内存访问的合并。
而在这个版本 Kernel 的实现中,我们就要考虑“让 threadIdx.x 对应矩阵中连续变化的列”,因为只有这样,才能实现内存合并访问(Memory Coalescing)。
实际上,相邻的 threadId 线程会成为同一个 warp 的一部分。下面我尝试用一个较小的“warp size”(8 个线程)来说明这一点(实际的 warp 总是包含 32 个线程)。
线程属于同一个 warp 的顺序内存访问可以被分组并作为一个整体执行,这被称为全局内存访问合并(或者叫紧凑的全局内存访问)。在优化内核的 GMEM 内存访问以达到峰值带宽时,这一点尤为重要。
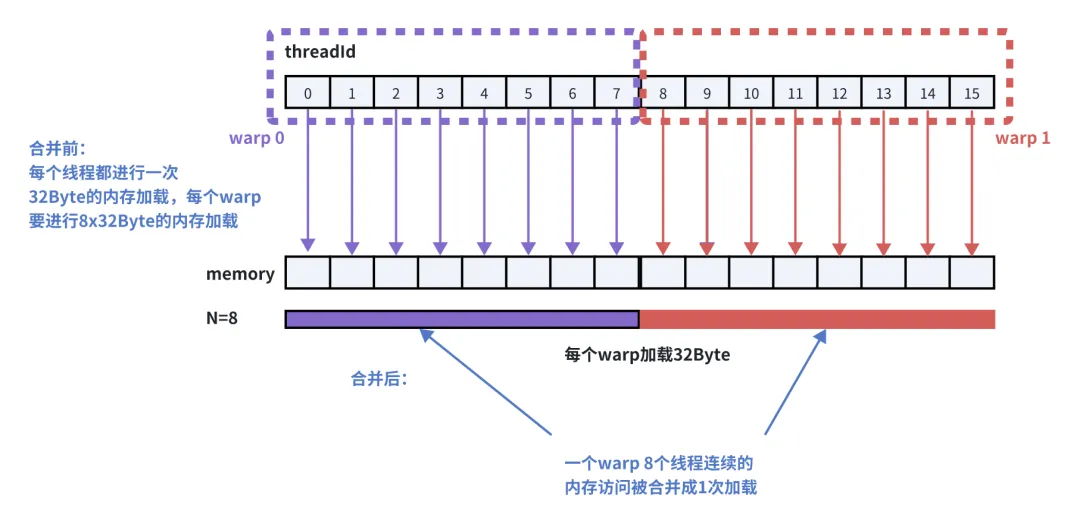
下面是一个例子,假设1个线程需要访问一个4 Byte浮点数据,同一个warp中的线程访问的数据的内存地址是连续的,那么每个warp使用1次32B的加载内存事务就可以完成8个线程(一个warp)数据的访问,使用字节数与传输字节数的比率达到了理论最大值(100%)。而如果同一个warp中数据的内存地址不连续的话,就需要根据实际情况使用多次内存事务进行加载,这就导致使用字节数与传输字节数的比率达不到理论最大值。
图9 warp内线程内存访问合并示意图
上面的示意图中我们假设了一个warp有8个线程,全局内存通过32Byte的内存事务进行访问。实际上,一个warp有32个线程,而GPU内存事务除了支持 32Byte 外,还支持 64Byte 和 128Byte 的内存访问。对于实际情况来说,如果每个线程从全局内存加载一个 32 位浮点数(4Byte),一个warp也就是有128Byte(4Byte x 32)的数据量需要从全局内存加载,如果这32个数据在内存中是连续且对齐的,线程调度器就可以通过一次内存事务进行加载(比如按128Byte),否则的话就要进行多次加载。关于内存事务支持的Byte数以及内存访问合并的细节,可以参考CUDA编程中的缓存行、扇区、事务这些概念进行深入了解。
4.3 Coalescing Kernel 的内存访问模式
Coalescing Kernel即一个warp内的线程内存访问进行合并的Kernel。
同一 warp 中的线程具有连续的 threadIdx.x ,而矩阵在内存中是按行优先(row major)的顺序存储的,也就是说同一行相邻列的元素是连续存储的。如果可以在相邻线程中访问同一行中相邻列,同一warp就可以实现合并内存访问。而对于 Naive Kernel,我们矩阵C的横坐标x = ... + threadIdx.x ,这样threadIdx.x连续变化的时候,A[x * K + i] 和 C[x * N + y]每次都会访问A矩阵和C矩阵同一列不同行的数据,这样在行优先存储的内存中访问就是非连续/跨步的,也就是说:
线程 0 读 A[row_0, col_i]
线程 1 读 A[row_1, col_i]
这样一个warp内就必须发起32次独立的内存请求,无法进行内存访问的合并。
为了实现内存访问的合并,我们可以改变将结果矩阵 C 中的位置分配给线程的方式。这种全局内存访问模式的改变如下所示:
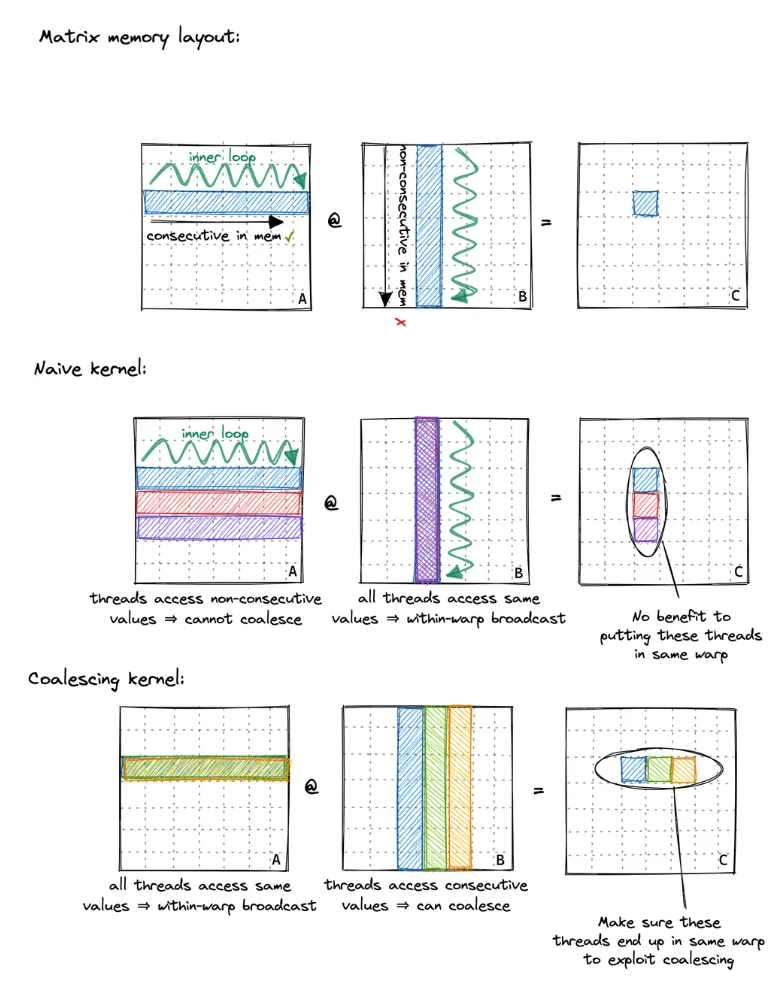
图10 Coalescing Kernel 的内存访问模式
这个图参考了 siboehm 的博客(链接见参考),这里对这个图做一下解释说明。
最上面的Matrix memory layout说明了矩阵中的元素在内存中的存储方式,也就是按照行优先的方式线性存储。
中间的 Naive Kernel 和 Coalescing Kernel 关于连续和非连续的论述看起来可能会比较困惑(我刚看的时候是这样的),我们这里要抓住一点即可,这里说的连续和不连续,指的是相邻线程访问的矩阵的数据是否是连续的,我们可以从C矩阵来看,因为C矩阵直接映射了矩阵坐标和线程布局的转换关系,然后再倒推A矩阵和B矩阵应该是怎么样的。通过图示我们很容易可以看出来,Naive Kernel 的C矩阵的内存访问就是非连续的,而 Coalescing Kernel 的C矩阵的内存访问就是连续的。
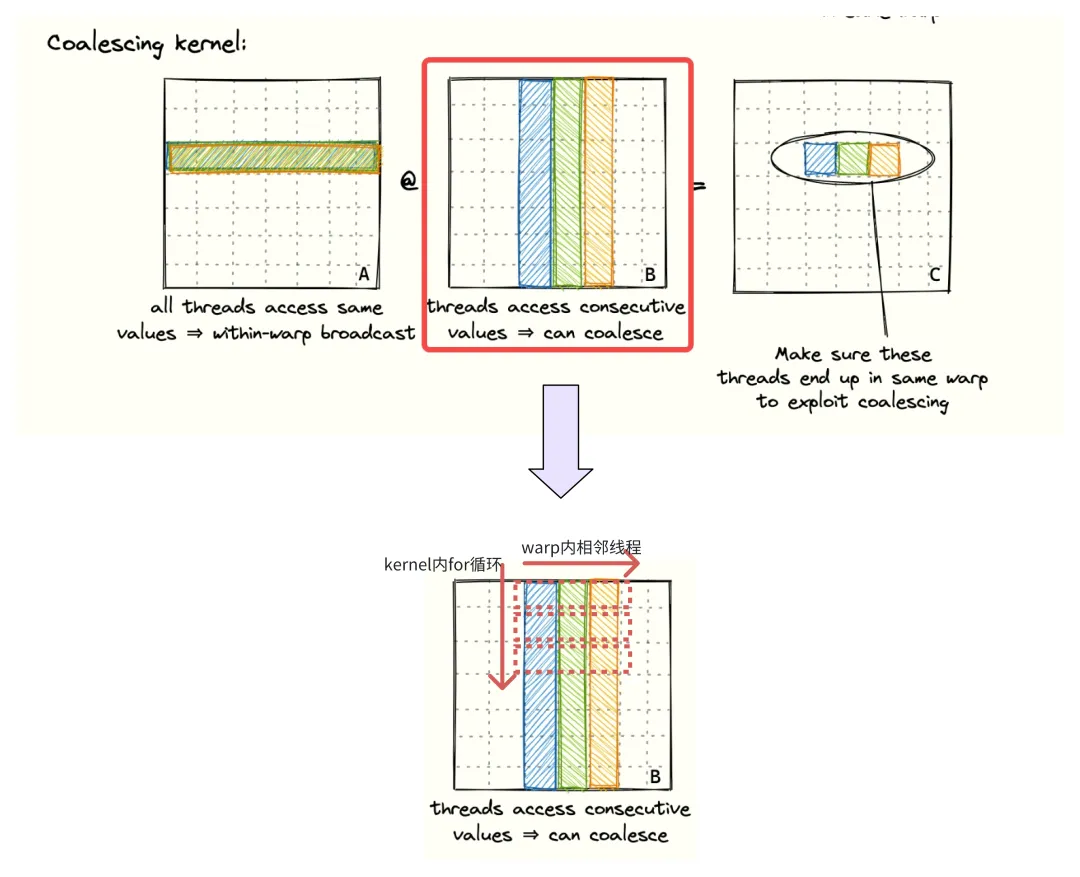
至于A矩阵和B矩阵,我们可以按照下图所示的方式在 Kernel 内for循环和warp内相邻线程这两个维度理解数据存放是否连续。对于 Coalescing Kernl 的B矩阵,随着Kernel内的for循环,每一个warp内线程加载的数据是同一行的相邻列数据,这就可以进行内存访问的合并。
图11 Coalescing Kernel B矩阵内存访问模式分析
对于 Naive Kernel 的A矩阵,我们也可以使用类似的方法进行分析。
4.4 Coalescing Kernel 代码
要实现这一点,我们只需要更改前两行 x, y 索引的计算方式:
#pragma once#include<cassert>#include<cstdio>#include<cstdlib>#include<cublas_v2.h>#include<cuda_runtime.h>/*Matrix sizes:MxK * KxN = MxN相乘的A矩阵和B矩阵的形状分别为:MxK,KxNC矩阵形状为:MxN*/template <const uint BLOCKSIZE>__global__ voidsgemm_global_mem_coalesce(int M, int N, int K, float alpha, const float *A, const float *B, float beta, float *C) { const uint x = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE); const uint y = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE); // if statement is necessary to make things work under tile quantization if (x < M && y < N) { float tmp = 0.0; for (int i = 0; i < K; ++i) { tmp += A[x * K + i] * B[i * N + y]; } C[x * N + y] = alpha * tmp + beta * C[x * N + y]; }}
通过测试,我们得到了合并内存访问后的Kernel的执行时间和计算性能:
我们发现,仅仅通过优化内存访问模式,我们就实现了6x以上的提速。
4.5 Coalescing Kernel的启动方式
在这个内核中,我们只使用了一维 block,我们可以这样调用这个kernel:
// gridDim的定义和Naive内核是一样的dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32));// blockDim定义成一维,而且大小是固定的,通过整除和取余来分别索引x和y坐标dim3 blockDim(32 * 32);sgemm_global_mem_coalesce<32><<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
5. 总结
本文以矩阵乘法为核心线索,层层递进论证全局内存合并访问对于矩阵乘法CUDA Kernel性能优化的逻辑,核心内容总结如下:
先介绍CUDA内存层次结构,再实现原始矩阵乘法内核(Naive Kernel)并完成实际测试,并通过结合RTX5060 Ti 官方理论计算性能明确该内核的性能具有很大瓶颈;
基于原始内核的瓶颈,引出本文核心内容——紧凑的全局内存访问;
为厘清全局内存访问合并(Coalescing)逻辑,系统介绍CUDA线程层次结构,涵盖网格-线程块的三维布局及与全局threadId的转换关系,最终得出关键结论:实现全局内存访问合并的核心,是让threadIdx.x对应矩阵中连续变化的列;
结合Coalescing内核的具体实现,分析全局内存访问的合并过程;实测数据显示,Coalescing内核的计算时间相较于Naive内核可实现6倍以上提速,充分验证了该优化方案的有效性。
6. 参考
https://docs.nvidia.com/cuda/cuda-programming-guide/02-basics/writing-cuda-kernels.html#writing-cuda-kernels-coalesced-global-memory-access
https://siboehm.com/articles/22/CUDA-MMM