《C++实战笔记-罗剑锋》学习笔记3

11 | 一枝独秀的字符串:C++也能处理文本?
认识字符串
所谓的字符串,就是字符的序列。
string 其实并不是一个“真正的类型”,而是模板类 basic_string 的特化形式,是一个 typedef:
usingstring = std::basic_string<char>; //string其实是一个类型别名
Unicode 的目标是用一种编码方式统一处理人类语言文字,使用 32 位(4 个字节)来保证能够容纳过去或者将来所有的文字。
但这就与 C++ 产生了矛盾。因为 C++ 的字符串源自 C,而 C 里的字符都是单字节的 char 类型,无法支持 Unicode。
为了解决这个问题,C++ 就又新增了几种字符类型。C++98 定义了wchar_t,到了 C++11,为了适配 UTF-16、UTF-32,又多了char16_t、char32_t。于是,basic_string 在模板参数里换上这些字符类型之后,就可以适应不同的编码方式了。
usingwstring = std::basic_string<wchar_t>;using u16string = std::basic_string<char16_t>;using u32string = std::basic_string<char32_t>;
Unicode 还有一个UTF-8 编码方式,与单字节的 char 完全兼容,用 string 也足以适应大多数的应用场合。
作者建议只用 string,而且在涉及 Unicode、编码转换的时候,尽量不要用 C++,目前它还不太擅长做这种工作,可能还是改用其他语言来处理更好。
用好字符串
string 是一个功能比较齐全的字符串类,可以提取子串、比较大小、检查长度、搜索字符……基本满足一般人对字符串的“想象”。
string str = "abc";assert(str.length() == 3);assert(str < "xyz");assert(str.substr(0, 1) == "a");assert(str[1] == 'b');assert(str.find("1") == string::npos);assert(str + "d" == "abcd");
字符串和容器完全是两个不同的概念。
字符串是“文本”,里面的字符之间是强关系,顺序不能随便调换,否则就失去了意义,通常应该视为一个整体来处理。
而容器是“集合”,里面的元素之间没有任何关系,可以随意增删改,对容器更多地是操作里面的单个元素。
把每个字符串都看作是一个不可变的实体,才能在C++ 里真正地用好字符串。
如果确实需要存储字符的容器,比如字节序列、数据缓冲区,最好改用 vector<char>。
1. 字面量后缀
C++11 为方便使用字符串,新增了一个字面量的后缀“s”,明确地表示它是 string 字符串类型,而不是 C 字符串,这就可以利用 auto 来自动类型推导,而且在其他用到字符串的地方,也可以省去声明临时字符串变量的麻烦,效率也会更高:
usingnamespacestd::literals::string_literals;//必须打开名字空间auto str = "std string"s; // 后缀s,表示是标准字符串,直接类型推导assert("time"s.size() == 4); // 标准字符串可以直接调用成员函数
为了避免与用户自定义字面量的冲突,后缀“s”不能直接使用,必须用 using 打开名字空间才行,这是它的一个小缺点。
2. 原始字符串(Raw string literal)
比原来的引号多了一个大写字母 R 和一对圆括号:
auto str = R"(nier:automata)"; // 原始字符串:nier:automata
C++ 的字符有“转义”的用法,在字符前面加上一个“\”,就可以写出“\n”“\t”来表示回车、跳格等不可打印字符。 有时不想转义,只想要字符串的“原始”形式。特别是在用正则表达式的时候,由于它也有转义,两个转义效果“相乘”,就很容易出错。 比如说,我要在正则里表示“ $ ”,需要写成" \$ ",而在 C++ 里需要对“\”再次转义,就是“ \\\$ ”,你能数出来里面到底有多少个“\”吗? 如果使用原始字符串的话,就没有这样的烦恼了,它不会对字符串里的内容做任何转义,完全保持了“原始风貌”,即使里面有再多的特殊字符都不怕:
auto str1 = R"(char""'')"; // 原样输出:char""''auto str2 = R"(\r\n\t\")"; // 原样输出:\r\n\t\"auto str3 = R"(\\\$)"; // 原样输出:\\\$auto str4 = "\\\\\\$"; // 转义后输出:\\\$
想要在原始字符串里面写引号 + 圆括号的形式,就是在圆括号的两边加上最多 16 个字符的特别“界定符”(delimiter),这样就能够保证不与字符串内容发生冲突:
auto str5 = R"==(R"(xxx)")==";// 原样输出:R"(xxx)"
3. 字符串转换函数
C 函数 atoi()、atol(),它们的参数是 C 字符串而不是string;
C++11 就增加了几个新的转换函数:
stoi()、stol()、stoll() 等把字符串转换成整数;
stof()、stod() 等把字符串转换成浮点数;
to_string() 把整数、浮点数转换成字符串。
4. 字符串视图类
大字符串的拷贝、修改代价很高,所以我们通常都尽量用 const string&,但有的时候还是无法避免(比如使用 C 字符串、获取子串)。
在 C++17 里,就有这么一个完美满足所有需求的东西,叫string_view。它是一个字符串的视图,成本很低,内部只保存一个指针和长度,无论是拷贝,还是修改,都非常廉价。
C++11 里实现一个简化版本:
classmy_string_viewfinal // 简单的字符串视图类,示范实现{public:using this_type = my_string_view; // 各种内部类型定义using string_type = std::string;using string_ref_type = conststd::string &;using char_ptr_type = constchar *;using size_type = size_t;private: char_ptr_type ptr = nullptr; // 字符串指针 size_type len = 0; // 字符串长度public: my_string_view() = default; ~my_string_view() = default; my_string_view(string_ref_type str) noexcept : ptr(str.data()), len(str.length()) { }public:char_ptr_type data()const// 常函数,返回字符串指针{return ptr; }size_type size()const// 常函数,返回字符串长度{return len; }};
正则表达式
C++ 正则表达式主要有两个类:
- regex:表示一个正则表达式,是 basic_regex 的特化形式;
- smatch:表示正则表达式的匹配结果,是 match_results 的特化形式。
C++ 正则匹配有三个算法,注意它们都是“只读”的,不会变动原字符串:
- regex_search():在字符串里查找一个正则匹配;
- regex_replace():正则查找再做替换。
在写正则的时候,记得最好要用“原始字符串”,不然转义符绝对会把你折腾得够呛。
auto make_regex = [](constauto &txt) // 生产正则表达式{returnstd::regex(txt);};auto make_match = []() // 生产正则匹配结果{returnstd::smatch();};auto str = "neir:automata"s; // 待匹配的字符串auto reg = make_regex(R"(^(\w+)\:(\w+)$)"); // 原始字符串定义正则表达式auto what = make_match(); // 准备获取匹配的结果assert(regex_match(str, what, reg)); // 正则匹配for (constauto &x : what) { // for匹配的子表达式cout << x << ',';}auto str = "god of war"s; // 待匹配的字符串auto reg = make_regex(R"((\w+)\s(\w+))"); // 原始字符串定义正则表达式auto what = make_match(); // 准备获取匹配的结果auto found = regex_search(str, what, reg); // 正则查找,和匹配类似assert(found); // 断言找到匹配assert(!what.empty()); // 断言有匹配结果assert(what[1] == "god"); // 看第一个子表达式assert(what[2] == "of"); // 看第二个子表达式auto new_str = regex_replace( // 正则替换,返回新字符串 str, // 原字符串不改动 make_regex(R"(\w+$)"), // 就地生成正则表达式对象"peace"// 需要指定替换的文字);cout << new_str << endl; // 输出god of peace
定义了两个简单的 lambda 表达式,生产正则对象,主要是为了方便用 auto 自动类型推导。当然,同时也隐藏了具体的类型信 息,将来可以随时变化(这也有点函数式编程的味道了)。
然后就可以调用 regex_match() 检查字符串,函数会返回 bool 值表示是否完全匹配正则。如果匹配成功,结果存储在 what 里,可以像容器那样去访问,第 0 号元素是整个匹配串,其他的是子表达式匹配串。
regex_search()、regex_replace() 的用法也都差不多。
这段代码的 regex_search() 搜索了两个连续的单词,然后在匹配结果里以数组下标的形式输出。
regex_replace() 不需要匹配结果,而是要提供一个替换字符串,因为算法是“只读”的,所以它会返回修改后的新字符串。利用这一点,就可以把它的输出作为另一个函数的输入,用“函数套函数”的形式实现“函数式编程”。
在使用 regex 的时候,还要注意正则表达式的成本。因为正则串只有在运行时才会处理,检查语法、编译成正则对象的代价很高,所以尽量不要反复创建正则对象,能重用就重用。在使用循环的时候更要特别注意,一定要把正则提到循环体外。
小结
C++20新增了char8_t,它相当于unsigned char,专门用来表示UTF-8编码,相应的也就有专门的字符串类u8 string和字面量前缀u8。
在string转换C字符串的时候,需要注意c_str()与data()的区别,两个函数都返回const char*指针,但c_str()会在末尾添加一个\0。
Boost程序库里有一个工具lexical_cast,可以在字符串和数字之间互转,功能比stoi()、to_string()更强大。
basic_regex、match_results针对char*、string 有不同的特化形式,但命名上却不太一致,有cmatch、smatch,却没有对应的cregex、sregex,我个人建议使用类型别名来保持对应关系,看起来更清楚。
除了标准库里的regex库,也可以选择其他的第三方正则表达式库,比如PCRE、Hyperscan、libsregex。
12 | 三分天下的容器:恰当选择,事半功倍
算法 + 数据结构 = 程序。
数据结构,就是数据在计算机里的存储和组织形式,比如堆、数组、链表、二叉树、B+ 树、哈希表,等等。
因为没有一种数据结构是万能的、可以应用于任何场景。毕竟,不同的数据结构存储数据的形式不一样,效率也就不一样。有的是连续存放,有的是分散存放,有的存储效率高,有的查找效率高,必须要依据具体的应用场合来进行取舍。
容器,其实就是 C++ 对数据结构的抽象和封装。
容器的通用特性
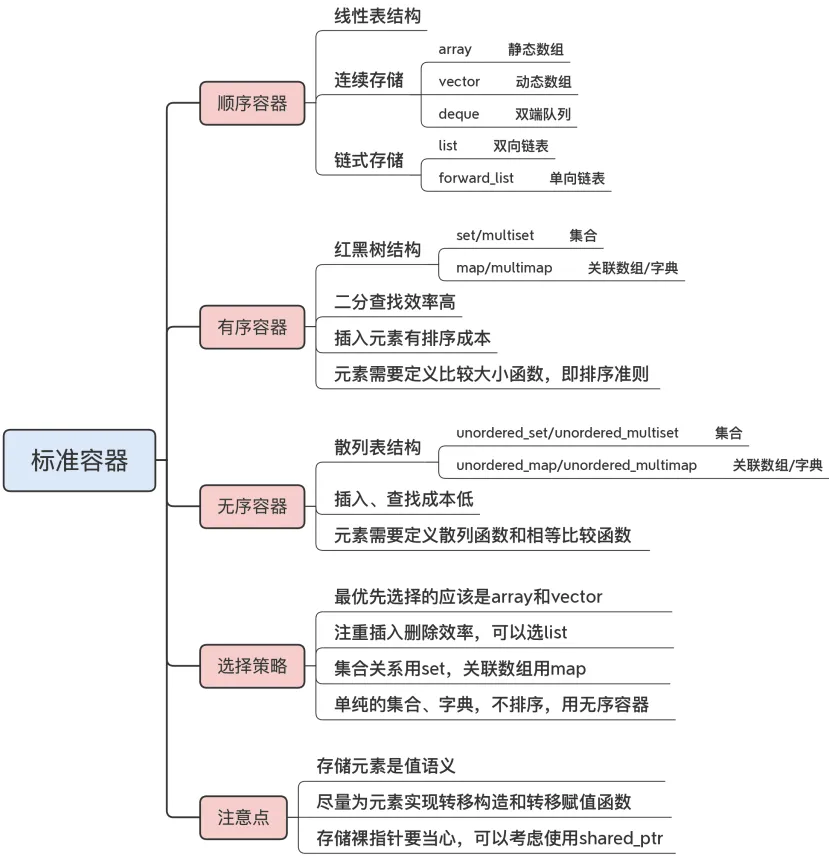
容器保存元素采用的 是“值”(value)语义,也就是说,容器里存储的是元素的拷贝、副 本,而不是引用。
容器操作元素的很大一块成本就是值的拷贝。所以,如果元素比较大,或者非常多,那么操作时的拷 贝开销就会很高,性能也就不会太好。
一个解决办法是,尽量为元素实现转移构造和转移赋值函数,在加入容器的时候使用 std::move() 来“转移”,减少元素复制的成本:
Point p; // 一个拷贝成本很高的对象v.push_back(p); // 存储对象,拷贝构造,成本很高v.push_back(std::move(p)); // 定义转移构造后就可以转移存储,降低成本
也可以使用 C++11 为容器新增加的 emplace 操作函数,它可以“就地”构造元素,免去了构造后再拷贝、转移的成本,不但高效,而且用起来也很方便:
v.emplace_back(...); // 直接在容器里构造元素,不需要拷贝或者转移
可能还会想到在容器里存放元素的指针,来间接保存元素,但作者不建议采用这种方案。
虽然指针的开销很低,但因为它是“间接”持有,就不能利用容器自动销毁元素的特性了,你必须要自己手动管理元素的生命周期,麻烦而且非常容易出错,有内存泄漏的隐患。
如果真的有这种需求,可以考虑使用智能指针unique_ptr/shared_ptr,让它们帮你自动管理元素。一般情况下,shared_ptr 是一个更好的选择,它的共享语义与容器的值语义基本一致。使用 unique_ptr 就要当心,它不能被拷贝,只能被转移,用起来就比较“微妙”。
容器的具体特性
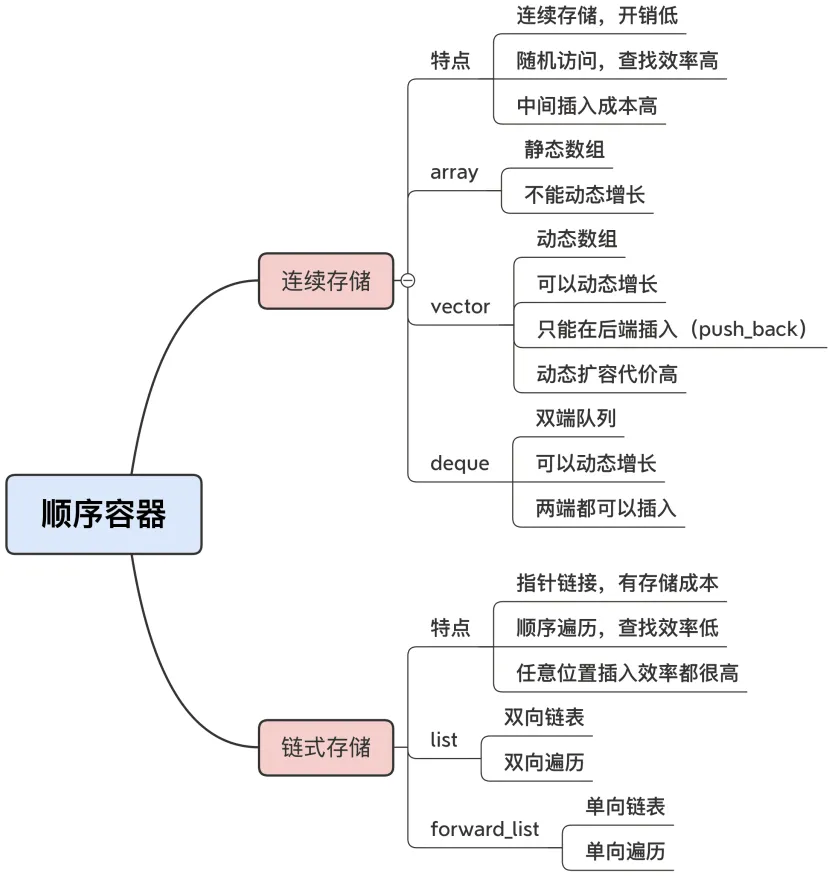
顺序容器
顺序容器就是数据结构里的线性表,一共有 5 种:array、vector、deque、list、forward_list。 按照存储结构,这 5 种容器又可以再细分成两组。
- 连续存储的数组:array、vector 和 deque。
- 指针结构的链表:list 和 forward_list。
array 和 vector 直接对应 C 的内置数组,内存布局与 C 完全兼容,所以是开销最低、速度最快的容器。
它们两个的区别在于容量能否动态增长:
- array 是静态数组,大小在初始化的时候就固定了,不能再容纳更多的元素。
- vector 是动态数组,虽然初始化的时候设定了大小,但可以在后面随需增长,容纳任意数量的元素。
array<int, 2> arr; // 初始一个array,长度是2assert(arr.size() == 2); // 静态数组的长度总是2vector<int> v(2); // 初始一个vector,长度是2for (int i = 0; i < 10; i++) { v.emplace_back(i); // 追加多个元素}assert(v.size() == 12); // 长度动态增长到12
deque 也是一种可以动态增长的数组,它和 vector 的区别是,它可以在两端高效地插入删除元素,这也是它的名字 double-end queue 的来历,而 vector 则只能用 push_back 在末端追加元素。
deque<int> d; // 初始化一个deque,长度是0d.emplace_back(9); // 末端添加一个元素d.emplace_front(1); // 前端添加一个元素assert(d.size() == 2); // 长度动态增长到2
vector 和 deque 里的元素因为是连续存储的,所以在中间的插入删除效率就很低,而 list 和 forward_list 是链表结构,插入删除操作只需要调整指针,所以在任意位置的操作都很高效。
链表的缺点是查找效率低,只能沿着指针顺序访问,这方面不如vector 随机访问的效率高。
forward_list,顾名思义,是单向链表,只能向前遍历,查找效率就更低了。
链表结构比起数组结构还有一个缺点,就是存储成本略高,因为必须要为每个元素附加一个或者两个的指针,指向链表的前后节点。
vector/deque 和 list/forward_list 都可以动态增长来容纳更多的元素,但它们的内部扩容机制却是不一样的。
当 vector 的容量到达上限的时候(capacity),它会再分配一块两倍大小的新内存,然后把旧元素拷贝或者移动过去。这个操作的成本是非常大的,所以,在使用 vector 的时候最好能够“预估”容量,使用reserve 提前分配足够的空间,减少动态扩容的拷贝代价。
vector 的做法太“激进”,而 deque、list 的的扩容策略就“保守”多了,只会按照固定的“步长”(例如 N 个字节、一个节点)去增加容量。但在短时间内插入大量数据的时候就会频繁分配内存,效果反而不如vector 一次分配来得好。
使用建议
如果没有什么特殊需求,首选的容器就是 array 和vector,它们的速度最快、开销最低,数组的形式也令它们最容易使用,搭配算法也可以实现快速的排序和查找。
剩下的 deque、list 和 forward_list 则适合对插入删除性能比较敏感的场合,如果还很在意空间开销,那就只能选择非链表的 deque 了。
有序容器
顺序容器的特点是,元素的次序是由它插入的次序而决定的,访问元素也就按照最初插入的顺序。
而有序容器则不同,它的元素在插入容器后就被按照某种规则自动排序,所以是“有序”的。
C++ 的有序容器使用的是树结构,通常是红黑树——有着最好查找性能的二叉树。
标准库里一共有四种有序容器:set/multiset 和 map/multimap。set 是集合,map 是关联数组(在其他语言里也叫“字典”)。
有 multi 前缀的容器表示可以容纳重复的 key,内部结构与无前缀的相同,所以也可以认为只有两种有序容器。
使用的关键就是要理解它的“有序”概念,也就是说,容器是如何判断两个元素的“先后次序”。
这就导致了有序容器与顺序容器的另一个根本区别,在定义容器的时候必须要指定 key 的比较函数。只不过这个函数通常是默认的 less,表示小于关系,不用特意写出来:
template <classT // 模板参数只有一个元素类型 > classvector;// vectortemplate <classKey, // 模板参数是key类型,即元素类型classCompare = std::less<Key> // 比较函数 > classset;// 集合template <classKey, // 第一个模板参数是key类型classT, // 第二个模板参数是元素类型classCompare = std::less<Key> // 比较函数 > classmap;// 关联数组
C++ 里的 int、string 等基本类型都支持比较排序,放进有序容器里毫无问题。
但很多自定义类型没有默认的比较函数,要作为容器的 key 就有点麻烦。有两种办法:一个是重载“<”,另一个是自定义模板参数。
// 1.重载 “<”booloperator<(const Point &a, const Point &b){return a.x < b.x; // 自定义比较运算}set<Point> s; // 现在就可以正确地放入有序容器s.emplace(7);s.emplace(3);// 2.自定义模板参数set<int> s = {7, 3, 9}; // 定义集合并初始化3个元素for (auto &x : s){ // 范围循环输出元素cout << x << ","; // 从小到大排序,3,7,9}auto comp = [](auto a, auto b) // 定义一个lambda,用来比较大小{return a > b; // 定义大于关系};set<int, decltype(comp)> gs(comp)// 使用decltype得到lambda的类型std::copy(begin(s), end(s), // 拷贝算法,拷贝数据 inserter(gs, gs.end())); // 使用插入迭代器for (auto &x : gs){ // 范围循环输出元素cout << x << ","; // 从大到小排序,9,7,3}
总之,集合关系就用 set,关联数组就用 map。
因为有序容器在插入的时候会自动排序,所以就有隐含的插入排序成本,当数据量很大的时候,内部的位置查找、树旋转成本可能会比较高。
如果需要实时插入排序,那么选择 set/map 是没问题的。如果是非实时,那么最好还是用 vector,全部数据插入完成后再一次性排序,效果肯定会更好。
无序容器
无序容器也有四种,名字里也有 set 和 map,只是加上了 unordered(无序)前缀,分别是 unordered_set/unordered_multiset、unordered_map/unordered_multimap。
无序容器同样也是集合和关联数组,用法上与有序容器几乎是一样的,区别在于内部数据结构:它不是红黑树,而是散列表(也叫哈希表,hash table)。
因为它采用散列表存储数据,元素的位置取决于计算的散列值,没有规律可言,所以就是“无序”的,你也可以把它理解为“乱序”容器。
using map_type = unordered_map<int, string>; // 类型别名, 使用无序关联数组map_type dict; // 定义一个无序关联数组dict[1] = "one"; // 添加三个元素dict.emplace(2, "two");dict[10] = "ten";for (auto &x : dict){ // 遍历输出cout << x.first << "=>"// 顺序不确定 << x.second << ","; // 既不是插入顺序,也不是大小序}
无序容器虽然不要求顺序,但是对 key 的要求反而比有序容器更“苛刻”一些,拿 unordered_map 的声明来看一下:
template <classKey, // 第一个模板参数是key类型classT, // 第二个模板参数是元素类型classHash = std::hash<Key>, // 计算散列值的函数对象classKeyEqual = std::equal_to<Key> // 相等比较函数 >classunordered_map;
它要求 key 具备两个条件,一是可以计算 hash 值,二是能够执行相等比较操作。第一个是因为散列表的要求,只有计算 hash 值才能放入散列表,第二个则是因为 hash 值可能会冲突,所以当 hash 值相同时,就要比较真正的 key 值。
与有序容器一样,要把自定义类型作为 key 放入无序容器,必须要实现这两个函数。
“==”函数比较简单,可以用与“<”函数类似的方式,通过重载操作符来实现:
booloperator==(const Point& a, const Point& b){return a.x == b.x; // 自定义相等比较运算}
散列函数就略麻烦一点,你可以用函数对象或者 lambda 表达式实现,内部最好调用标准的 std::hash 函数对象,而不要自己直接计算,否则很容易造成 hash 冲突:
auto hasher = [](constauto &p) // 定义一个lambda表达式{returnstd::hash<int>()(p.x); // 调用标准hash函数对象计算};unordered_set<Point, decltype(hasher)> s(10, hasher);s.emplace(7);s.emplace(3);
如果只想要单纯的集合、字典,没有排序 需求,就应该用无序容器,没有比较排序的成本,它的速度就会非常 快。
判断容器是否合适的基本依据是“不要有多余的操作”,不要为不需要的功能付出代价。比如,只在末尾添加元素,就不要用deque/list;只想快速查找元素,不用排序,就应该选unordered_set。
小结
标准容器可以分为三大类,即顺序容器、有序容器和无序容器;
所有容器中最优先选择的应该是 array 和 vector,它们的速度最快,开销最低;
list 是链表结构,插入删除的效率高,但查找效率低;
有序容器是红黑树结构,对 key 自动排序,查找效率高,但有插入成本;
无序容器是散列表结构,由 hash 值计算存储位置,查找和插入的成本都很低;
有序容器和无序容器都属于关联容器,元素有 key 的概念,操作元素实际上是在操作 key,所以要定义对 key 的比较函数或者散列函数。
多利用类型别名,而不要“写死”容器定义。因为容器的大部分接口是相同的,所以只要变动别名定义,就能够随意改换不同的容器,对于开发、测试都非常方便。
散列表理论上的时间复杂度是O(1),也就是常数,比红黑树的O(logN)要快。但要注意,**如果对元素里的大量数据计算hash,这个常数可能会很大,也许会超过O(logN)**。
有序容器和无序容器里有“等价”(equivalent)与“相等”(equality)的概念,“等价”的意思是!(x<y) &&!(x y),而“相等”的意思是“==”。“等价”基于次序关系,对象不一定相同,而“相等”是两个对象真正相同。
标准库里还有stack、queue、priority_queue三个“容器适配器”,它们并非真正的容器,而是由其他容器(通常是deque或vector)“适配”而实现的,使用接口上有变化,而内部结构相同。
13 | 五花八门的算法:不要再手写for循环了
算法 + 数据结构 = 程序
认识算法
算法就是一系列定义明确的操作步骤,并且会在有限次运算后得到结果。
计算机科学里有很多种算法,像排序算法、查找算法、遍历算法、加密算法,等等。
C++ 里的算法,指的是工作在容器上的一些泛型函数,会对容器内的元素实施的各种操作。
所有的算法本质上都是for 或者 while,通过循环遍历来逐个处理容器里的元素。
比如说 count 算法,它的功能非常简单,就是统计某个元素的出现次数,完全可以用 range-for 来实现同样的功能:
vector<int> v = {1, 3, 1, 7, 5}; // vector容器auto n1 = std::count( // count算法计算元素的数量 begin(v), end(v), 1// begin()、end()获取容器的范围);int n2 = 0;for (auto x : v) { // 手写for循环if (x == 1) { // 判断条件,然后统计 n2++; }}
算法应该是一种“境界”,追求更高层次上的抽象和封装,也是函数式编程的基本理念。
每个算法都有一个清晰、准确的命名,不需要额外的注释,让人一眼就可以知道操作的意图,而且,算法抽象和封装了反复出现的操作逻辑,也更有利于重用代码,减少手写的错误。
用算法加上 lambda 表达式,你就可以初步体验函数式编程的感觉(即函数套函数):
auto n = std::count_if( // count_if算法计算元素的数量 begin(v), end(v), // begin()、end()获取容器的范围 [](auto x) { // 定义一个lambda表达式return x > 2; // 判断条件 }); // 大函数里面套了三个小函数
认识迭代器(iterator)
C++ 里的迭代器也有很多种,比如输入迭代器、输出迭代器、双向迭代器、随机访问迭代器,等等。
可以把它简单地理解为另一种形式的“智能指针”,只是它强调的是对数据的访问,而不是生命周期管理。
容器一般都会提供 begin()、end() 成员函数,调用它们就可以得到表示两个端点的迭代器,具体类型最好用 auto 自动推导,不要过分关心:
vector<int> v = {1,2,3,4,5};// vector容器auto iter1 = v.begin(); // 成员函数获取迭代器,自动类型推导auto iter2 = v.end(); auto iter3 = std::begin(v); // 全局函数获取迭代器,自动类型推导auto iter4 = std::end(v);
迭代器和指针类似,也可以前进和后退,但你不能假设它一定支持“ ++ ”“ -- ”操作符,最好也要用函数来操作,常用的有这么几个:
next()/prev(),计算迭代器前后的某个位置。
array<int, 5> arr = {0,1,2,3,4};// array静态数组容器auto b = begin(arr);// 全局函数获取迭代器,首端auto e = end(arr);// 全局函数获取迭代器,末端 assert(distance(b, e) == 5); // 迭代器的距离auto p = next(b);// 获取“下一个”位置assert(distance(b, p) == 1);// 迭代器的距离assert(distance(p, b) == -1);// 反向计算迭代器的距离advance(p, 2);// 迭代器前进两个位置,指向元素'3'assert(*p == 3);assert(p == prev(e, 2));// 是末端迭代器的前两个位置
最有用的算法
手写循环的替代品首先,我带你来认识一个最基本的算法 for_each,它是手写for 循环的真正替代品。
for_each 在逻辑和形式上与 for 循环几乎完全相同:
vector<int> v = {3, 5, 1, 7, 10}; // vector容器for (constauto &x : v) { // range for循环cout << x << ",";}auto print = [](constauto &x) // 定义一个lambda表达式{ cout << x << ","; };for_each(cbegin(v), cend(v), print); // for_each算法for_each( // for_each算法,内部定义lambda表达式 cbegin(v), cend(v), // 获取常量迭代器 [](constauto &x) // 匿名lambda表达式 { cout << x << ","; });
for_each 算法的价值就体现在这里,它把要做的事情分成了两部分,也就是两个函数:一个遍历容器元素,另一个操纵容器元素,而且名 字的含义更明确,代码也有更好的封装。
它能够促使我们更多地以“函数式编程”来思考,使用lambda 来封装逻辑,得到更干净、更安全的代码。
排序算法
说到排序,你脑海里跳出的第一个词可能就是 sort(),它是经典的快排算法,通常用它准没错。
auto print = [](constauto &x) // lambda表达式输出元素{ cout << x << ","; };std::sort(begin(v), end(v)); // 快速排序for_each(cbegin(v), cend(v), print); // for_each算法
sort() 虽然快,但它是不稳定的,而且是全排所有元素。
很多时候,这样做的成本比较高,比如 TopN、中位数、最大最小值等,我们只关心一部分数据,如果你用 sort(),就相当于“杀鸡用牛刀”,是一种浪费。
C++ 为此准备了多种不同的算法,名字不全叫 sort:
要求排序后仍然保持元素的相对顺序,应该用 stable_sort,它是稳定的;
选出前几名(TopN),应该用 partial_sort;
选出前几名,但不要求再排出名次(BestN),应该用nth_element;
中位数(Median)、百分位数(Percentile),还是用nth_element;
按照某种规则把元素划分成两组,用 partition;
第一名和最后一名,用 minmax_element。
下面的代码使用 vector 容器示范了这些算法,注意它们“函数套函数”的形式:
// top3std::partial_sort(begin(v), next(begin(v), 3), end(v)); // 取前3名// best3std::nth_element(begin(v), next(begin(v), 3), end(v)); // 最好的3个// Medianauto mid_iter = // 中位数的位置 next(begin(v), v.size() / 2);std::nth_element(begin(v), mid_iter, end(v)); //排序得到中位数cout << "median is " << *mid_iter << endl;// partitionauto pos = std::partition( // 找出所有大于9的数 begin(v), end(v), [](constauto &x) // 定义一个lambda表达式 { return x > 9; });for_each(begin(v), pos, print); // 输出分组后的数据// min/maxauto value = std::minmax_element( //找出第一名和倒数第一 cbegin(v), cend(v));
在使用这些排序算法时,还要注意一点,它们对迭代器要求比较高,通常都是随机访问迭代器(minmax_element 除外),所以最好在顺序容器 array/vector 上调用。
- 如果是 list 容器,应该调用成员函数 sort(),它对链表结构做了特别的优化。
- 有序容器 set/map 本身就已经排好序了,直接对迭代器做运算就可以得到结果。
- 而对无序容器,则不要调用排序算法,原因你应该不难想到(散列表结构的特殊性质,导致迭代器不满足要求、元素无法交换位置)。
查找算法
排序算法的目标是让元素有序,这样就可以快速查找,节约时间。
算法 binary_search,就是在已经排好序的区间里执行二分查找。但糟糕的是,它只返回一个 bool 值,告知元素是否存在,而更多的时候,我们是想定位到那个元素,所以 binary_search 几乎没什么用。
vector<int> v = {3, 5, 1, 7, 10, 99, 42}; // vector容器std::sort(begin(v), end(v)); // 快速排序auto found = binary_search( // 二分查找,只能确定元素在不在 cbegin(v), cend(v), 7);
想要在已序容器上执行二分查找,要用到一个名字比较怪的算法:lower_bound,它返回第一个“大于或等于”值的位置:
decltype(cend(v)) pos; // 声明一个迭代器,使用decltypepos = std::lower_bound( // 找到第一个>=7的位置 cbegin(v), cend(v), 7);found = (pos != cend(v)) && (*pos == 7); // 可能找不到,所以必须要判断assert(found); // 7在容器里pos = std::lower_bound( // 找到第一个>=9的位置 cbegin(v), cend(v), 9);found = (pos != cend(v)) && (*pos == 9); // 可能找不到,所以必须要判断assert(!found); // 9不在容器里
lower_bound 的返回值是一个迭代器,所以就要做一点判断工作,才能知道是否真的找到了。判断的条件有两个,一个是迭代器是否有效,另一个是迭代器的值是不是要找的值。
注意 lower_bound 的查找条件是“大于等于”,而不是“等于”,所以它的真正含义是“大于等于值的第一个位置”。相应的也就有“大于等于值的最后一个位置”,算法叫 upper_bound,返回的是第一个“大于”值的元素。
pos = std::upper_bound( // 找到第一个>9的位置 cbegin(v), cend(v), 9);
它俩的返回值构成一个区间,这个区间往前就是所有比被查找值小的元素,往后就是所有比被查找值大的元素,可以写成一个简单的不等式:
$$begin < x <= lower\_bound < upper\_bound < end $$在刚才的这个例子里,对数字 9 执行 lower_bound 和upper_bound,就会返回$[10,10]$这样的区间。
对于有序容器 set/map,就不需要调用这三个算法了,它们有等价的成员函数 find/lower_bound/upper_bound,效果是一样的。
要注意 find 与 binary_search 不同,它的返回值不是 bool 而是迭代器,可以参考下面的示例代码:
multiset<int> s = {3, 5, 1, 7, 7, 7, 10, 99, 42}; // multiset,允许重复auto pos = s.find(7); // 二分查找,返回迭代器assert(pos != s.end()); // 与end()比较才能知道是否找到auto lower_pos = s.lower_bound(7); // 获取区间的左端点auto upper_pos = s.upper_bound(7); // 获取区间的右端点for_each( // for_each算法 lower_pos, upper_pos, print // 输出7,7,7);
除了 binary_search、lower_bound 和 upper_bound,标准库里还有一些查找算法可以用于未排序的容器,虽然肯定没有排序后的二分查找速度快,但也正因为不需要排序,所以适应范围更广。
这些算法以 find 和 search 命名,不过可能是当时制定标准时的疏忽,名称有点混乱,其中用于查找区间的 find_first_of/find_end,或许更应该叫作 search_first/search_last。
vector<int> v = {1, 9, 11, 3, 5, 7}; // vector容器decltype(v.end()) pos; // 声明一个迭代器,使用decltypepos = std::find( // 查找算法,找到第一个出现的位置 begin(v), end(v), 3);assert(pos != end(v)); // 与end()比较才能知道是否找到pos = std::find_if( // 查找算法,用lambda判断条件 begin(v), end(v), [](auto x) { // 定义一个lambda表达式return x % 2 == 0; // 判断是否偶数 });assert(pos == end(v)); // 与end()比较才能知道是否找到array<int, 2> arr = {3, 5}; // array容器pos = std::find_first_of( // 查找一个子区间 begin(v), end(v), begin(arr), end(arr));assert(pos != end(v)); // 与end()比较才能知道是否找到
C++ 里的算法像是一个大宝库,非常值得你去发掘。比如类似 memcpy 的 copy/move 算法(搭配插入迭代器)、检查元素的all_of/any_of 算法,用好了都可以替代很多手写 for 循环。
小结
- 算法是专门操作容器的函数,是一种“智能 for 循环”,它的最佳搭档是 lambda 表达式;
- 算法通过迭代器来间接操作容器,使用两个端点指定操作范围,迭代器决定了算法的能力;
- for_each 算法是 for 的替代品,以函数式编程替代了面向过程编程;
- 有多种排序算法,最基本的是 sort,但应该根据实际情况选择其他更合适的算法,避免浪费;
- 在已序容器上可以执行二分查找,应该使用的算法是lower_bound;
- list/set/map 提供了等价的排序、查找函数,更适应自己的数据结构;
- find/search 是通用的查找算法,效率不高,但不必排序也能使用。
- 因为标准算法的名字实在是太普通、太常见了,所以建议一定要显式写出“
std::”名字空间限定,这样看起来更加醒目,也避免了无意的名字冲突。 - 容器通常还提供成员函数
rbegin()/rend(),用于逆序迭代(reverse),相应的也有全局函数rbegin()/rend()、crbegin()/crend()。 - for_each算法还有一个不同于for循环的地方,它可以返回传入的函数对象。但因为lambda表达式只能被调用,没有状 态,所以搭配lambda表达式的时候,for_each算法的返回值就没有意义。
equal_range算法可以一次性获得[lower_bound,upper_bound]这个区间,节约一次函数调用。- C++17允许算法并行处理,需要传递
std:execution::par等策略参数,提升运行效率。 - C++20引入了range的概念,在名字空间
std:ranges提供基于范围操作的算法,可以不必显式写出begin()、end()。而且它还重载了“”,实现简洁的“管道”操作。
14 | 十面埋伏的并发:多线程真的很难吗?
并发有很多种实现方式,而多线程只是其中最常用的一种手段。不过,因为多线程已经有了很多年的实际应用,也有很多研究成果、应用模式和成熟的软硬件支持,所以,对这两者的区分一般也不太严格。
认识线程和多线程
在 C++ 语言里,线程就是一个能够独立运行的函数。
auto f = []() // 定义一个lambda表达式{ cout << "tid=" << this_thread::get_id() << endl; };thread t(f); // 启动一个线程,运行函数f
任何程序一开始就有一个主线程,它从 main() 开始运行。主线程可以调用接口函数,创建出子线程。子线程会立即脱离主线程的控制流程,单独运行,但共享主线程的数据。程序创建出多个子线程,执行多个不同的函数,也就成了多线程。
多线程的好处有很多,比如任务并行、避免 I/O 阻塞、充分利用 CPU、提高用户界面响应速度,等等。
“读而不写”就不会有数据竞争。
所以,在 C++ 多线程编程里读取 const 变量总是安全的,对类调用const 成员函数、对容器调用只读算法也总是线程安全的。有时候不安全,因为一个线程读取的时候,另一个线程写入了或者修改了,这就是读的时候写了。
最好的并发就是没有并发,最好的多线程就是没有线程。
在大的、宏观的层面上“看得到”并发和线程,而在小的、微观的层面上“看不到”线程,减少死锁、同步等恶性问题的出现几率。
多线程开发实践
在 C++ 里,有四个基本的工具:仅调用一次、线程局部存储、原子变量和线程对象。
仅调用一次
程序免不了要初始化数据,这在多线程里却是一个不大不小的麻烦。因为线程并发,如果没有某种同步手段来控制,会导致初始化函数多次运行。
C++ 提供了“仅调用一次”的功能,要先声明一个 once_flag 类型的变量,最好是静态、全局的(线程可见),作为初始化的标志:
staticstd::once_flag flag; // 全局的初始化标志
然后调用专门的 call_once() 函数,以函数式编程的方式,传递这个标志和初始化函数。这样 C++ 就会保证,即使多个线程重入call_once(),也只能有一个线程会成功运行初始化。
staticstd::once_flag flag; // 定义一个once_flagauto f = []() // 在线程里运行的lambda表达式 {std::cout << "tid : " << std::this_thread::get_id() << std::endl;std::call_once(flag, // 仅一次调用,注意要传flag []() {// 匿名lambda,初始化函数,只会执行一次std::cout << "only once" << std::endl; } // 匿名lambda结束 );// 在线程里运行的lambda表达式结束 };std::thread t6(f);std::thread t7(f); t6.join(); t7.join();
运行结果:
tid : 140476359517952only oncetid : 140476351125248
call_once() 完全消除了初始化时的并发冲突,在它的调用位置根本看不到并发和线程。所以,按照刚才说的基本原则,它是一个很好的多线程工具。
它也可以很轻松地解决多线程领域里令人头疼的“双重检查锁定”问题,你可以自己试一试,用它替代锁定来初始化。
单例模式
根据call_once()这个特性,特别适用于生成单例模式
classSingleton {private:// 1. 私有构造函数:禁止外部直接创建实例 Singleton() {std::cout << "Singleton 实例初始化(仅执行一次)" << std::endl;// 这里可以放单例的初始化逻辑(如初始化资源、连接设备等) }// 2. 私有析构函数:可选,确保资源正确释放 ~Singleton() { std::cout << "Singleton 实例析构" << std::endl; }// 关键:给 std::default_delete<Singleton> 授权,允许它访问析构函数friendclassstd::default_delete<Singleton>;// 3. 禁用拷贝和赋值:避免单例被复制 Singleton(const Singleton &) = delete; Singleton &operator=(const Singleton &) = delete;// 4. 静态成员:once_flag(确保初始化仅一次) + 实例指针staticstd::once_flag init_flag_;staticstd::unique_ptr<Singleton> instance_; // 用智能指针管理,自动析构public:// 5. 公共接口:获取单例实例(线程安全)static Singleton &GetInstance(){// 关键:多个线程调用时,仅一个线程执行初始化逻辑std::call_once(init_flag_, []() {// 匿名 lambda:初始化单例实例(仅执行一次) instance_ = std::unique_ptr<Singleton>(new Singleton()); });// 返回实例引用(确保外部只能通过 GetInstance() 访问)return *instance_; }// 示例:单例的业务接口voidDoSomething(){std::cout << "Singleton 执行业务逻辑,线程ID:" << std::this_thread::get_id() << std::endl; }};
测试代码:
// 6. 静态成员初始化(必须在类外定义)std::once_flag Singleton::init_flag_;std::unique_ptr<Singleton> Singleton::instance_ = nullptr;// 测试:多线程调用单例voidTestSingleton(){std::cout << "线程 " << std::this_thread::get_id() << " 尝试获取单例" << std::endl; Singleton &instance = Singleton::GetInstance(); instance.DoSomething();}intmain(int argc, char *argv[]){// 创建 5 个线程,同时调用单例std::thread t1(TestSingleton);std::thread t2(TestSingleton);std::thread t3(TestSingleton);std::thread t4(TestSingleton);std::thread t5(TestSingleton); t1.join(); t2.join(); t3.join(); t4.join(); t5.join();return0;}
运行结果:
线程 140076927121152 尝试获取单例Singleton 实例初始化(仅执行一次)线程 140076918728448 尝试获取单例Singleton 执行业务逻辑,线程ID:140076918728448Singleton 执行业务逻辑,线程ID:140076927121152线程 140076910335744 尝试获取单例Singleton 执行业务逻辑,线程ID:140076910335744线程 140076901943040 尝试获取单例Singleton 执行业务逻辑,线程ID:140076901943040线程 140076893550336 尝试获取单例Singleton 执行业务逻辑,线程ID:140076893550336Singleton 实例析构
线程局部存储
读写全局(或者局部静态)变量是另一个比较常见的数据竞争场景,因为共享数据,多线程操作时就有可能导致状态不一致。
全局变量并不一定是必须共享的,可能仅仅是为了方便线程传入传出数据,或者是本地cache,而不是为了共享所有权。
这应该是线程独占所有权,不应该在多线程之间共同拥有,术语叫“线程局部存储”(thread local storage)。
这个功能在 C++ 里由关键字 thread_local 实现,它是一个和 static、extern 同级的变量存储说明,有 thread_local 标记的变量在每个线程里都会有一个独立的副本,是“线程独占”的,所以就不会有竞争读写的问题。**
下面是示范 thread_local 的代码,先定义了一个线程独占变量,然后用 lambda 表达式捕获引用,再放进多个线程里运行:
thread_localint n4 = 3; // 线程局部存储变量auto f4 = [&](int x) // 在线程里运行的lambda表达式,捕获引用 { n4 += x; // 使用线程局部变量,互不影响std::cout << n4 << std::endl; // 输出,验证结果 };std::thread t12(f4, 10); // 启动两个线程,运行函数fstd::thread t13(f4, 20); t12.join(); t13.join();
运行结果:
1323
试着把变量的声明改成 static,再运行一下。这时,因为两个线程共享变量,所以 n 就被连加了两次,最后的结果就是 33。
和 call_once() 一样,thread_local 也很容易使用。但它的应用场合不是那么显而易见的,这要求对线程的共享数据有清楚的认识,区分出独占的那部分,消除多线程对变量的并发访问。
原子变量
要想保证多线程读写共享数据的一致性,关键是要解决同步问题,不能让两个线程同时写,也就是“互斥”。
这在多线程编程里早就有解决方案了,就是互斥量(Mutex)。但它的成本太高,所以,对于小数据,应该采用“原子化”这个更好的方案。
所谓原子(atomic),在多线程领域里的意思就是不可分的。操作要么完成,要么未完成,不能被任何外部操作打断,总是有一个确定的、完整的状态。所以也就不会存在竞争读写的问题,不需要使用互斥量来同步,成本也就更低。
但不是所有的操作都可以原子化的,否则多线程编程就太轻松了。目前,C++ 只能让一些最基本的类型原子化,比如 atomic_int、atomic_long,等等:
usingatomic_bool = std::atomic<bool>; // 原子化的boolusingatomic_int = std::atomic<int>;// 原子化的intusingatomic_long = std::atomic<long>; // 原子化的long
这些原子变量都是模板类 atomic 的特化形式,包装了原始的类型,具有相同的接口,用起来和 bool、int 几乎一模一样,但却是原子化的,多线程读写不会出错。
注意,“几乎”这个词,它还是有些不同的,一个重要的区别是,原子变量禁用了拷贝构造函数,所以在初始化的时候不能用“=”的赋值形式,只能用圆括号或者花括号:
atomic_int x {0}; // 初始化,不能用=atomic_long y {1000L}; // 初始化,只能用圆括号或者花括号 assert(++x == 1); // 自增运算y += 200; // 加法运算assert(y < 2000); // 比较运算
除了模拟整数运算,原子变量还有一些特殊的原子操作,比如 store、load、fetch_add、fetch_sub、exchange、compare_exchange_weak/compare_exchange_strong,最后一组就是著名的 CAS(Compare And Swap)操作。
而另一个同样著名的 TAS(Test And Set)操作,则需要用到一个特殊的原子类型 atomic_flag。
它不是简单的 bool 特化(atomic),没有 store、load 的操作,只用来实现 TAS,保证绝对无锁。
原子变量用法
最基本的用法是把原子变量当作线程安全的全局计数器或者标志位,这也算是“初心”吧。但它还有一个更重要的应用领域,就是实现高效的无锁数据结构(lock-free)。
作者强烈不建议自己尝试去写无锁数据结构,因为无锁编程的难度比使用互斥量更高,可能会掉到各种难以察觉的“坑”(例如 ABA)里,最好还是用现成的库。可以考虑boost.lock_free。
线程
call_once、thread_local 和 atomic 这三个 C++ 里的工具,它们都不与线程直接相关,但却能够用于多线程编程,尽量消除显式地使用线程。
C++ 标准库里有专门的线程类 thread,使用它就可以简单地创建线程,在名字空间 std::this_thread 里,还有 yield()、get_id()、sleep_for()、sleep_until() 等几个方便的管理函数。
staticstd::atomic_flag flag1{false}; // 原子化的标志量staticatomic_int n1{0}; // 原子化的intauto f2 = [&]() // 在线程里运行的lambda表达式,捕获引用 {auto value = flag1.test_and_set(); // TAS检查原子标志量if (value) {std::cout << "flag has been set." << std::endl; } else {std::cout << "set flag by " << std::this_thread::get_id() << std::endl; // 输出线程id } n1 += 100; // 原子变量加法运算std::this_thread::sleep_for(std::chrono::milliseconds(n1.load() * 10)); // 线程睡眠, 使用时间字面量std::cout << n1 << std::endl; }; // 在线程里运行的lambda表达式结束std::thread t10(f2);std::thread t11(f2); // 启动两个线程,运行函数f t10.join(); t11.join();
结果:
set flag by 139816908142336flag has been set.200200
建议不要直接使用 thread 这个“原始”的线程概念,最好把它隐藏到底层,因为“看不到的线程才是好线程”。
具体的做法是调用函数 async(),它的含义是“异步运行”一个任务,隐含的动作是启动一个线程去执行,但不绝对保证立即启动(也可以在第一个参数传递 std::launch::async,要求立即启动线程)。
大多数 thread 能做的事情也可以用 async() 来实现,但不会看到明显的线程:
auto task = [](auto x) // 在线程里运行的lambda表达式 { std::this_thread::sleep_for(std::chrono::milliseconds(x * 1)); // 线程睡眠 std::cout << "sleep for " << x << std::endl;return x; }; auto f3 = std::async(task, 1000); // 启动一个异步任务 std::cout << "test 1 " << std::endl; std::cout << "test 2 " << std::endl; std::cout << "test 3 " << std::endl; assert(f3.valid()); // 确实已经完成了任务 f3.wait(); // 等待任务完成 std::cout << "test 4 " << std::endl; std::cout << "test 5 " << std::endl; assert(f3.valid()); // 确实已经完成了任务 std::cout << "async task result: " << f3.get() << std::endl; // 获取任务的执行结果
运行结果:
test 1 test 2 test 3 sleep for 1000test 4 test 5 async task result: 1000
这还是函数式编程的思路,在更高的抽象级别上去看待问题,异步并发多个任务,让底层去自动管理线程,要比我们自己手动控制更好(比如内部使用线程池或者其他机制)。
async() 会返回一个 future 变量,可以认为是代表了执行结果的“期货”,如果任务有返回值,就可以用成员函数 get() 获取。
不过要特别注意,get()只能调一次,再次获取结果会发生错误,抛出异常std::future_error。
另外,这里还有一个很隐蔽的“坑”,如果不显式获取 async() 的返回值(即 future 对象),它就会同步阻塞直至任务完成(由于临时对象 的析构函数),于是“async”就变成了“sync”。
所以,即使我们不关心返回值,也总要用 auto 来配合 async(),避免同步阻塞,就像下面的示例代码那样:
std::async(task, ...); // 没有显式获取future,被同步阻塞auto f = std::async(task, ...);// 只有上一个任务完成后才能被执行
void heavy_task() { std::cout << "任务线程开始执行..." << std::endl; std::this_thread::sleep_for(std::chrono::seconds(3)); // 模拟耗时3秒的任务 std::cout << "任务线程执行完成!" << std::endl;}int main() { std::cout << "主线程开始" << std::endl; // ❌ 致命错误:不接收std::async的返回值(future对象) std::async(std::launch::async, heavy_task); std::cout << "主线程继续执行(本应立刻打印,实际会阻塞3秒)" << std::endl;return 0;}
上面代码因为没有接收 std::async的返回值,导致阻塞主线程执行,程序运行结果:
主线程开始任务线程开始执行...任务线程执行完成!主线程继续执行(本应立刻打印,实际会阻塞3秒)
小结
- 多线程是并发最常用的实现方式,好处是任务并行、避免阻塞,坏处是开发难度高,有数据竞争、死锁等很多“坑”;
- call_once() 实现了仅调用一次的功能,避免多线程初始化时的冲突;
- thread_local 实现了线程局部存储,让每个线程都独立访问数据,互不干扰;
- atomic 实现了原子化变量,可以用作线程安全的计数器,也可以实现无锁数据结构;
- async() 启动一个异步任务,相当于开了一个线程,但内部通常会有优化,比直接使用线程更好。
- C++20 正式加入了协程(关键字
co_wait/co_yield/co_return)。它是用户态的线程,没有系统级线程那么多的麻烦事,使用它就可以写出开销更低、性能更高的并发程序。 - 在C语言(C11,不是ANSI C)里也有“
thread_local'”的功能,但它只是一个宏,GCC也有自己的“_thread”关键字。 - 如果只是想简单地在线程里启动一个异步任务,完全不关心返回值,可以调用thread的成员函数
detach(),比sync()会方便一点。 - tbb (Threading Building Blocks) 是Intel开发的一个多线程库,提供线程安全的容器、并行算法等一些有用的工具。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
