《C++实战笔记-罗剑锋》学习笔记2
- 06 | auto/decltype:为什么要有自动类型推导?
- 自动类型推导(auto type deduction)
- 07 | const/volatile/mutable:常量/变量究竟是怎么回事?
- 08 | smart_ptr:智能指针到底“智能”在哪里?
06 | auto/decltype:为什么要有自动类型推导?
自动类型推导(auto type deduction)
虽然可以用 typedef 或者 using 来简化类型名,部分减轻打字的负担,但关键的“手动推导”问题还是没有得到解决,还是要去翻看类型定义,找到正确的声明。
关键字 auto,在代码里的作用像是个“占位符”(placeholder)。写上它,你就可以让编译器去自动“填上”正确的类型。
auto i = 0; // 自动推导为int类型auto x = 1.0; // 自动推导为double类型auto str = "hello"; // 自动推导为const char [6]类型std::map<int, std::string> m = {{1, "a"}, {2, "b"}}; // 自动推导不出来auto iter = m.begin(); // 自动推导为map内部的迭代器类型auto f = bind1st(std::less<int>(), 2); // 自动推导出类型,具体是啥不知道
除了简化代码,auto 还避免了对类型的“硬编码”,也就是说变量类型不是“写死”的,而是能够“自动”适应表达式的类型。比如,你把 map改为 unordered_map,那么后面的代码都不用动。
auto 的“自动推导”能力只能用在“初始化”的场合。
具体来说,就是赋值初始化或者花括号初始化(初始化列表、Initializer list),变量右边必须要有一个表达式(简单、复杂都可以)。这样你才能在左边放上 auto,编译器才能找到表达式,帮你自动计算类型。
如果不是初始化的形式,只是“纯”变量声明,那就无法使用 auto。
类成员变量初始化的时候,目前的 C++ 标准不允许使用 auto 推导类型。
auto x = 0L; // 自动推导为longauto y = &x; // 自动推导为long*auto z {&x}; // 自动推导为long*auto err; // 错误,没有赋值表达式,不知道是什么类型
总结起来就是:
- auto 总是推导出“值类型”,绝不会是“引用”;
- auto 可以附加上
const、volatile、*、& 这样的类型修饰符,得到新的类型。 - C++标准又特别规定,类的静态成员变量允许使用auto自动推导类型,但我建议,为了与非静态成员保持一致,还是统一不使用auto比较好。
- C++14新增了字面量后缀“s”,表示标准字符串,所以就可以用“
auto str="xXx"s;”的形式直接推导出std:string类型。
decltype
decltype 也是自动类型推导。
decltype 的形式很像函数,后面的圆括号里就是可用于计算类型的表达式(和 sizeof 有点类似),其他方面就和 auto 一样了,也能加上const、*、& 来修饰。
除了加上 * 和 & 修饰,decltype 还可以直接从一个引用类型的变量推导出引用类型,而 auto 就会把引用去掉,推导出值类型。
int x = 0; // 整型变量decltype(x) x1; // 推导为int,x1是intdecltype(x) &x2 = x; // 推导为int,x2是int&,引用必须赋值decltype(x) *x3; // 推导为int,x3是int*decltype(&x) x4; // 推导为int*,x4是int*decltype(&x) *x5; // 推导为int*,x5是int**decltype(x2) x6 = x2; // 推导为int&,x6是int&using int_ptr = decltype(&x); // int *using int_ref = decltype(x)&; // int &
decltype 不仅能够推导出值类型,还能够推导出引用类型,也就是表达式的“原始类型”。
完全可以把 decltype 看成是一个真正的类型名,用在变量声明、函数参数 / 返回值、模板参数等任何类型能出现的地方,只不过这个类型是在编译阶段通过表达式“计算”得到的。
C++14 就又增加了一个“decltype(auto)”的形式,既可以精确推导类型,又能像 auto 一样方便使用。
int x = 0; // 整型变量decltype(auto) x1 = (x); // 推导为int&,因为 (expr)是引用类型decltype(auto) x2 = &x; // 推导为int*decltype(auto) x3 = x1; // 推导为int&
使用 auto/decltype
auto 还有一个“最佳实践”,就是“range-based for”,不需要关心容器元素类型、迭代器返回值和首末位置,就能非常轻松地完成遍历操作。不过,为了保证效率,最好使用“const auto&”或者“auto&”。
vector<int> v = {2, 3, 5, 7, 11}; // vector顺序容器for (constauto &i : v) { // 常引用方式访问元素,避免拷贝代价cout << i << ","; // 常引用不会改变元素的值}for (auto &i : v) { // 引用方式访问元素 i++; // 可以改变元素的值cout << i << ",";}
在 C++14 里,auto 还新增了一个应用场合,就是能够推导函数返回值,这样在写复杂函数的时候,比如返回一个 pair、容器或者迭代 器,就会很省事。
autoget_a_set(){ // auto作为函数返回值的占位符std::set<int> s = {1, 2, 3};return s;}
decltype 是 auto 的高级形式,更侧重于编译阶段的类型计算,所以常用在泛型编程里,获取各种类型,配合 typedef 或者 using 会更加方便。当你感觉“这里我需要一个特殊类型”的时候,选它就对了。
比如定义函数指针的时候,就可以用decltype
// UNIX信号函数的原型,看着就让人晕,你能手写出函数指针吗?void (*signal(int signo, void (*func)(int)))(int);// 使用decltype可以轻松得到函数指针类型usingsig_func_ptr_t = decltype(&signal);
在定义类的时候,因为 auto 被禁用了,就可以使用 decltype 。它可以搭配别名任意定义类型,再应用到成员变量、成 员函数上,变通地实现 auto 的功能。
classDemoClassfinal {public:using set_type = std::set<int>; // 集合类型别名private: set_type m_set; // 使用别名定义成员变量// 使用decltype计算表达式的类型,定义别名using iter_type = decltype(m_set.begin()); iter_type m_pos; // 类型别名定义成员变量};
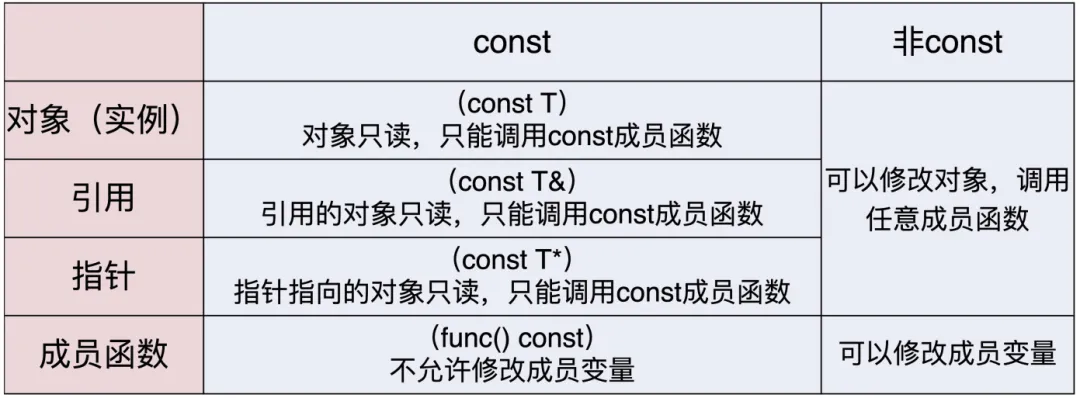
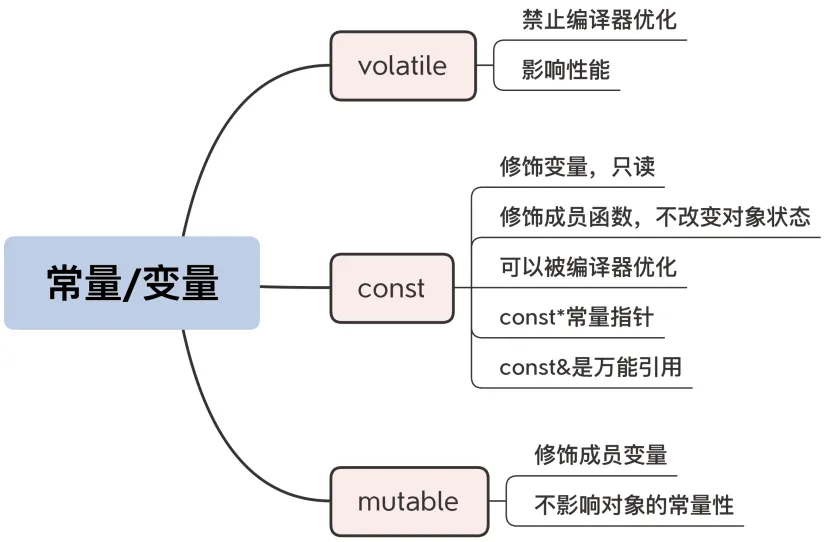
07 | const/volatile/mutable:常量/变量究竟是怎么回事?
const
表示“常量”,定义程序用到的数字、字符串常量,代替宏定义。
const 定义的常量在预处理阶段并不存在,而是直到运行阶段才会出现。它实际上是运行时的“变量”,只不过不允许修改,是“只读”的(read only)(虽然是“只读”,但在运行阶段没有什么是不可以改变的,也可以强制写入),把变量标记成 const 可以让编译器做更好的优化。。
编译器看到 const 定义,就会采取一些优化手段,比如把所有 const 常量出现的地方都替换成原始值。
常量引用和常量指针
int x = 100;constint &rx = x;constint *px = &x;
const & 被称为万能引用,可以引用任何类型,即不管是值、指针、左引用还是右引用,它都能“照单全收”。而且,它还会给变量附加上 const 特性,这样“变量”就成了“常量”,只能读、禁止写。编译器会帮你检查出所有对它的写操作,发出警告,在编译阶段防止有意或者无意的修改。这样一来,const 常量用起来就非常安全了。因此,在设计函数的时候,尽可能地使用它作为入口参数,一来保证效率,二来保证安全。
const 放在声明的最左边,表示指向常量的指针。指针指向的是一个“只读变量”,不允许修改:
string name = "uncharted";conststring *ps1 = &name; // 指向常量*ps1 = "spiderman"; // 错误,不允许修改
const 在“*”的右边,表示指针不能被修改,而指向的变量可以被修改:
string *const ps2 = &name; // 指向变量,但指针本身不能被修改*ps2 = "spiderman"; // 正确,指针指向的值允许修改
“*”两边都有 const,既不能修改指针,也不能修改指针指向的变量:
conststring* const ps3 = &name; // 很难看懂
实话实说,我对 const 在“*”后面的用法“深恶痛绝”,每次看到这种形式,脑子里都会“绕一下”,实在是太难理解了,似乎感觉到了代码作者“深深的恶意”。
还是那句名言:“代码是给人看的,而不是给机器看的。”
所以,我从来不用“* const”的形式,也建议你最好不要用,而且这种形式在实际开发时也确实没有多大作用(除非你想“炫技”)。如果真有必要,也最好换成其他实现方式,让代码好懂一点,将来的代码维护者会感谢你的。
作者简直说出了程序员的心声。
定义 const 成员变量
classDemoClassfinal {private:constlong MAX_SIZE = 256; // const成员变量int m_value; // 成员变量public:intget_value()const// const成员函数{return m_value; }};
const 被放在了函数的后面,表示这个函数是一个“常量”,函数内部不会修改变量值。(如果在前面,就代表返回值是 const int)
“const 成员函数”的意思并不是说函数不可修改。实际上,在 C++里,函数并不是变量(lambda 表达式除外),所以,“只读”对于函数来说没有任何意义。它的真正含义是:函数的执行过程是 const 的,不会修改对象的状态(即成员变量),也就是说,成员函数是一个“只读操作”。
标准库中,比如 vector,它的 empty()、size()、capacity() 等查看基本属性的操作都是 const 的,而reserve()、clear()、erase() 则是非 const 的。
volatile
含义是“不稳定的”“易变的”,在 C++ 里,表示变量的值可能会以“难以察觉”的方式被修改(比如操作系统信号、外界其他的代码),所以要禁止编译器做任何形式的优化,每次使用的时候都必须“老老实实”地去取值。
// 需要加上volatile修饰,运行时才能看到效果constvolatileint MAX_LEN = 1024;auto ptr = (int *)(&MAX_LEN);*ptr = 2048;cout << MAX_LEN << endl; // 输出2048
MAX_LEN 虽然是个“只读变量”,但加上了 volatile 修饰,就表示它不稳定,可能会悄悄地改变。编译器在生成二进制机器码的时候,不会再去做那些可能有副作用的优化,而是用最“保守”的方式去使用 MAX_LEN,去内存里取值(而它已经通过指针被强制修改了)。
volatile 会禁止编译器做优化,所以除非必要,应当少用 volatile(除非你真的知道变量会如何被“悄悄地”改变),这也是几乎很少在代码里见到它的原因。
关键字 mutable
volatile 可以用来修饰任何变量,而 mutable 却只能修饰类里面的成员变量,表示变量即使是在 const 对象里,也是可以修改的。
volatile 可以用来修饰任何变量,而 mutable 却只能修饰类里面的成员变量,表示变量即使是在 const 对象里,也是可以修改的。
因为对象与普通的 int、double 不同,内部会有很多成员变量来表示状态,但因为“封装”特性,外界只能看到一部分状态,判断对象是否 const 应该由这些外部可观测的状态特征来决定。
比如说,对象内部用到了一个 mutex 来保证线程安全,或者有一个缓冲区来暂存数据,再或者有一个原子变量做引用计数……这些属于内部的私有实现细节,外面看不到,变与不变不会改变外界看到的常量性。这时,如果 const 成员函数不允许修改它们,就有点说不过去了。
对于这些有特殊作用的成员变量,你可以给它加上 mutable 修饰,解除 const 的限制,让任何成员函数都可以操作它。
class DemoClass final {private: mutable mutex_type m_mutex; // mutable成员变量public: void save_data() const // const成员函数 { // do someting with m_mutex }};
经验
mutable 也不要乱用,太多的 mutable 就丧失了 const的好处。在设计类的时候,一定要仔细考虑,和 volatile 一样要少用、慎用。
和预处理阶段的规则类似,常量的名字通常也用全大写的形式,但也有另外一种风格,就是在名字前加上“k”前缀。
因为函数参数是“传值”语义,所以对于简单的值类型,如int、double,不用const&的形式,也不会影响效率。
const_.cast是C++的四个转型操作符之一,专门用来去除“常量性”,可以用在某些极特殊的场景,比如调用纯C接口,但应当少用,最好不用。
成员函数有一个隐含的this参数,所以从语义上来说,const成员函数实际上是传入了一个const this指针,但因为C++语法限制,无法声明const this,所以就把const放到了函数后面。
依据应用场景,有的成员函数可能既是const又是非const,所以就会有两种重载形式,比如vector的front()、at()等,如果是const对象编译器就会调用const版本。
C++11里mutable又多了一种用法,可以修饰lambda表达式。
C++11引入了新关键字constexpr,能够表示真正的编译阶段常量,甚至能够编写在编译阶段运行的数值函数。
08 | smart_ptr:智能指针到底“智能”在哪里?
const 可以修饰指针,不过作者说:请忘记这种用法,在现代 C++ 中,绝对不要再使用“裸指针(naked pointer)”了,而是应该使用“智能指针(smart pointer)”。
指针是源自 C 语言的概念,本质上是一个内存地址索引,代表了一小片内存区域(也可能会很大),能够直接读写内存。因为这种索引,所以多个指针可以指向同一块内存,也能对同一块内存进行操作,所以释放就不能重复释放。当然这也是虚拟内存的概念,用户不用感知系统如何分配内存的,好像每个用户都拥有计算机全部内存一样。
因为它完全映射了计算机硬件,所以操作效率高,是 C/C++ 高效的根源。当然,这也是引起无数麻烦的根源。访问无效数据、指针越界,或者内存分配后没有及时释放,就会导致运行错误、内存泄漏、资源丢失等一系列严重的问题。
Java、Go 就没有这方面的顾虑,因为它们内置了一个“垃圾回收”机制,会检测不再使用的内存,自动释放资源。
C++ 里也是有广义上的垃圾回收,这就是构造 / 析构函数和RAII 惯用法(Resource Acquisition Is Initialization)。
可以应用代理模式,把裸指针包装起来,在构造函数里初始化,在析构函数里释放。这样当对象失效销毁时,C++ 就会自动调用析构函数,完成内存释放、资源回收等清理工作。
智能指针完全实践了 RAII,包装了裸指针,而且因为重载了 * 和 -> 操作符,用起来和原始指针一模一样。
unique_ptr
unique_ptr 在声明的时候必须用模板参数指定类型:
unique_ptr<int> ptr1(newint(10)); // int智能指针assert(*ptr1 = 10); // 可以使用*取内容assert(ptr1 != nullptr); // 可以判断是否为空指针unique_ptr<string> ptr2(newstring("hello")); // string智能指针assert(*ptr2 == "hello"); // 可以使用*取内容assert(ptr2->size() == 5); // 可以使用->调用成员函数
unique_ptr 虽然名字叫指针,用起来也很像,但它实际上并不是指针,而是一个对象。但是又不能把它当成普通对象来用,使用之前必须初始化!不能未经初始化,声明后直接使用。
unique_ptr<int> ptr3; // 未初始化智能指针*ptr3 = 42; // 错误!操作了空指针
未初始化的 unique_ptr 表示空指针,这样就相当于直接操作了空指针,运行时就会产生致命的错误(比如 core dump)。
不要企图对它调用delete,它会自动管理初始化时的指针,在离开作用域时析构释放内存。 另外,它也没有定义加减运算,不能随意移动指针地址,这就完全避免了指针越界等危险操作。
可以使用make_unique(),强制创建智能指针的时候必须初始化。同时还可以利用自动类型推导的 auto,少写一些代码:
auto ptr3 = make_unique<int>(42); // 工厂函数创建智能指针assert(ptr3 &&*ptr3 == 42);auto ptr4 = make_unique<string>("god of war"); // 工厂函数创建智能指针assert(!ptr4->empty());
这里作者说make_unique()是工厂函数,这里表示不认同:
make_unique仅仅是做了一层指针包裹,可以看下源码实现:
#if __TBB_CPP11_SMART_POINTERS_PRESENT && __TBB_CPP11_RVALUE_REF_PRESENT && __TBB_CPP11_VARIADIC_TEMPLATES_PRESENTtemplate<typename T, typename... Args>std::unique_ptr<T> make_unique(Args&&... args){returnstd::unique_ptr<T>(new T(std::forward<Args>(args)...)); }#endif
unique_ptr 的所有权
使用 unique_ptr 的时候还要特别注意指针的“所有权”问题。
unique_ptr 表示指针的所有权是“唯一”的,不允许共享,任何时候只能有一个对象持有它。
为了实现这个目的,unique_ptr 应用了 C++ 的“转移”(move)语义,同时禁止了拷贝赋值,所以,在向另一个 unique_ptr 赋值的时候,要特别留意,必须用 std::move() 函数显式地声明所有权转移。尽量不要对 unique_ptr 执行赋值操作!
赋值操作之后,指针的所有权就被转走了,原来的 unique_ptr 变成了空指针,新的 unique_ptr 接替了管理权,保证所有权的唯一性:
auto ptr1 = make_unique<int>(42); // 工厂函数创建智能指针assert(ptr1 &&*ptr1 == 42); // 此时智能指针有效auto ptr2 = std::move(ptr1); // 使用move()转移所有权assert(!ptr1 && ptr2); // ptr1变成了空指针
Shared_ptr
它的所有权是可以被安全共享的,也就是说支持拷贝赋值,允许被多个“人”同时持有,就像原始指针一样。
shared_ptr 支持安全共享的秘密在于内部使用了“引用计数”。
auto ptr1 = make_shared<int>(42); // 创建智能指针assert(ptr1 &&ptr1.unique()); // 此时智能指针有效且唯一auto ptr2 = ptr1; // 直接拷贝赋值,不需要使用move()assert(ptr1 &&ptr2); // 此时两个智能指针均有效assert(ptr1 == ptr2); // shared_ptr可以直接比较// 两个智能指针均不唯一,且引用计数为2assert(!ptr1.unique() && ptr1.use_count() == 2);assert(!ptr2.unique() && ptr2.use_count() == 2);
引用计数最开始的时候是 1,表示只有一个持有者。如果发生拷贝赋值——也就是共享的时候,引用计数就增加,而发生析构销毁的时候,引用计数就减少。只有当引用计数减少到 0,也就是说,没有任何人使用这个指针的时候,它才会真正调用 delete 释放内存。
因为 shared_ptr 具有完整的“值语义”(即可以拷贝赋值),所以,它可以在任何场合替代原始指针,而不用再担心资源回收的问题,比如用于容器存储指针、用于函数安全返回动态创建的对象,等等。
shared_ptr 的注意事项
shared_ptr是有代价的,引用计数的存储和管理都是成本,这方面是 shared_ptr 不如unique_ptr 的地方。
如果不考虑应用场合,过度使用 shared_ptr 就会降低运行效率。不过,你也不需要太担心,shared_ptr 内部有很好的优化,在非极端情况下,它的开销都很小。
把指针交给了 shared_ptr 去自动管理,但在运行阶段,引用计数的变动是很复杂的,很难知道它真正释放资源的时机。
要特别小心对象的析构函数,不要有非常复杂、严重阻塞的操作。一旦 shared_ptr 在某个不确定时间点析构释放资源,就会阻塞整个进程或者线程,“整个世界都会静止不动”。
shared_ptr:还有很多高级用法,比如定制删除函数,不只是用delete:释放内存,而是能够执行任意的代码。
这在把 shared_ptr 作为类成员的时候最容易出现,典型的例子就是链表节点。
classNodefinal {public:using this_type = Node;using shared_type = std::shared_ptr<this_type>;public: shared_type next; // 使用智能指针来指向下一个节点};auto n1 = make_shared<Node>(); // 创建智能指针auto n2 = make_shared<Node>(); // 创建智能指针assert(n1.use_count() == 1); // 引用计数为1assert(n2.use_count() == 1);n1->next = n2; // 两个节点互指,形成了循环引用n2->next = n1;assert(n1.use_count() == 2); // 引用计数为2assert(n2.use_count() == 2); // 无法减到0,无法销毁,导致内存泄漏
循环引用多算了一次计数,后果就是引用计数无法减到 0,无法调用析构函数执行 delete,最终导致内存泄漏。
这个例子很简单,你一下子就能看出存在循环引用。但在实际开发中,指针的关系可不像例子那么清晰,很有可能会不知不觉形成一链条很长的循环引用,复杂到你根本无法识别,想要找出来基本上是不可能的。
解决办法使用:weak_ptr
它专门为打破循环引用而设计,只观察指针,不会增加引用计数(弱引用),但在需要的时候,可以调用成员函数 lock(),获取 shared_ptr(强引用)。
classNodefinal {public:using this_type = Node;// 注意这里,别名改用weak_ptrusing shared_type = std::weak_ptr<this_type>;public: shared_type next; // 因为用了别名,所以代码不需要改动};auto n1 = make_shared<Node>(); // 创建智能指针auto n2 = make_shared<Node>(); // 创建智能指针n1->next = n2; // 两个节点互指,形成了循环引用n2->next = n1;assert(n1.use_count() == 1); // 因为使用了weak_ptr,引用计数为1assert(n2.use_count() == 1); // 打破循环引用,不会导致内存泄漏if (!n1->next.expired()) { // 检查指针是否有效auto ptr = n1->next.lock(); // lock()获取shared_ptr assert(ptr == n2);}
weak_ptr::expired():检查所指向的对象是否已被销毁(引用计数为 0);weak_ptr::lock():若对象未销毁,返回指向该对象的 shared_ptr;若已销毁,返回空 shared_ptr。
如果在shared_ptr的基础上增加对指针是否为空的判断是否也能解决问题?
答:不能。检查 “指针是否为空”,只能判断 shared_ptr 本身是否为空(而非对象是否存活),但这对解决循环引用毫无帮助。
这种检查只能判断 n1->next 是否指向某个对象,但无法改变 “循环引用导致计数不归零” 的本质 —— 即便 n1->next != nullptr,对象也永远不会被销毁。
// 改为shared_ptr后的“有效性检查”(仅判断指针是否为空,无实际意义)if (n1->next != nullptr) { // 替代expired(),但逻辑完全不同auto ptr = n1->next; // 直接获取shared_ptr,无需lock() assert(ptr == n2);}
expired() 是 std::weak_ptr 的专属成员函数,std::shared_ptr 根本没有这个接口;循环引用的本质(引用计数无法归零)也无法通过 “检查指针有效性” 解决。
如果已经理解了智能指针,就尽量不要再使用裸指针、new 和delete 来操作内存了。
有的资料不建议在函数的入口参数里使用shared_ptr,原因是成本高。作者的意见是程序的正确性和安全性是第一位的,先放手去用,保证功能正确之后才是性能优化。
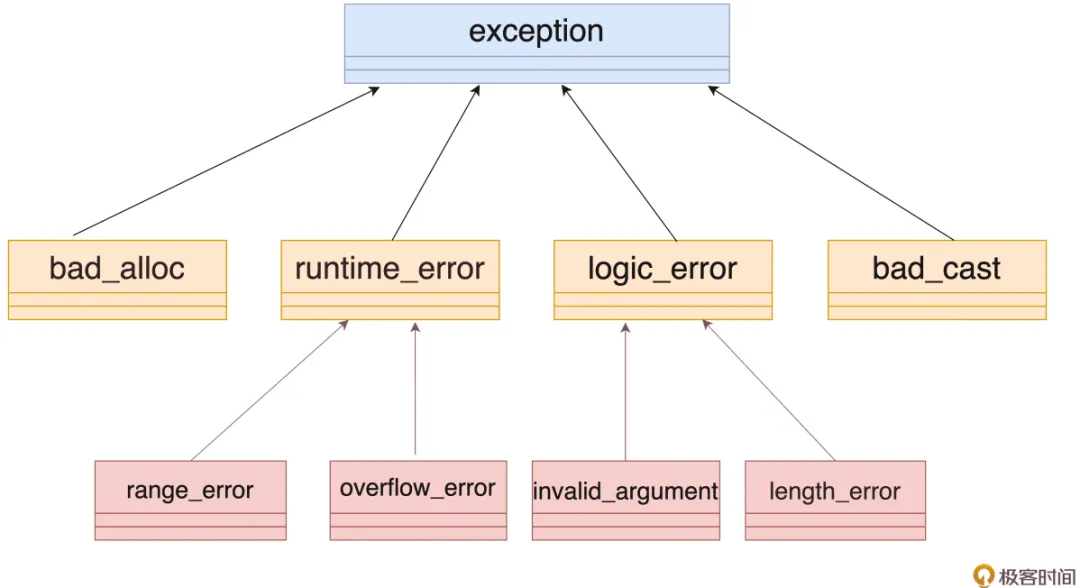
09 | exception:怎样才能用好异常?
C++ 处理错误的标准方案是“异常”(exception)。
在 C++ 之前,处理异常的基本手段是“错误码”。函数执行后,需要检查返回值或者全局的 errno,看是否正常,如果出错了,就执行另外一段代码处理错误。
异常是针对错误码的缺陷而设计的,它不能被忽略,而且可以“穿透”调用栈,逐层传播到其他地方去处理;
异常就是针对错误码的缺陷而设计的,它有三个特点。
- 异常的处理流程是完全独立的,throw 抛出异常后就可以不用管了,错误处理代码都集中在专门的 catch 块里。这样就彻底分离了业务逻辑与错误逻辑,看起来更清楚。
- 异常是绝对不能被忽略的,必须被处理。如果你有意或者无意不写catch 捕获异常,那么它会一直向上传播出去,直至找到一个能够 处理的 catch 块。如果实在没有,那就会导致程序立即停止运行,明白地提示你发生了错误,而不会“坚持带病工作”。
- 异常可以用在错误码无法使用的场合,这也算是 C++ 的“私人原因”。因为它比 C 语言多了构造 / 析构函数、操作符重载等新特性,有的函数根本就没有返回值,或者返回值无法表示错误,而全局的 errno 实在是“太不优雅”了,与 C++ 的理念不符,所以也必须使用异常来报告错误。
C++ 里对异常的定义非常宽松,任何类型都可以用throw 抛出,也就是说,你可以直接把错误码(int)、或者错误消息(char*、string)抛出,catch 也能接住,然后处理。
同时C++ 已经为处理异常设计了一个配套的异常类型体系,定义在标准库的 <stdexcept> 头文件里。
boost.exception.库是对C++标准异常的一个很好的补充,不需要定义复杂的数据结构,就可以向异常对象添加任意的信息,非常方便。
派生出异常类
比如可以从 runtime_error 派生出自己的异常类:
classmy_exception :publicstd::runtime_error {public:using this_type = my_exception; //给自己起个别名using super_type = std::runtime_error; //给父类也起个别名public: my_exception(constchar *msg) : //构造函数 super_type(msg) //别名也可以用于构造 {} my_exception() = default; //默认构造函数 ~my_exception() = default; //默认析构函数private:int code = 0; //其他的内部私有数据};
建议最好不要直接用 throw 关键字,而是要封装成一个函数,这和不要直接用 new、delete 关键字是类似的道理——通过引入一个“中间层”来获得更多的可读性、安全性和灵活性。
抛异常的函数不会有返回值,所以应该用“属性”做编译阶段优化:
[[noreturn]]// 属性标签voidraise(constchar* msg)// 函数封装throw,没有返回值{throw my_exception(msg); // 抛出异常,也可以有更多的逻辑}
使用 catch 捕获异常的时候也要注意,C++ 允许编写多个 catch 块,捕获不同的异常,再分别处理。但是,异常只能按照 catch 块在代码里的顺序依次匹配,而不会去找最佳匹配。建议最好只用一个 catch 块,绕过这个“坑”。
写 catch 块就像是写一个标准函数,所以入口参数也应当使用“const&”的形式,避免对象拷贝的代价:
try { raise("error occured"); // 函数封装throw,抛出异常} catch (const exception &e) // const &捕获异常,可以用基类{cout << e.what() << endl; // what()是exception的虚函数}
function-try
关于 try-catch,还有一个很有用的形式:function-try。
所谓 function-try,就是把整个函数体视为一个大 try 块,而 catch 块放在后面,与函数体同级并列。
function-try允许将整个函数体(包括构造 / 析构函数的初始化列表)包裹在 try 块中,用于捕获函数执行过程中(含初始化 / 析构阶段)抛出的所有异常。核心适用于:
- 构造函数的特殊行为(捕获初始化列表中抛出的异常):
- 构造函数的 function-try 捕获的异常(无论来自初始化列表还是函数体),在 catch 块执行完毕后,会被自动重新抛出(无法让构造函数 “吞掉异常”);
- 原因:若构造过程中抛出异常,对象未完全构造,C++ 不允许返回一个 “不完整的对象”。
- 构造函数中,
function-try 是唯一能捕获初始化列表异常的方式。
- 析构函数的 function-try 可捕获析构体中的异常,但 C++11 后析构函数默认
noexcept,抛出异常会直接调用 std::terminate(除非显式声明 noexcept(false))。
- 普通函数的 function-try 与 “函数内包裹 try-catch” 效果几乎一致,唯一区别是语法形式(function-try 更强调 “捕获函数所有异常”)。
这样做的好处很明显,不仅能够捕获函数执行过程中所有可能产生的异常,而且少了一级缩进层次,处理逻辑更清晰,建议多用。
普通函数
voidsome_function()// 函数名之后直接写try块try{ ...} catch (...) // catch块与函数体同级并列{ ...}
示例:
#include<iostream>#include<stdexcept>usingnamespacestd;intdivide(int a, int b)try{if (b == 0) throw runtime_error("除数不能为0");return a / b;} catch (const runtime_error& e) {cerr << "divide 捕获异常:" << e.what() << endl;return-1; // 普通函数可吞掉异常(与构造函数不同)}intmain(){int res = divide(10, 0);cout << "结果:" << res << endl; // 输出:结果:-1return0;}
构造函数的 function-try 语法(最常用)
类名(参数列表)try : 初始化列表(参数) { // 初始化列表在 try 后、函数体前 构造函数体;} catch (异常类型& e) { 异常处理;// 注意:构造函数的 catch 块结束后,异常会被自动重新抛出(无法吞掉)}
示例:
#include<iostream>#include<stdexcept>usingnamespacestd;classMyClass {private:int* ptr;int val;// 辅助函数:模拟初始化时抛异常staticintinitVal(int x){if (x < 0) throw runtime_error("val 不能为负数");return x; }public:// 构造函数的 function-try(捕获初始化列表异常) MyClass(int x, int y)try : ptr(newint(x)), val(initVal(y)) { // 初始化列表cout << "构造函数体执行" << endl; } catch (const bad_alloc& e) { // 捕获 new 失败的异常cerr << "构造失败:内存分配错误 - " << e.what() << endl;// 异常会自动重新抛出 } catch (const runtime_error& e) { // 捕获 initVal 抛的异常cerr << "构造失败:初始化错误 - " << e.what() << endl;// 异常会自动重新抛出 } ~MyClass() {delete ptr;cout << "析构函数执行" << endl; }};intmain(){try {MyClass obj(10, -5); // val 为负数,初始化列表抛异常 } catch (const exception& e) {cerr << "main 捕获异常:" << e.what() << endl; }return0;}
输出:
构造失败:初始化错误 - val 不能为负数main 捕获异常:val 不能为负数
析构函数
析构函数默认 noexcept,抛出异常会直接终止程序:
~MyClass() noexcept(false) // 显式允许抛异常try {// 析构逻辑} catch (...) {// 处理异常}
小结
| | |
|---|
| 捕获初始化列表 / 函数体异常,做清理(如释放资源) | |
| | |
| 捕获析构体异常(需显式 noexcept (false)) | |
一般认为,重要的构造函数(普通构造、拷贝构造、转移构造)、析构函数应该尽量声明为noexcept,优化性能,而析构函数则必须保证绝不会抛异常。
异常开销
异常的抛出和处理需要特别的栈展开(stack unwind)操作,如果异常出现的位置很深,但又没有被及时处理,或者频繁地抛出异常,就会对运行性能产生很大的影响。
区分“非”错误、“轻微”错误和“严重”错误,谨慎使用异常。
应当使用异常的判断准则
- 无法本地处理,必须“穿透”调用栈,传递到上层才能被处理的错误。
比如说构造函数,如果内部初始化失败,无法创建,那后面的逻辑也就进行不下去了,所以这里就可以用异常来处理。
再比如,读写文件,通常文件系统很少会出错,总会成功,如果用错误码来处理不存在、权限错误等,就显得太啰嗦,这时也应该使用异常。
相反的例子就是 socket 通信。因为网络链路的不稳定因素太多,收发数据失败简直是“家常便饭”。虽然出错的后果很严重,但它出现的频 率太高了,使用异常会增加很多的处理成本,为了性能考虑,还是检查错误码重试比较好。
noexcept 保证不抛出异常
noexcept 专门用来修饰函数,告诉编译器:这个函数不会抛出异常。编译器看到 noexcept,就得到了一个“保证”,就可以对函数做优化,不去加那些栈展开的额外代码,消除异常处理的成本。
和 const 一样,noexcept 要放在函数后面:
voidfunc_noexcept()noexcept// 声明绝不会抛出异常{cout << "noexcept" << endl;}
noexcept 只是做出了一个“不可靠的承诺”,不是“强保证”,编译器无法彻底检查它的行为,标记为 noexcept 的函数也有可能抛出异常。
noexcept也可以当作运算符,指定在某个条件下才不会抛出异常,常用的“noexcept'”其实相当于“noexcept(true)”。
10 | lambda:函数式编程带来了什么?
lambda 表达式
auto func = [](int x) // 定义一个lambda表达式{cout << x*x << endl; // lambda表达式的具体内容};func(3); // 调用lambda表达式
因为 lambda 表达式是一个变量,所以,我们就可以“按需分配”,随时随地在调用点“就地”定义函数,限制它的作用域和生命周期,实现函 数的局部化。
而且,因为 lambda 表达式和变量一样是“一等公民”,用起来也就更灵活自由,能对它做各种运算,生成新的函数。这就像是数学里的复合函数那样,把多个简单功能的小 lambda 表达式组合,变成一个复杂的大 lambda 表达式。
C++ 里的 lambda 表达式除了可以像普通函数那样被调用,还可以“捕获”外部变量,在内部的代码里直接操作。
int n = 10; // 一个外部变量auto func = [=](int x) // lambda表达式, 用“=”值捕获{cout << x*n << endl; // 直接操作外部变量}; func(3); // 调用lambda表达式
auto a = [](int x) // a函数执行一个功能{...}auto b = [](double x) // b函数执行一个功能{...}auto c = [](string str) // c函数执行一个功能{...}auto f = [](...) // f函数执行一个功能{...}return f(a, b, c) // f调用a/b/c运算得到结果
使用 lambda 的注意事项
3个重点:语法形式,变量捕获规则,泛型的用法。
1.lambda 的形式
“[]” 为“lambda 引出符”(lambda introducer)。
在 lambda 引出符后面,就可以像普通函数那样,用圆括号声明入口参数,用花括号定义函数体。
函数体里可能会有很多语句,所以一定要有良好的缩进格式——特别是有嵌套定义的时候。
auto f1 = [](){}; // 相当于空函数,什么也不做auto f2 = []() // 定义一个lambda表达式{cout << "lambda f2" << endl;auto f3 = [](int x) // 嵌套定义lambda表达式 { return x * x; }; // lambda f3 // 使用注释显式说明表达式结束cout << f3(10) << endl;}; // lambda f2 // 使用注释显式说明表达式结束
在 lambda 表达式赋值的时候,使用 auto 来推导类型。这是因为,在 C++ 里,每个 lambda 表达式都会有一个独特的类型,而这个类型只有编译器才知道,我们是无法直接写出来的,所以必须用 auto。
C++ 也鼓励程序员尽量“匿名”使用 lambda 表达式。
这样不仅可以让代码更简洁,而且因为“匿名”,lambda 表达式调用完后也就不存在了(也有被拷贝保存的可能),这就最小化了它的影响范围,让代码更加安全。
vector<int> v = {3, 1, 8, 5, 0}; // 标准容器cout << *find_if(begin(v), end(v), // 标准库里的查找算法 [](int x) // 匿名lambda表达式,不需要auto赋值 {return x >= 5; // 用做算法的谓词判断条件 } // lambda表达式结束 ) << endl; // 语句执行完,lambda表达式就不存在了
2.lambda 的变量捕获
- “[=]”表示按值捕获所有外部变量,表达式内部是值的拷贝,并且不能修改;
- “[&]”是按引用捕获所有外部变量,内部以引用的方式使用,可以修改;
- 可以在“[]”里明确写出外部变量名,指定按值或者按引用捕获,C++ 在这里给予了非常大的灵活性。
int x = 33; // 一个外部变量auto f1 = [=]() // lambda表达式,用“=”按值捕获{// x += 10; // x只读,不允许修改。其实可以修改,修改之后不影响外部x的值,相当于单独拷贝了一份};auto f2 = [&]() // lambda表达式,用“&”按引用捕获{ x += 10; // x是引用,可以修改};auto f3 = [=, &x]() // lambda表达式,用“&”按引用捕获x,其他的按值捕获{ x += 20; // x是引用,可以修改};// 捕获类本身classDemoLambdafinal {private:int x = 0;public:autoprint()// 返回一个lambda表达式供外部使用{return [this]() // 显式捕获this指针 { cout << "member = " << x << endl; }; }};
理解“捕获”,关键是要理解“外部变量”的含义。可以简单地按照其他语言的习惯,称之为“upvalue”,也就是在 lambda 表达式定义之前所有出现的变量,不管它是局部的还是全局的。
这就有一个变量生命周期的问题。
经验:
- 使用“[=]”按值捕获的时候,lambda 表达式使用的是变量的独立副本,非常安全。
- 使用“[&]”的方式捕获引用就存在风险,当 lambda 表达式在离定义点“很远的地方”被调用的时候,引用的变量可能发生了变化,甚至可能会失效,导致难以预料的后果。
- 在使用捕获功能的时候要小心,对于“就地”使用的小lambda 表达式,可以用“[&]”来减少代码量,保持整洁;
- 而对于非本地调用、生命周期较长的 lambda 表达式应慎用“[&]”捕获引用,而且,最好是在“[]”里显式写出变量列表,避免捕获不必要的变量。
3. 泛型的 lambda
在 C++14 里,lambda 表达式又多了一项新本领,可以实现“泛型化”,相当于简化了的模板函数。
auto f = [](constauto &x) // 参数使用auto声明,泛型化{ return x + x; };cout << f(3) << endl; // 参数类型是intcout << f(0.618) << endl; // 参数类型是doublestring str = "matrix";cout << f(str) << endl; // 参数类型是string
这个新特性在写泛型函数的时候非常方便,摆脱了冗长的模板参数和函数参数列表。如果你愿意的话,可以尝试在今后的代码里都使用lambda 来代替普通函数,能够少写很多代码。
小结
- 比照“智能指针”的说法,lambda 完全可以称为是“智能函数”,价值体现在就地定义、变量捕获等能力上,它也给 C++ 的算法、并发(线程、协程)等后续发展方向铺平了道路。
- lambda 表达式是一个闭包,能够像函数一样被调用,像变量一样被传递;C++ 鼓励尽量就地匿名使用,缩小作用域;
- lambda 表达式使用“[=]”的方式按值捕获,使用“[&]”的方式按引用捕获,空的“[]”则是无捕获(也就相当于普通函数);
- 捕获引用时必须要注意外部变量的生命周期,防止变量失效;
- 滥用 lambda 表达式的话,就会产生一些难以阅读的代码,比如多个函数的嵌套和串联、调用层次过深。
- 目前,lambda 表达式还不支持function-try,只能在函数体内部用try-catch。
- lambda表达式的返回值类型可以自动推导(相当于用了auto),但有的时候必须明确指定返回值类型,这个时候就得用比较“怪异”的返回值后置语法,在入口参数的圆括号后用“->type”的形式。
- 在按值捕获外部变量的时候,可以给lambda表达式加上mutable修饰,允许修改变量。注意,这与按引用捕获不同,修改的只是变量的拷贝,不影响外部变量的原值。
- 如果确实需要长期持有外部变量,为了避免变量失效,可以考虑使用
shared_ptr. - 因为每个lambda表达式的类型都是唯一的,所以即使函数签名相同,lambda变量也不能互相赋值。解决办法是使用标准库里的
std::function类,它是“函数的容器”“智能函数指针”,可以存储任意符合签名的“可调用物”(callable object)搭配使用能够让lambda表达式用起来更灵活。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
