偷懒的论文学习笔记(2)|DeepSeek 架构再进化!提出 mHC:给神经网络装上“流形稳定器”,彻底解决超连接训练不稳定性
DeepSeek 架构再进化!提出 mHC:给神经网络装上“流形稳定器”,彻底解决超连接训练不稳定性。
核心速览:
- • 痛点:Hyper-Connections (HC) 虽然能通过拓宽残差流提升性能,但破坏了“恒等映射”性质,导致大规模训练信号爆炸、不稳定。
- • 方案:mHC (Manifold-Constrained Hyper-Connections)。通过将连接矩阵投影到“双随机矩阵”流形上,强制恢复信号守恒。
- • 效果:在 27B 参数模型上验证,mHC 不仅完全修复了训练不稳定性,还在 MATH、GSM8K 等任务上全面超越基线,且额外训练开销仅为 6.7%。
在 Transformer 统治大模型架构的当下,“残差连接”(Residual Connection)一直是模型深度的保障。最近, Hyper-Connections (HC) 的技术试图通过“把路修宽”(扩展残差流宽度)来提升模型性能,但却撞上了“训练不稳定”和“显存墙”两座大山。
DeepSeek-AI 团队发布最新论文 《mHC: Manifold-Constrained Hyper-Connections》,提出了一种通用的架构框架 mHC。他们用巧妙的数学约束(流形投影)和极致的工程优化,成功驯服了 Hyper-Connections。
01 HC 的困境:为了变强,牺牲了“稳”
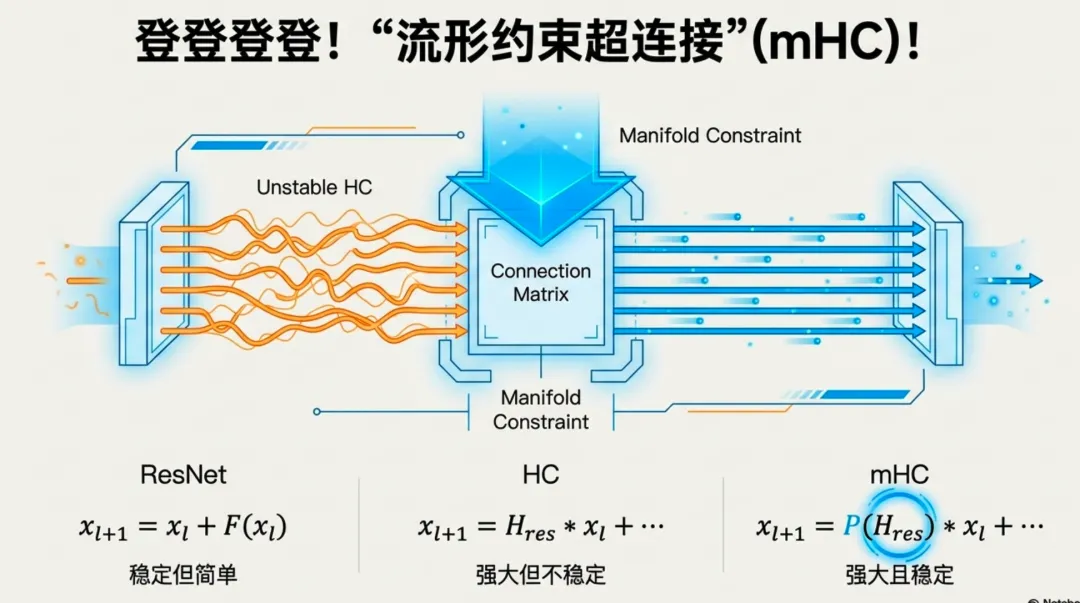
传统的残差连接公式是 ,其中的 (恒等映射)保证了信号能无损地传到深层,是训练深层网络的基石。
Hyper-Connections (HC) 的思路是:将残差流 的维度扩大 倍(例如 4 倍),并引入可学习的矩阵 来混合这些流。
问题出在哪里?随着层数叠加,多个 矩阵相乘。由于这些矩阵是无约束的,信号强度会发生剧烈波动,破坏了恒等映射的“守恒”机制。
- • 数据说话:DeepSeek 在 27B 模型上的实验显示,HC 的前向信号增益(Amax Gain Magnitude)峰值竟然高达 3000!这意味着信号在传递过程中被疯狂放大,直接导致梯度爆炸和 Loss 激增。
02 DeepSeek 的解法:把矩阵关进“流形”里
DeepSeek 提出的 mHC(流形约束超连接),核心思想非常优雅:如果无约束的矩阵会导致信号失控,那我们就给它加个数学“紧箍咒”。
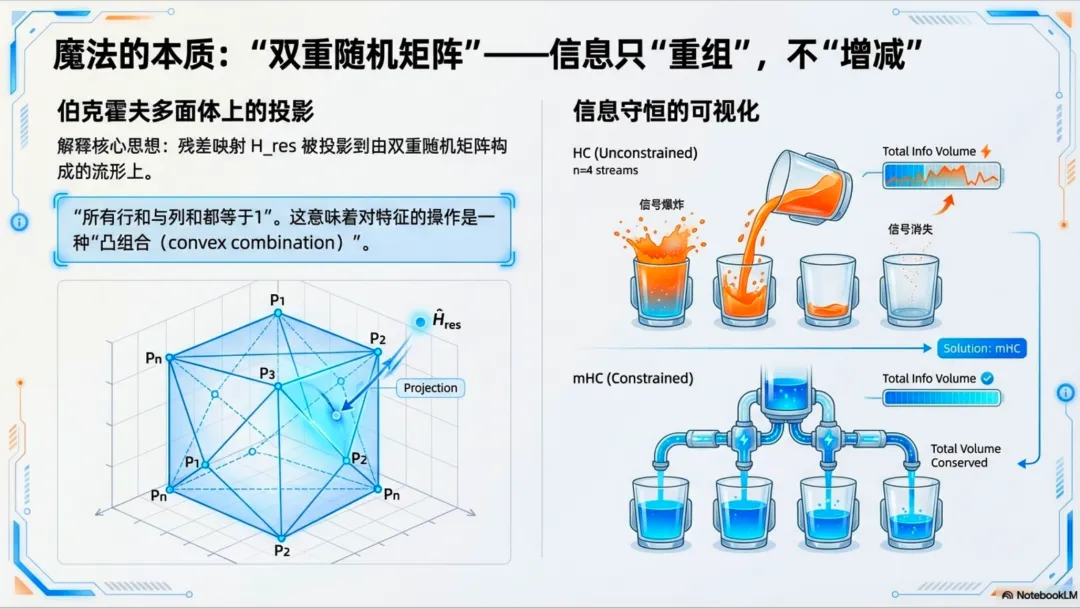
1. 引入“双随机矩阵” (Doubly Stochastic Matrices)mHC 强制要求残差连接矩阵 必须投影到 Birkhoff 多胞形上。简单说,就是要求矩阵的每一行之和为 1,每一列之和也为 1。
2. Sinkhorn-Knopp 算法为了实现这个约束,DeepSeek 使用了 Sinkhorn-Knopp 算法进行迭代归一化。
- • 几何解释:这使得残差映射变成了特征的“凸组合”(Convex Combination),而非简单的线性叠加。
- • 数学性质:双随机矩阵相乘后依然是双随机矩阵。这意味着,无论网络堆叠多少层,信号的范数都受到严格控制,不会发生爆炸或消失。
效果立竿见影:在 mHC 中,信号增益被完美控制在 1.6 左右,相比 HC 的 3000 降低了三个数量级,彻底恢复了训练稳定性。
03 工程优化:打破“显存墙”
理论很美好,但把残差流扩大 倍,意味着内存访问(I/O)成本也会暴涨。如果直接训练,速度会慢到无法接受。
DeepSeek 在 mHC 中展示了其标志性的极致基础设施优化能力:
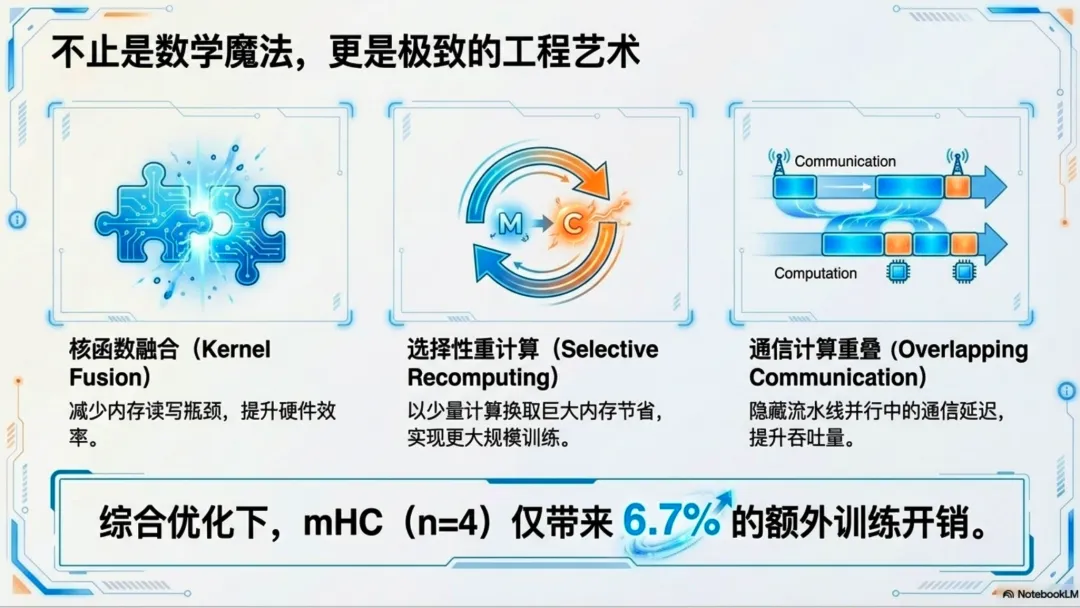
- 1. 内核融合 (Kernel Fusion):利用 TileLang 开发定制内核,将 RMSNorm、矩阵乘法和 Sinkhorn-Knopp 迭代融合,大幅减少显存读写次数。
- 2. 选择性重计算 (Selective Recomputing):为了节省显存,前向传播丢弃中间激活值,反向传播时再重新计算。DeepSeek 推导出了最优的重计算块大小 ,精准平衡了计算与显存。
- 3. DualPipe 通信重叠:扩展了 DualPipe 调度策略,将 MLP 层放在高优先级计算流上,完美掩盖了 mHC 带来的额外通信延迟。
最终结果:在 的扩展倍率下,mHC 的训练时间开销仅增加了 6.7%。
04 实验结果:全面超越
DeepSeek 基于 DeepSeek-V3 的 MoE 架构,训练了 3B、9B 和 27B 参数量的模型进行验证。
- • 稳定性:mHC 的 Loss 曲线和梯度范数(Gradient Norm)与标准基线模型几乎一致,完全消除了 HC 的尖峰抖动。
- • 下游任务:在 GSM8K (数学)、DROP (阅读理解)、BBH (推理) 等 benchmark 上,mHC 全面超越了标准 Baseline 和原始 HC。
- • GSM8K (8-shot): Baseline 78.5 -> mHC 80.5
- • DROP (F1): Baseline 47.0 -> mHC 53.9
- • BBH (3-shot): Baseline 43.8 -> mHC 51.0
结语
DeepSeek 的这项工作再次证明,大模型架构的创新不仅仅是“堆参数”或“改算子”,更在于对底层数学性质(如信号守恒)的深刻理解与系统级工程优化的结合。
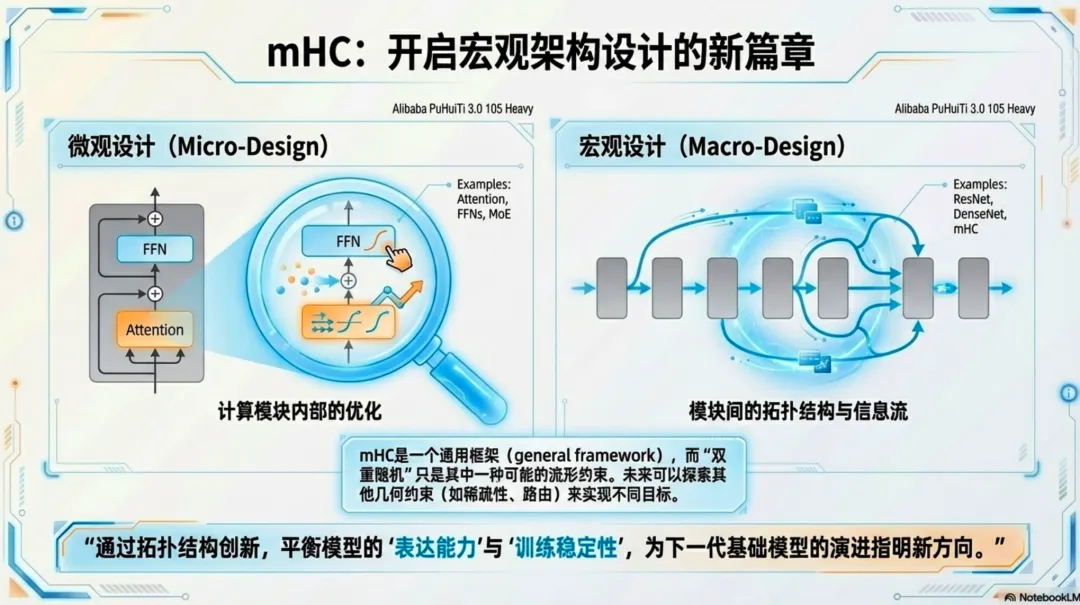
mHC 为未来的大模型设计指明了一个新方向:通过拓扑结构的流形约束,我们完全可以在保持训练稳定的前提下,进一步释放神经网络的表达能力。
参考资料:
- • Xie et al. mHC: Manifold-Constrained Hyper-Connections. DeepSeek-AI, 2025.
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,