第01章 导论
生物学正越来越成为一门数据驱动的科学,而深度学习(deep learning)作为机器学习中一个极具威力的分支,正在为我们打开新的路径,让我们能够从复杂、高维的数据集中发掘规律。随着这两个领域不断交汇,我们也迎来了借助现代计算工具提取有意义洞察的新机会。本书就是一本聚焦于这一交叉地带的实用入门书,重点帮助你建立把深度学习有效应用到生物学场景中的技能与思维方式。
开始之前
本章的作用,是先帮你建立整体方向感。在正式写代码之前,我们会先讨论如何界定一个项目、如何评估你的数据,以及如何避开一些常见陷阱。前期多做一点结构化思考与规划,会让你的工作更可复现、更灵活,也更可能真正产生价值和影响。
先想清楚你的模型要替代什么
在生物学中做深度学习项目,成败往往在写下第一行代码之前就已经埋下伏笔。人很容易陷进技术细节里,或者一连几周都在试各种数据处理和模型结构变化,最后却没有真正带来有意义的结果。尤其是在这样一个本身就很有趣的领域里,“先试试看这个能不能再调一调”的诱惑会非常强。为了避免失焦,最有帮助的做法之一,就是一开始先问自己几个扎根现实的问题。
其中最关键的一个问题是:你的模型到底准备替代或改进现有流程中的哪一部分?这个领域里影响力最大的项目,通常都会对这个问题有一个比较清楚的回答。下面是一些不同方向上的例子。
在医疗健康和药物发现中:
- 皮肤癌分类模型:目标是复现皮肤科医生根据临床图像诊断黑色素瘤或其他皮损的能力,从而为高风险人群提供更快、更可扩展的筛查方式。
- 病原体检测系统:基于测序数据或影像数据,直接从原始临床样本(如血液、唾液或组织)中检测细菌或病毒感染,潜在上可以替代更慢的培养式诊断流程。
- 脑肿瘤分割模型:自动完成或显著加速 MRI 图像中的肿瘤勾画工作,而这项任务通常需要放射科医生投入大量时间手工完成。
- 药物-靶点相互作用预测工具:用于优先筛选最有希望的化合物-靶点组合,从而减少对大规模化学文库进行昂贵湿实验筛选的需求。
- 抗生素耐药性预测模型:预测某个细菌菌株是否会对某些治疗产生耐药性,帮助临床医生更快选择有效抗生素。
在分子生物学中:
- AlphaFold:这一蛋白质结构预测模型在许多场景下,替代了借助 X 射线晶体学、冷冻电镜(cryo-EM)或核磁共振(NMR)等高成本实验手段去测定蛋白质三维结构的需求。
- 基因表达预测模型:直接从原始基因组序列预测基因活性,作为 RNA 测序(RNA-seq)实验的一种计算替代路径。
- 变异效应预测模型:帮助自动化解释遗传突变,通过优先标记可能致病的变异,辅助临床决策和后续实验验证。
在生态学和环境科学中:
- 声学物种分类系统:使用森林录音识别出现的动物物种,为现场生物多样性调查提供一种更可扩展、也更省人工的替代方式。
- 作物病害检测:通过无人机或卫星图像,提前识别植物压力和病害信号,减少在大田中依赖人工巡查的需要。
- 动物面部识别工具:在不需要耳标、项圈或其他侵入式标记的前提下,长期追踪个体动物,包括爬行动物、鸟类和哺乳动物。
- 反盗猎检测系统:基于红外或运动传感器数据,自动标记受保护野生动物区域中的可疑人类活动,辅助保护工作。
希望这些例子能让你更具体地感受到:深度学习到底能改进甚至替代哪些类型的工作流。只要有可能,你都应该尝试估计自己的模型潜在能带来多大影响,例如它能节省多少时间、多少成本、多少人工,或者它能开启什么新的洞察。这样做能帮助你始终把注意力放在工作的现实效用上,也更容易向合作者、利益相关方或公众解释项目价值。
提示
当然,并不是所有有价值的模型都必须去替代现有流程。有些模型打开的是全新的能力空间,例如生成新的生物序列、从海量数据中挖掘隐藏模式,或者把原本从未连接过的数据类型关联起来。这类模型未必能优化实验室里的某个既有任务,但它们可能会开启新的发现路径,拓展我们能提出的问题边界,或者提供理解复杂系统的新视角。如果你的模型创造的是一种新能力,那么关键是要把它究竟创造了什么、为什么重要说清楚;同时,当不存在现成 benchmark 时,也要更谨慎地设计成功标准。
明确你的成功标准
尽可能早、尽可能明确地定义“项目成功长什么样”,这很重要。研究工作天然容易耗时,也容易变成开放式探索,因此清晰目标能帮助你保持聚焦,避免陷入无止境的微调循环,例如不断更换模型、架构或训练设置,却没有明确假设和评估计划。由于深度学习中可选设计和超参数实在太多,这种试错循环非常常见。如果没有足够结构,最后不仅会浪费时间,结果往往也难以解释、难以复现。
成功标准的例子包括:
- 性能指标,例如准确率(accuracy)、AUC、F1。你可能希望达到人类专家的水平、让模型输出与实验结果的相关性达到技术重复(technical replicate)的水平,或者把假阳性率控制在某个阈值以下。
- 可解释性水平。在许多应用里,模型不仅要“效果好”,还要让领域专家能够理解它为什么做出这些判断。例如,当信任与可解释性特别重要时,你可能会优先考虑不确定性校准得更好的模型,或者优先使用能够给出可解释特征归因的方案。
- 模型大小或推理延迟。如果你的模型要在资源受限环境中运行,例如手机或嵌入式设备,或者它必须满足实时吞吐要求,例如每秒处理 20 帧图像,那么你的成功标准可能更多聚焦在效率上,例如单位浮点运算(FLOP)所获得的性能。在这种情况下,推理时间、内存占用和能耗可能比纯粹的准确率更重要。
- 训练时间和训练效率。当算力有限,或者你本身就在一个教学或低资源环境中工作时,你可能会优先追求训练更快、硬件要求更低的模型。由于深度学习训练通常依赖大规模矩阵运算,因此经常借助 GPU 加速。在低资源场景下,一个能够在 CPU 上快速训练的简单模型,往往比追求极致性能更现实。
- 泛化能力(generalizability)。有时你的目标并不是把某一个 benchmark 压到极限,而是构建一个能在多个数据集、多个任务上都表现不错的模型。例如基础模型(foundation model)这类在大范围数据上训练、可适配多种下游任务的大模型,往往更强调灵活性与可复用性。在这类场景中,广泛适用性可能比在一个单独任务上再多榨出几个百分点更有价值。
先把这些目标说清楚,能帮助你回答一个很核心的问题:这个项目什么时候算结束?你大概率需要在多个标准之间权衡,但只要你一开始就把它们摆在台面上,后续工作就更容易保持方向一致,也更不容易让范围失控。
把评估放到最重要的位置
一旦你定义好了成功标准,下一步就应该把评估(evaluation)提到最高优先级。这意味着你要认真思考:你到底准备用什么来衡量进展,用哪些指标,如何验证结果,又拿什么基线来比较。如果没有一套清晰、设计良好的评估策略,即便模型在技术上看起来非常炫,也可能根本无法得出有意义的结论。
强评估的价值不仅仅在于“衡量进展”。它还会帮助你发现 bug、估计任务难度,并逐渐形成对问题的直觉。这里最核心的思想其实很简单:你必须有一个已知的参照点,才能判断模型到底有没有学到真正有意义的东西。
提示
虽然没有放之四海皆准的比例,但一个成功的机器学习项目,花 50% 的时间设计评估和跑基线、花 25% 的时间整理和处理数据、只花 25% 的时间在模型架构本身上,并不让人意外。没有好的评估,你就像在盲飞:你不会知道模型到底有没有变好,不知道自己在做什么权衡,甚至不知道模型是否真的学到了任何有意义的规律。
所以请把时间花在这里。评估不是你在最后才做的一件事,而是你一开始就该设计好的东西,它会贯穿并指导整个项目。
设计基线
在评估工具里,最实用的东西之一,就是强基线(baseline)。所谓强基线,就是一个足够简单、但又能给你提供“必须打败的起点”的方法。好的基线能帮助你衡量进展、尽早发现 bug,并理解这个任务到底有多难。有时它们甚至会比你以为的更难超越。
想设计出好的基线,前提是先认真理解任务本身。下面是一些分类任务中常见的基线策略:
- 完全随机预测:对每个类别以相同概率随机抽样标签。它能告诉你,在完全没有信息的情况下,性能大概会是什么样。
- 按类别频率加权的随机预测:仍然随机抽样标签,但抽样概率按训练数据中的类别分布来定。这对不平衡数据集尤其有用。
- 多数类预测:永远预测最常见的类别。在高度类别不平衡的任务里,这个基线往往比你想象得更难打败。
- 最近邻:预测训练集中“最相似样本”的标签,例如用欧氏距离的 1-nearest neighbor。当输入维度较低、结构比较规整时,它往往意外地有效。
对于回归任务,可以考虑:
- 目标均值或中位数:永远输出训练集中目标值的平均数或中位数。如果模型什么也没学会,它最后常常就会收敛到这种行为。
- 单特征线性回归:只用最强的单个预测因子去拟合一条线,例如一个生物标志物。它能帮助你判断:复杂模型相比“最简单的有效信号”到底提升了多少。
- K 近邻回归:用最相似的
k 个数据点的目标值平均数,或加权平均,来做预测。它实现简单,而且在结构化数据上经常 surprisingly competitive。
同时适用于分类和回归的,还有:
- 简单启发式规则:直接利用领域知识构造一个非常朴素的规则。例如在诊断任务里,如果某个单一生物标志物或测量值超过阈值,就判定为阳性;在皮肤癌图像任务里,可以按病灶的平均像素强度排序;在基因组学里,如果任务是预测一个突变影响哪条基因,那么一个简单基线就是假设它影响的是基因组中最近的那条基因。
警告
如果你的模型连一个基础基线都打不过,那大概率说明哪里出了问题。而这件事本身就非常有价值,因为它会明确提醒你应该回头检查数据、特征或建模方案。
给项目设定时间边界
给项目做 time-box,也就是预先设定一个固定的时间窗口,到点之后不管结果如何都暂停或停止,这非常重要。很多研究想法最后会“失败”,意思是它们没有达到你预期中的指标。这太正常了。所有项目,哪怕是不成功的项目,也会产出对未来工作有帮助的洞察。time-box 的意义就在于:即使实验失败,它也仍然能推动你前进,而不会无休止地吞噬时间和精力。
注记
time-box 不等于轻易放弃,它的本质是为自己设置边界,好让你维持聚焦、避免耗竭,并持续推进。
更具体一点,可以这样做:
- 设定清晰截止时间。选一个现实可行的周期,例如两周、三个月,然后尽量严格执行。
- 设定检查点。定义一些中间里程碑,例如完成数据预处理、训练出一个基线模型,或者达到某个准确率,以便跟踪进展。
- 在结束时做复盘。花点时间总结哪些有效、哪些无效,以及你学到了什么。
提示
time-box 不只适用于整个项目,也适用于项目中的某一小段探索。例如:“我会给这个新的处理或建模想法一周时间;如果一周后没有帮助,我就继续往前走。”
time-box 最大的风险,往往就是你自己。人总是很容易为延期找理由,很容易不断往里塞新想法,也很容易说服自己“只要再试 10 件事,可能就成了”。范围蔓延(scope creep)和完美主义是常见陷阱。这时,找别人聊一聊往往很有帮助,例如合作者、导师或朋友。一个很短的对话,常常就能帮你从犹豫和执念里跳出来,重新看到更大的上下文。
判断你是否真的需要深度学习
这句话出现在一本讲深度学习的书里,听上去也许有点奇怪,但在你真正跳进去之前,先认真问问自己:这个问题到底是不是非深度学习不可?我们再说一遍:请严肃地考虑更简单的方法。
深度学习模型确实强大,而且也确实很有趣。但它们同样资源消耗大、训练复杂、调试困难。在很多场景里,传统方法,例如线性回归、决策树或基础统计方法,就已经足够达到目标,而且投入会小得多。相比之下,这些方法往往:
请认真权衡这些取舍。如果一个更简单的方法已经能给你所需的洞察或性能,那它往往就是更聪明、也更高效的选择。
确保你拥有足够且足够好的数据
深度学习模型需要的,不只是“大量数据”,它们通常还需要“高质量数据”。如果数据本身很差,那么即使模型再复杂,最后也经常会出现灾难性失败。
你至少要确认两件事:
- 数量足够。深度模型通常需要成千上万甚至更多样本。到底多少才算“够”,取决于具体问题与模型架构。你应该参考相关文献中的经验基准。如果你手头的数据集很小,可以考虑迁移学习(transfer learning),也就是从一个相关任务上训练好的模型出发,再在你自己的数据上微调(fine-tune)。这种做法往往能大幅降低你对数据规模的需求。
- 质量足够。干净、一致的数据至关重要。标签错误、噪声和各种不一致,都会严重拖累性能。即便是支撑现代聊天式助手系统的大语言模型,也能从精心筛选的高质量数据中获得巨大收益。因此,请把数据质量检查与有意识的数据整理放在很高优先级。
组建团队
一个人做当然完全可以,但如果能找到合适的人协作,往往能更快推进、产出更好的想法,也会让整个过程更有乐趣。下面是一些寻找优质合作者的小建议:
- 参与社区。加入相关论坛、线上群组或网络研讨会,去认识别人、交流想法,也寻找潜在合作者。Reddit、Discord、X,以及各种专门的 Slack 群组,往往都是不错的起点。
- 参加 hackathon 和比赛。像 Kaggle、Zindi,或者本地大学组织的比赛,都会提供结构化任务、反馈机会,以及认识同类人的可能性。
- 组建跨学科团队。不同领域的专长往往会让项目更强。如果你是生物学背景,就找一个懂机器学习的人;反过来也一样。
- 和领域专家合作。领域专家能帮你更早地界定问题,也更容易指出盲点。你可以在会议、workshop 上找人,也可以直接给相关论文作者发消息。只要你的请求是真诚而明确的,陌生人往往比你想象中更愿意回复。
当你真的找到一起做事的人之后,也有一些事情值得尽早做:
- 及早明确目标与分工。和别人合作时,最好一开始就说清楚:谁负责什么,成功意味着什么,以及决策机制是什么。这样能避免误会,也能让项目持续前进。
- 使用共享协作工具。版本控制(如 Git)、共享 notebook(如 Google Colab),以及简单的任务追踪工具(如 Notion、Trello,或者哪怕只是一个带列表的共享 Google Doc),都会显著改善协作效率。
- 允许分工专业化。让每个人去承担自己最擅长、也最愿意做的部分。有的人更适合基础设施和软件工程,有的人更适合数据整理,有的人更擅长建模或生物学解释。
- 从小项目开始。如果你不确定长期合作是否合适,先一起做个小而轻量的项目或探索。低压力的小协作,是测试默契的很好方式。
无论你是单打独斗,还是和团队一起做,最重要的事都是:保持好奇、持续学习,然后迈出第一步。
你不需要超级计算机,也不需要博士学位
在“生物学中的深度学习”这个方向上,有几个很常见的误解,值得先拆掉:
第一种误解是:你必须有巨额预算和极强算力。
在一个巨型语言模型单次训练就能烧掉几百万美元的时代,人很容易以为自己也必须拥有类似资源。但事情并不总是这样:
- 用小模型先做原型。先从小模型开始,迭代会更快。你可能会发现,一个轻量模型就已经足够达到你的目标。
- 利用免费或相对便宜的算力。Google Colab 和 Kaggle 都为小项目提供免费 GPU。对于更重的工作负载,AWS、Microsoft Azure、Google Cloud Platform(GCP)等云服务也提供可扩展的付费实例。
- 并不是所有事情都和“规模”有关。很多有价值的项目,重点在于分析已有模型,而不是训练全新模型。这类工作往往只需要相对 modest 的算力,却能带来非常深刻的洞察。关于深模型究竟如何工作,我们其实还有很多没搞清楚。
第二种误解是:你必须在机器学习或生物学,甚至两个方向上都拥有非常深的专业背景,才有资格做出有意义的贡献。
现实并非如此:
- 工具越来越好。现代框架让构建和实验强大模型变得比以往容易得多。
- 开源文化非常强。大量自由可得的代码和预训练模型,让你可以直接站在别人的工作之上学习和构建。
- 教育资源非常丰富。现在网上并不缺教程、视频和 walkthrough,足够帮助你快速起步。
- 还有大量未被机器学习探索过的重要生物问题。你不需要博士学位,也不需要 Kaggle 奖牌,才有资格去碰这些问题。
最前沿的研究当然可能需要专门知识和高端基础设施,但这个领域里仍然有大量空间留给好奇心、创造力和新的视角,并不要求你先拥有一台超级计算机。
提示
在探索这个领域时,你几乎一定会接触到学术论文,无论你是在研究某个具体方法、读相关工作,还是寻找项目想法。生物学论文和机器学习论文,刚开始读的时候都可能显得难以进入:语言密度很高,想法被高度压缩,术语也很多。但请记住:
- 你看到的是一个研究团队花了数月甚至数年工作后凝缩出来的结果,而你只是第一次接触它。
- 读论文是一种技能,和其他技能一样,练得多了就会越来越熟。
- 博客文章、YouTube 视频,以及开源项目,也经常是学习同一概念时更易进入的替代入口。
有了这些背景,我们就可以开始进入本书的技术基础部分了。
技术导论
本书会使用基于 Python 的深度学习框架,尤其是 JAX 和 Flax。JAX 是一个面向高性能数值计算与机器学习的系统,而 Flax 是建立在 JAX 之上的灵活神经网络库。我们先解释为什么选择 JAX,再回顾一些在大量机器学习代码里反复出现的 Python 特性。接着,我们会介绍一组全书都会用到的机器学习基础概念,其中最重要的一个,就是训练循环(training loop)是如何组织起来的。
提示
正如“先修要求”里提到的那样,本书默认你已经具备基础 Python 知识。如果你还不熟悉 Python,请先回去看那里推荐的资源。
最后,为了避免后面各章反复复制相同代码,我们还准备了一个小型配套库 dlfb(Deep Learning for Biology),用来封装一些常用工具与组件。后文中我们会不断引用它。
提示
如果这部分技术导论里有些内容你一开始看起来觉得陌生或吃力,也不用紧张。你完全可以先略读,甚至先跳过去。很多概念等你在后面真正看到它们动起来时,会自然清楚得多。
为什么选择 JAX 和 Flax?
全书使用的是 JAX 和 Flax 生态。但当 PyTorch 或 Keras 更常见时,我们为什么做出这个选择?
先坦白一点:并不存在唯一“最好的”框架。它们都可以用来构建有效的生物模型,而本书中的很多概念,也都能很自然地迁移到 PyTorch 或 Keras。
我们主要出于以下原因选择 JAX / Flax:
- 熟悉的 NumPy API。JAX 的
jax.numpy 模块,通常写作 jnp,在数组操作和数学运算上的 API 与标准 NumPy 非常接近,因此很多 np 调用都可以比较直接地替换成 jnp。如果你已经比较熟悉 NumPy,那么迁移到 JAX 的学习曲线会平缓很多,同时还能获得 JAX 的强大变换能力和加速器支持。 - 函数式编程风格更清晰。JAX 强调纯函数(pure function)风格,这有助于减少隐藏状态,让训练逻辑更透明。这一点和本书的教学目标也很契合:显式往往优于隐式。
- 变换能力是一等公民。JAX 提供了强大、可组合的变换,例如
jit(just-in-time 编译)、grad(自动求导)和 vmap(向量化),它们都可以非常干净地作用在 Python 函数上。这些工具统一而简化了模型训练与评估中的许多环节。 - JAX 更贴近前沿研究。JAX 在近年的机器学习研究中获得了越来越多采用,尤其是在生物学、物理学以及大规模模型方向。用它来学习,也更容易接上新一代工具链与实践方式。
- 速度。JAX 使用编译器,在 GPU(如 NVIDIA 或 AMD 显卡)和 TPU(Google 设计)这类专用硬件上,通常能带来显著性能提升,因此很适合大规模深度学习工作负载。这个编译体系建立在 XLA(Accelerated Linear Algebra)之上,后者是一个为加速器优化数值计算的底层系统。
当然,JAX 和 Flax 也有代价:生态更小,API 演化很快,甚至有时会一路改坏一些东西。而且,JAX 能带来的速度优势,也并不是 JAX / Flax 独有。例如 Keras 现在也支持 JAX 后端,这对喜欢更高层 API 的用户来说也是一种选择。如果你本来就已经更熟悉 PyTorch、Keras 或 TensorFlow,你完全可以用它们来实现本书中的想法,甚至欢迎你把自己的版本贡献到本书仓库里。
在刚开始学习时,这不是必须的;但从长期看,熟悉不止一个深度学习框架通常是有帮助的。不同框架在不同生态中各有优势。例如我们在第 2 章里就会使用 PyTorch,从 Hugging Face 模型中提取预训练嵌入,因为 Hugging Face 上的很多模型主要就是以 PyTorch 形式发布和维护的。
警告
深度学习领域变化很快。虽然本书全程使用 Flax 的 linen API,但目前一个新的 API nnx 已逐渐成为官方更推荐的构建方式。linen 依旧是被完整支持的,只是你在其他教程或示例中,很可能会看到 nnx,而它的语法会稍有不同。
本书会在需要时逐步介绍关键的 JAX 概念,但不会系统覆盖整个库。如果你想做更深入、也更偏实战的学习,可以去看官方 JAX 教程。如果你在使用时遇到一些奇怪行为,那么 JAX 的 “sharp bits” notebook 也是极好的参考资料,它专门总结了常见陷阱以及规避方法。
关于性能的一点说明
由于这是一本教学型图书,我们优先追求的是清晰,而不是峰值性能。因此我们不会展开讲解精度调优、高级硬件策略或分布式训练。但在真实环境中,这些事情可能非常重要。
如果你已经对基础比较熟悉,并且想继续深入,下面这些方向很值得进一步探索:
- 数值精度与调优。很多机器学习运算,尤其是矩阵乘法(matmul),都会从
bfloat16 这类低精度格式中受益,在几乎不损害模型精度的前提下显著提升速度并降低内存占用。JAX 允许你通过 jax.default_matmul_precision 控制矩阵乘法所使用的精度,从而更充分地利用如 NVIDIA GPU 上的 Tensor Cores 或 TPU 上的矩阵单元。低精度训练在大规模场景里非常普遍,因为它可以更高效、也更经济地训练更大的模型。 - 分析性能的工具,例如
jax.profiler 或 TensorBoard。性能分析能帮助你定位代码到底把时间和内存花在了哪里,从而找出训练瓶颈,优化最昂贵的操作。 - 节省内存的训练技巧。例如梯度检查点(gradient checkpointing,在 JAX 中叫
remat),它让你用额外计算换取更低内存消耗,从而能在不爆内存的情况下训练更深模型。 - 多主机 / 多设备训练。在多个 GPU、TPU,甚至多台机器之间做训练,能够让你扩展到单设备放不下的模型和数据集。
你不需要掌握这些内容才能读懂本书,但知道它们的存在是很有帮助的;当你对 JAX 生态更熟之后,它们会成为非常值得进一步挖掘的方向。
Python 小贴士
本书不会系统讲 Python 基础,但这一节会重点提醒几个在机器学习代码里,尤其是在 JAX 与 Flax 场景中,非常常见也很实用的 Python 概念。
类型标注与文档字符串
Python 是动态类型语言(dynamically typed language),也就是说你不需要显式声明变量是字符串、整数还是别的类型,类型会在运行时决定。这让语言非常灵活,但也会让 bug 尤其在大代码库中更难提早发现。类型标注(type annotations)可以缓解这个问题,它能提升可读性,支持 mypy 之类的静态类型检查工具,并让调试过程更轻松。
下面是一个简单函数,用来计算两个 NumPy 数组之间的均方误差(mean squared error, MSE):
import numpy as npdef mean_squared_error(y_true, y_pred): squared_errors = (y_true - y_pred) ** 2 return np.mean(squared_errors)
用法如下:
y_true = np.array([1.1, 0.1, 1.0])y_pred = np.array([0.9, 0.2, 1.2])mean_squared_error(y_true, y_pred)
输出:
np.float64(0.030000000000000002)
我们可以通过类型提示与 docstring 改进这个函数,明确指定输入是 np.ndarray,返回值是 float,并说明函数用途:
def mean_squared_error(y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Calculate the Mean Squared Error (MSE) between two NumPy arrays. Args: y_true (np.ndarray): Ground-truth values. y_pred (np.ndarray): Predicted values. """ squared_errors = (y_true - y_pred) ** 2 return np.mean(squared_errors)
这些修改不会改变函数行为,但会带来几个明显好处:
- 明确输入输出类型。你可以一眼看出
y_true 和 y_pred 应该是 NumPy 数组,返回值应为 float。有些机器学习代码会写得更细,比如把数组内部的数据类型也显式标出来,例如 arr: NDArray[np.float64],但本书不会做到这么细。 - 改善文档支持。IDE 和文档工具能提供更好的内联帮助和自动补全,这对生产力提升很明显。
- 提高可读性。无论是别人还是未来的你自己,都会更容易理解这个函数。
- 支持静态检查。像
mypy 这样的工具,可以帮你提前发现类型相关错误。
这个 MSE 例子非常简单,因此加完整类型提示和 docstring 看起来似乎有点“杀鸡用牛刀”,但背后的原则很重要。
由于篇幅限制,本书不会在所有地方都坚持写完整类型和 docstring,但它们绝对是你在自己项目里值得养成的好习惯。即使在正文中出现 docstring,我们通常也会尽量把它压缩成单行版本,这样印刷时也能少砍几棵树。
装饰器
装饰器(decorator)本质上是会修改其他函数或方法行为的函数。在机器学习和数据科学里,装饰器常被用来提升性能、缓存结果,或者记录函数行为。
使用 JAX 做即时编译(JIT)
在 JAX 中,最常见的装饰器之一就是 jax.jit,它会对代码进行 just-in-time compilation,从而提升执行速度。JIT 编译后的函数第一次运行通常会更慢,因为它需要先被编译成 XLA(Accelerated Linear Algebra)机器码;但后续调用通常会快得多。
假设我们有一个函数,它接受一个 JAX 数组,把其中每个值都提升到 10 次方后求和:
import jaximport jax.numpy as jnpdef compute_ten_power_sum(arr: jax.Array) -> float: """Raise values to the power of 10 and then sum.""" return jnp.sum(arr**10)arr = jnp.array([1, 2, 3, 4, 5])compute_ten_power_sum(arr)
输出:
Array(10874275, dtype=int32)
要加速这个函数,有两种方式。第一种是直接包装:
jitted_compute_ten_power_sum = jax.jit(compute_ten_power_sum)jitted_compute_ten_power_sum(arr)
输出:
Array(10874275, dtype=int32)
第二种是利用 Python 的语法糖,在定义函数时直接使用 @jax.jit:
@jax.jitdef compute_ten_power_sum(arr: jax.Array) -> float: """Raise values to the power of 10 and then sum.""" return jnp.sum(arr**10)compute_ten_power_sum(arr)
输出:
Array(10874275, dtype=int32)
三者的输出都一样,但加了 jit 的版本运行速度通常会快很多。如果你在 Jupyter Notebook 中工作,可以用 %timeit 来测量某一行代码的运行时间,或者用 %%timeit 来测整格。你可以自己试试带 @jax.jit 和不带 @jax.jit 的差别。在 GPU 上,你甚至可能看到大约 20 倍左右的加速。
注记
@jax.jit 是怎么工作的?简单说,当你给函数加上 @jax.jit 时,JAX 不会像普通 Python 那样直接执行它。它会先“trace”这段函数,也就是用一些特殊的 tracer 对象,而不是真实数据,把函数走一遍,从而构建出计算图(computation graph)。这个图是对所有数值运算的静态表示,其中控制流会被展开,而变量的形状与类型也会被固定下来。
图构建完成后,JAX 会交给 XLA(Accelerated Linear Algebra)进行编译,生成高度优化的机器码。这个编译结果会被缓存,只要后续再次用“相同输入形状与类型”调用这个函数,JAX 就能直接复用已编译版本,因此带来显著加速。
JIT 编译很强大,但对调试来说也有代价,原因主要包括:
- 像
print() 或 pdb 这样的 Python 调试工具,在被 jit 过的函数里通常不会按你熟悉的方式工作。 - 副作用(例如
print()、日志记录或修改列表)在 tracing 过程中其实不会真正执行,因为 JAX 会跳过所有不影响计算图的内容。 - 报错信息有时会指向 JAX 或 XLA 内部代码,而不是你原始写的函数,因此看起来可能相当晦涩。
虽然你可以通过注释掉 @jax.jit 来暂时关闭 JIT,但如果代码里有很多函数都依赖 JIT,这就很不现实。一个更方便的办法,是通过设置环境变量 JAX_DISABLE_JIT=True 来全局关闭 JIT,让所有被 jit 的函数都按普通方式运行。这样你就能在不重写代码的前提下更方便地调试。更多细节可以参考 JAX 的调试文档。
用 partial 预配置 JAX jit
在机器学习代码里,尤其是 JAX 代码里,partial 的用法经常让人困惑。functools.partial 的本质,是预先填入,或者说“绑定”函数的一部分参数,并返回一个新函数。它是一个通用 Python 工具,并不专属于 JAX 或机器学习。
下面这个例子里,我们改造了 scale 函数,构造出一个新的 scale_by_10:
from functools import partialdef scale(x, scaling_factor): return x * scaling_factor# Create a new function 'scale_by_10' where 'scaling_factor' is fixed to 10.scale_by_10 = partial(scale, scaling_factor=10)scale_by_10(3)
输出:
30
这里的 scale_by_10,就是一个等价于 scale(x, 10) 的新函数。
在 JAX 语境下,partial 还经常被用来“先配置装饰器,再把它应用到函数上”,例如 @partial(jax.jit, static_argnums=...)。这里的作用,是给 jax.jit 自身传参。前面说过,jax.jit 会为你的 Python 函数做编译以换取速度。但有些参数,JAX 需要知道它们是不是静态参数(static arguments)。所谓静态参数,通常是那些不是 JAX 数组的对象,例如整数、字符串、布尔值,它们会影响计算的结构,例如决定某个 if/else 走哪条分支。如果静态参数变了,JAX 往往就得重新编译函数。
假设我们想计算一个数组的汇总统计量,根据字符串参数 average_method 的不同,选择求均值或中位数。由于这个选择会影响控制流,因此 JAX 需要在编译时就知道 average_method 的具体取值:
from functools import partialimport jaximport jax.numpy as jnp@partial(jax.jit, static_argnums=(0,))def summarize(average_method: str, x: jax.Array) -> float: if average_method == "mean": return jnp.mean(x) elif average_method == "median": return jnp.median(x) else: raise ValueError(f"Unsupported average type: {average_method}")data_array = jnp.array([1.0, 2.0, 100.0])# JAX compiles one version of 'summarize' for average_method="mean".print(f"Mean: {summarize('mean', data_array)}")# JAX compiles another version for average_method="median".print(f"Median: {summarize('median', data_array)}")# Calling with "mean" again uses the cached compiled version.print(f"Mean again: {summarize('mean', data_array)}")
输出:
Mean: 34.333335876464844Median: 2.0Mean again: 34.333335876464844
如果我们没有通过 static_argnums=(0,) 把 average_method 标成静态参数,JAX 就会报错,因为它无法 trace 依赖字符串的控制流,除非它在编译前就已经知道这个字符串的值。把参数标成静态,意味着你是在告诉 JAX:对于这个静态参数遇到的每个唯一取值,都分别编译一个专门版本的函数。
提示
这里顺便澄清一下 “static” 和 “dynamic” 的区别:JAX 会把大多数数值输入,例如 jax.Array、float 或 int,视为动态输入(dynamic)。只要它们的形状与类型不变,它们的具体数值在不同调用间变化,都不需要重新编译。
而像字符串、Python 对象或函数这类输入,则通常被视为静态输入(static),因为它们会影响控制流,或者本身无法被纳入计算图 trace。如果你把它们传进 jitted 函数里,要么用 static_argnums 显式标记为静态,要么通过闭包(closure)的方式把它们包进去,下一节就会看到这种写法。
闭包
闭包(closure)是指一个函数“记住了”它被创建时所在的外部环境。也就是说,即使外部函数已经执行结束,内部函数仍然可以访问那个外部作用域中的变量:
def outer_function(x): def inner_function(y): return x + y # inner_function "closes over" x. return inner_functionadd_five = outer_function(5) # x is 5.result = add_five(10) # y is 10.print(f"Closure result: {result}")
输出:
Closure result: 15
在这个例子里,add_five 就是一个闭包。它“记住了”调用 outer_function 时 x 等于 5。
闭包在基于 JAX 的机器学习代码里非常常见。很多组件,例如损失函数、正则项和数据增强流程,都会依赖某些配置值。与其把这些值作为参数显式传来传去,并在控制流里额外处理 static_argnums,很多时候人们更愿意把它们直接闭包进去。稍后定义 JAX 训练循环时,你就会看到实际例子。
生成器
生成器(generator)是一类可以惰性迭代数据的函数,它每次只产出一个元素。这对大数据集非常有用,因为你通常既不想,也不可能一次性把所有数据都加载进内存(RAM)。
下面是一个简单生成器,用来模拟按批次流式提供数据:
from typing import Iteratordef data_generator() -> Iterator[dict]: """Yield data samples with features and labels.""" for i in range(5): yield {"feature": i, "label": i % 2}# Example usage.generator = data_generator()next(generator)
输出:
{'feature': 0, 'label': 0}
本书后面有些章节会使用 TensorFlow datasets(TFDS)。由于 JAX 自身并不提供原生的数据加载库,因此你经常会看到它和 TFDS 组合使用。如果你的数据已经在 NumPy 数组里,那么可以非常方便地用 tf.data.Dataset.from_tensor_slices 把它们转成 TensorFlow dataset。这样就能把 NumPy 数据接入 TensorFlow 的数据管线,用它来做高效训练和预处理。它还提供了非常干净的 API,便于做 batching、shuffling 和 prefetching(在真正需要之前预先加载数据,以提升训练速度),对于入门来说很友好:
import tensorflow as tffeatures = np.array([1, 2, 3, 4, 5])labels = np.array([0, 1, 0, 1, 0])# Create a TensorFlow dataset from the NumPy arrays.dataset = tf.data.Dataset.from_tensor_slices((features, labels))# Batch dataset with batch size of 2 and drop the final batch if incomplete.batched_dataset = dataset.batch(2, drop_remainder=True)# Create a dataset (ds) iterator and retrieve the first batch using next().ds = iter(batched_dataset)next(ds)
输出:
(<tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 2])>, <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>)
后续章节里,我们也会自己写一些更可控的定制化数据管线。
JAX/Flax 训练循环剖析
虽然不同机器学习项目的细节会有很大差异,但模型训练的核心结构其实相当稳定。这个核心结构会成为全书后续各章的基础。现在,我们一步步走过一个使用 JAX 与 Flax 训练模型的基本骨架,你后面看到更复杂示例时,都可以把它们理解为在这个模式上不断叠加。
定义数据集
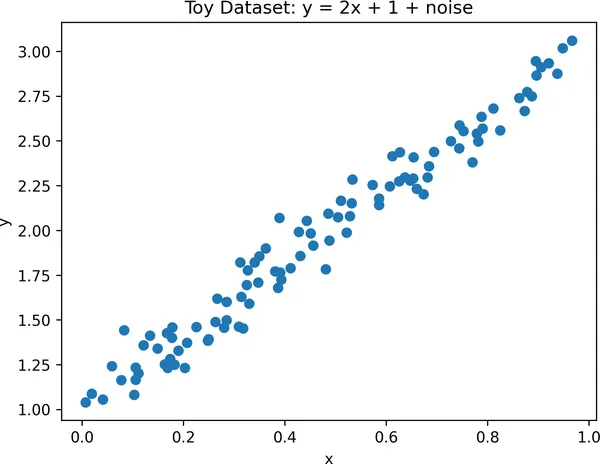
先造一份玩具数据。这里令目标值 y 是 x 的一个线性变换,并额外加入一点随机噪声。我们使用的真实关系是 y = 2x + 1,再加上高斯噪声,如图 1-1 所示。
import jaximport jax.numpy as jnpimport matplotlib.pyplot as pltfrom flax import linen as nn# In JAX, randomness is handled explicitly by passing a random key.# We create a key here to seed the random number generator.rng = jax.random.PRNGKey(42)# Generate toy data: x values uniformly sampled between 0 and 1.rng, rng_data, rng_noise = jax.random.split(rng, 3)x_data = jax.random.uniform(rng_data, shape=(100, 1))# Add Gaussian noise.noise = 0.1 * jax.random.normal(rng_noise, shape=(100, 1))# Define target: y = 2x + 1 + noise.y_data = 2 * x_data + 1 + noise# Visualize the noisy linear relationship.plt.scatter(x_data, y_data)plt.xlabel("x")plt.ylabel("y")plt.title("Toy Dataset: y = 2x + 1 + noise")plt.show()
图 1-1. 这张散点图展示了我们希望模型学到的底层关系。
定义模型
在 Flax 中,我们通过继承 nn.Module 来定义模型。@nn.compact 装饰器允许我们直接在 __call__ 方法里定义层,而不是放到类的 setup() 方法中。对于简单的串行模型,这样写尤其方便。
下面是一个最小示例:只包含一个线性层(dense layer),输出单元数为 1,并且没有激活函数。
class LinearModel(nn.Module): @nn.compact def __call__(self, x): # Applies a single dense (fully connected) layer with 1 output neuron. # That is, it computes y = xW + b, where the output has dimension 1. return nn.Dense(features=1)(x)
实例化模型的方法如下:
model = LinearModel()
要初始化模型参数,需要调用 .init 方法,并传入一个随机 key 和一个示例输入。这样 Flax 就能自动推断输入与输出形状。这里我们传入一个形状为 [1, 1] 的虚拟输入,也就是 1 个样本(batch size 为 1),每个样本 1 个输入特征,这与我们的玩具数据形状一致:
rng = jax.random.PRNGKey(42)variables = model.init(rng, jnp.ones([1, 1]))
这样就完成了参数初始化。结果是一个字典,其中包含 dense 层的权重和偏置:
print_short_dict(variables)
输出:
{'params': {'Dense_0': {'kernel': Array([[-0.5220277]], dtype=float32), 'bias':Array([0.], dtype=float32)}}}
这里:
kernel 是学习得到的权重矩阵。由于我们的输入和输出维度都是 1,因此它的形状是 [1, 1]。bias
值得注意的是,虽然 Flax 的 API 多年来一直在变化,但核心思想其实很稳定:定义模型层、初始化参数,并通过输入推断形状。更进一步说,即便具体语法未来继续变化,这些基本原则也几乎适用于任何深度学习框架。
注记
为什么 Flax 要通过输入来推断形状?因为在 Flax 里,模型权重和偏置参数的形状,在你真正把数据送进模型之前,其实是未知的。这是 Flax 函数式风格的一部分:你在定义层时,它不会顺便把输入形状也存下来。相反,你需要在初始化时提供一个示例输入,让 Flax 即时推断所需参数形状。
其他库,例如 PyTorch 或 Keras,更多采用面向对象风格,层往往会在内部记住输入形状,这会让模型构建过程显得更自动。但 Flax 的方式会给你更多控制力,也让模型行为在配合 JAX 的 JIT 编译时,更容易被检查和调试。
创建训练状态
在 Flax 中,训练状态(training state)是一个容器,把训练所需的一切东西放在一起:模型参数、优化器,以及用于应用模型的函数。我们来构建一个:
import optaxfrom flax.training import train_state# Define an optimizer — here we use Adam with a learning rate of 1.0.# (Note: in most real settings you'd use a smaller learning rate like 1e-3).tx = optax.adam(1.0)# Create the training state.state = train_state.TrainState.create( apply_fn=model.apply, # The model's forward pass function. params=variables["params"], # The initialized model parameters. tx=tx, # The optimizer.)
TrainState 的设计目标,是让 Flax 中的训练过程更整洁、更易管理。它会统一持有模型更新所需的核心内容:
paramstx:优化器,这里是 Adam。tx 是 transformation 的缩写。在 Optax,也就是 JAX 的优化库里,优化器本质上都被定义为“对梯度进行变换的规则”。例如 Adam 会结合动量(momentum)和自适应缩放,对原始梯度进行变换。apply_fn:执行模型前向传播(forward pass)的函数。
很重要的一点是:训练状态是不可变的(immutable)。我们不会就地修改它,而是在每次更新后返回一个新的 TrainState,其中包含更新后的参数。这种函数式风格和 JAX 的整体设计完全一致,也使得计算过程更纯净、更易追踪。
提示
虽然 TrainState 是不可变的,每次更新都会返回一个新对象,但这并不会导致内存问题。JAX 会非常高效地复用内存,尤其是在 @jit 编译过的函数内部。
定义损失函数
损失函数(loss function)用来衡量模型预测和真实目标之间的差距。这里我们使用 MSE,这在回归任务中非常常见:
def calculate_loss(params, x, y): # Run a forward pass of the model to get predictions. predictions = model.apply({"params": params}, x) # Compute MSE loss. return jnp.mean((predictions - y) ** 2)
这里之所以能直接调用 model.apply,是因为 model 已经在前面定义过,并且仍然处于当前作用域中,例如同一个 notebook 或脚本里。我们不需要把它再显式作为参数传入,因为这个函数依旧是“纯”的,模型状态全部都来自我们传进去的 params。
下面是调用方式:
loss = calculate_loss(variables["params"], x_data, y_data)print(f"Loss: {loss:.4f}")
输出:
Loss: 5.2768
这一步会使用当前模型参数对数据进行一次前向计算,并算出损失。由于此时模型参数还是随机初始化出来的,损失比较高完全正常。随着训练进行,这个值应该逐步下降,而这就意味着模型正在更好地从输入预测目标。
定义训练步骤
训练步骤(training step)负责完成一次完整更新:前向传播、计算损失和梯度、再更新模型参数。这里我们使用 jax.jit 对整个步骤进行编译,以提升效率。虽然 JAX 本身就可以在 GPU 和 TPU 上运行,但显式使用 jit 能确保代码被编译成单个优化后的计算图,从而真正吃满加速器硬件带来的速度。
@jax.jitdef train_step(state, x, y): # Compute the loss and its gradients with respect to the parameters. loss, grads = jax.value_and_grad(calculate_loss)(state.params, x, y) # Apply gradient updates. new_state = state.apply_gradients(grads=grads) return new_state, loss
很多时候,你不只是想要梯度来更新参数,你还想显式拿到损失值,方便记录日志,例如画出损失曲线。但由于求梯度本来就必须先算一次损失,如果分开做,就会有重复计算。jax.value_and_grad 正好就是为这件事准备的便捷工具,它会一次性完成两件事:
- 先执行你给它的函数,这里是
calculate_loss,得到损失值。
这样就避免了重复计算。
我们的 train_step 最终会返回一个新的 TrainState,其中参数已经更新过了,同时也返回当前损失,供我们观察训练进展。
你也会经常看到另一种写法:在 train_step 内部用闭包定义损失函数,例如:
@jax.jitdef train_step(state, x, y): def calculate_loss(params): # state, x and y are not part of the function signature but are accessed. predictions = state.apply_fn({"params": params}, x) return jnp.mean((predictions - y) ** 2) loss, grads = jax.value_and_grad(calculate_loss)(state.params) state = state.apply_gradients(grads=grads) return state, loss
在这里,state、x 和 y 都是通过闭包访问的。它们没有出现在 calculate_loss 的函数签名里,因此代码会更紧凑一些,也往往更易读。
在损失函数中处理辅助输出
顺带一提,这类需求在实际中非常常见:有时我们希望损失函数除了返回 loss,还额外返回一些信息,例如预测值或日志指标,但这些额外输出不应该参与梯度计算。JAX 用 has_aux=True 很轻松就支持了这种需求。它会告诉 value_and_grad:损失函数返回的“第一个值”才是真正要微分的 loss,其余内容都只是 auxiliary outputs,不参与梯度。
例如,我们可以让损失函数同时返回预测值,并在 train_step 中用 has_aux=True 配合处理:
@jax.jitdef train_step(state, x, y): def calculate_loss(params): predictions = state.apply_fn({"params": params}, x) loss = jnp.mean((predictions - y) ** 2) return loss, predictions # Return both loss and preds (aux info). (loss, predictions), grads = jax.value_and_grad(calculate_loss, has_aux=True)( state.params ) state = state.apply_gradients(grads=grads) return state, (loss, predictions)
如果不加 has_aux=True,JAX 默认会认为损失函数只能返回一个标量 loss。只要你再额外返回别的内容,例如预测值,它就会直接报错。加上 has_aux=True 后,你就是在明确告诉 JAX:“只对 loss 求导,其余输出,比如 predictions,都不要参与微分。”
定义训练循环
现在,所有零件都已经就位了,我们终于可以写出真正会根据数据更新参数的训练循环。
在大多数机器学习工作流中,训练是按 step 或 epoch 组织的:
- step 指的是使用一批数据(一个 batch)对模型做一次更新。
- epoch 指的是完整遍历整个训练集一次,而一个 epoch 往往包含很多个 step。
在这个玩具例子中,我们一次性把整份数据,也就是 100 对输入输出样本,全都喂给模型,没有做 batching。因此,这里的每一个 step 实际上就等价于一个完整 epoch。更真实的场景里,你通常会把数据拆成很多 batch,于是每个 epoch 会包含多个 step。
现在开始真正训练:
num_epochs = 150 # Number of full passes through the training data.for epoch in range(num_epochs): state, (loss, _) = train_step(state, x_data, y_data) if epoch % 10 == 0: print(f"Epoch {epoch}, Loss: {loss:.4f}")
输出:
Epoch 0, Loss: 5.2768Epoch 10, Loss: 0.9498Epoch 20, Loss: 0.1091Epoch 30, Loss: 0.0845Epoch 40, Loss: 0.0283Epoch 50, Loss: 0.0258Epoch 60, Loss: 0.0106Epoch 70, Loss: 0.0105Epoch 80, Loss: 0.0106Epoch 90, Loss: 0.0102Epoch 100, Loss: 0.0101Epoch 110, Loss: 0.0100Epoch 120, Loss: 0.0100Epoch 130, Loss: 0.0100Epoch 140, Loss: 0.0100
可以看到,模型收敛得很快,损失迅速降到一个稳定而较低的水平。训练结束后,我们可以把模型预测值和真实目标值做对比,看看它对底层规律学得怎么样,如图 1-2 所示:
# Generate test data (x values between 0 and 1).x_test = jnp.linspace(0, 1, 10).reshape(-1, 1)y_test = 2 * x_test + 1 # Ground truth: linear function without noise.# Get model predictions.y_pred = state.apply_fn({"params": state.params}, x_test)plt.scatter(x_test, y_test, label="True values")plt.plot(x_test, y_pred, color="red", label="Model predictions")plt.xlabel("x")plt.ylabel("y")plt.legend()plt.title("Linear Model Predictions vs. True Relationship")plt.show()
图 1-2. 线性模型预测值与真实值对比的散点图。
我们可以看到,训练完成后,模型已经非常接近地学会了真实函数 y = 2x + 1。预测输出和理论值几乎重合,而这正是我们在这个玩具回归任务中想看到的结果。
这个例子虽然简单,却抓住了几乎所有深度学习工作流的核心结构:定义模型,计算损失,更新参数,然后重复。真实项目当然会更复杂,还会涉及 batching、数据管线、正则化(regularization)、指标、日志等等,但你现在搭起来的这个基础循环,就是一切的地基。你现在已经有了一个关于 JAX 与 Flax 如何完成训练的清晰心智模型,也有了继续构建更强系统的起点。
提示
下一步该往哪里走?当你已经搭出一个能工作的训练循环时,这其实是一个非常重要的里程碑。接下来常见的扩展方向包括:加入能刻画关键性能特征的指标,额外切出验证集来检查泛化能力,以及持续跟踪训练过程中的进展。这些都是现实深度学习工作流中的标准构件,后面的章节里我们会一步步带你做。
机器学习小贴士
下面快速回顾几个本书会反复用到的机器学习概念。后续每当它们真正出现时,我们还会按需更详细展开。
任务类型
在分类任务(classification)中,模型要预测一个标签,或者输出一个标签分布。分类大体可以分成三类:
- 二分类(binary classification):在两个选项中做判断,例如判断一个细胞是否健康。
- 多分类(multiclass classification):从多个标签中选出唯一一个。例如根据生物样本中的模式,预测它来自身体的哪个部位,例如脑、肝或皮肤。每个样本只能属于一个类别。
- 多标签分类(multilabel classification):模型需要选出所有适用标签,而不是只选一个。例如分析细胞图像时,模型可能要判断图中是否可见细胞核、细胞膜和线粒体。此时同一张图像上可以同时有多个标签为真。
回归(regression)则是预测一个连续数值,例如两个分子之间的结合强度。
本书也会用到表征学习(representation learning),也就是在没有直接监督信号的前提下,学习有用的嵌入(embedding)或特征表示(feature representation)。这些嵌入可以捕捉数据中的模式与结构,随后可被用于聚类、可视化,或者作为下游模型的输入。
架构类型
本书主要会用到以下几类模型架构:
- 线性模型与多层感知机(multilayer perceptron, MLP)。它们是全连接网络,通过多层 dense layer 把输入向量映射到输出向量。简单,而且非常常用。
- 卷积神经网络(convolutional neural network, CNN)。CNN 通过空间滤波器建模局部结构,通常用于把图像映射到图像或特征图(feature map)。它们对图像和序列数据都非常有效。
- Transformer。它通过注意力机制(attention)来建模序列中的长距离依赖,能够处理集合或序列,如今在许多生物学任务和语言建模任务中都处于 state of the art。
- 图神经网络(graph neural network, GNN)。它直接在图结构数据上工作,通过节点与邻居之间传递消息来学习表示。当数据具有关系结构或交互结构时,这类模型尤其有用。
- 自编码器(autoencoder)。它通过把输入编码到潜在空间(latent space)再重建回来,来学习紧凑表示。这类模型常见于无监督学习和去噪任务。
这些架构在后文真正出现时,我们都会逐步解释。
归纳偏置
现代深度学习架构已经越来越成熟了。与其总想着“发明下一个 transformer”,很多时候你会发现:更有效的路径,是在已有构件之上做有意识的组合,并让这种组合受到领域知识引导。
你应该认真思考:对你的问题而言,哪些归纳偏置(inductive bias,也就是对数据结构的先验假设)是合理的?例如:相邻数据点之间是否天然有关联,像图像中的像素那样?数据是否有顺序结构,像 DNA 或文本那样?实体之间是否像图那样以关系相连?这些结构性假设会缩小模型要搜索的函数空间,因此通常能让学习更高效。
归纳偏置中很常见的一种,是不变性(invariance),也就是模型假设某些变换不应该改变输出。例如:
- CNN 假设平移不变性(translation invariance):图像轻微平移不应该改变预测结果。
- GNN 假设置换不变性(permutation invariance):图中节点的排列顺序不应该影响输出。
- Transformer 默认也是置换不变的:如果你不给它额外加入位置编码(positional encoding),它本身并不会关心输入顺序。这给了它灵活性,但也意味着:如果任务里存在顺序结构,你必须自己把这种结构编码进去。
数据集切分
机器学习模型通常会使用三部分数据:
- 训练集(training set):用来最小化损失函数、拟合模型参数,也就是模型权重。
- 验证集(validation set):用来调超参数,并在开发过程中评估模型表现。
- 测试集(test set):一直留到最后才使用,用于评估模型在真正未见数据上的最终性能,从而估计它的泛化能力。
这种切分结构之所以是好实践,是因为它能帮助你更可靠地判断模型是否真的能泛化到新数据,也能让你对它在真实世界中的表现有一个更可信的估计。
超参数
超参数(hyperparameters)控制的是“模型如何被训练”,它们在训练开始前就设定好,并不会由优化器自动更新。常见例子包括:
- 学习率(learning rate):模型更新权重的速度有多快。
- batch 大小(batch size):一次更新中一起处理多少个样本。
- 模型大小(model size):层数、隐藏单元数、注意力头数等。
- 正则化(regularization):例如 dropout rate 或 weight decay,用来防止过拟合。
不同超参数组合之间的优劣,通常通过验证集性能来比较。如果你只根据训练集表现来调超参数,那么很容易过拟合,也就是模型只是记住了训练数据,甚至连噪声和异常点也一起记住了。
过拟合会导致模型在新数据上表现变差。与之相对,泛化(generalization)指的是模型学到的规律能超出训练样本本身,在新样本上继续成立。这一点在生物学应用中尤其关键,因为测试数据往往来自不同实验条件、不同实验批次,甚至不同研究环境。
激活函数
激活函数(activation function)为神经网络引入非线性(nonlinearity),从而使网络能够表达复杂的输入输出关系。
当数据流过模型时,它会被变换成一系列中间张量,这些中间张量叫作激活值(activations)。这些激活值会在每一层先经过线性投影,再经过非线性激活函数。最后一个隐藏层的输出,通常还会再接一个最终激活函数,从而生成模型最终预测结果。
最终激活函数的选择非常重要,因为它应该反映你要预测的数据类型。例如:
- 二分类任务通常使用
sigmoid,因为输出应该落在 0 到 1 之间。 - 多分类任务通常使用
softmax,因为输出需要表示不同类别之间的概率分布。 - 如果你的损失函数希望接收原始 logits,例如
sigmoid_cross_entropy 或 softmax_cross_entropy,那就不要手动额外加最终激活函数。这些损失函数会在内部自行应用激活,重复加一次反而可能有害。 - 如果你要预测的是可以为负的实数值,请避免把
ReLU 或 GELU 作为最终激活函数,因为它们会裁掉或扭曲负值。 - 对于回归任务,通常最好的选择就是“不加最终激活”;只有当你明确知道目标值有边界,例如一定落在
-1 到 1 或 0 到 1 之间时,才考虑使用 tanh 或 sigmoid。
如果你拿不准,最稳妥的方法就是先看清目标值的取值范围,再选择一个能让模型输出落在这个范围内的激活函数,或者干脆不加。术语 logits 通常指最终层在 softmax 或 sigmoid 之前的原始未归一化输出,不过这个词本身也有点 overloaded,有时人们会更宽松地把它用于其他类似场景,例如 Transformer 中送进 softmax 之前的 attention scores。
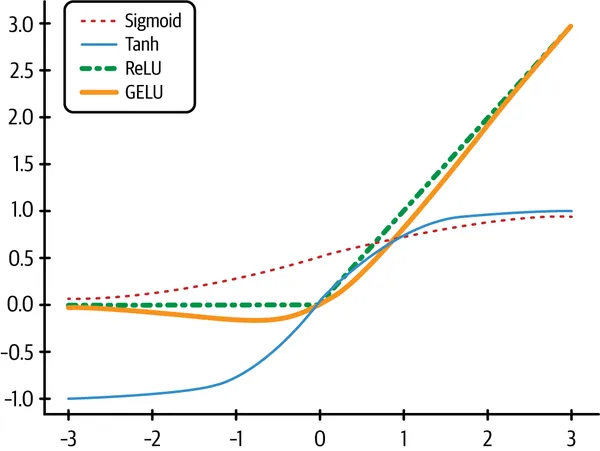
下面列出了最常见的几种激活函数,其形状见图 1-3:
图 1-3. 深度学习中常见的激活函数。
对这些常见激活函数,再补充一点说明:
- ReLU(rectified linear unit):对负输入输出
0,对正输入保持原值。它简单而有效,尤其适用于深层网络。 - GELU(Gaussian error linear unit):可以理解成比 ReLU 更平滑的一种替代方案,在 Transformer 模型中非常常见,有时会带来略好的结果。
- sigmoid 与 tanh:这两者属于较早期的激活函数,会把数值压缩到固定区间。sigmoid 把输入映射到
0 到 1,tanh 则映射到 -1 到 1。它们在某些特定场景下仍然有价值,例如二分类输出层,但在更深网络中容易受到梯度问题影响。 - softmax:把一个向量转换成一个和为
1 的概率分布,通常用于多分类模型的最后一层。它不是逐元素应用的,而是对整个向量一起操作。
在本书中,隐藏层通常会优先使用 ReLU 或 GELU,而最终激活函数则根据具体预测任务来选。
优化器
优化器(optimizer)是一类在训练过程中调整模型参数,也就是权重和偏置,以减少误差(loss)的算法。它们通常通过梯度下降(gradient descent)来工作:先计算每个参数对损失的影响,再沿着能降低误差的方向更新参数。
本书最常使用的优化器是 Adam。它是一个广泛使用的优化器,会对每个参数自适应调整学习率,同时结合动量(momentum)和 RMSProp 的思想。在噪声较大或梯度较稀疏的场景里,它通常比朴素梯度下降更快也更稳。
初始化策略
在训练开始之前,我们需要先给模型参数设置初始值。这个步骤比听起来重要得多。糟糕的初始化会让梯度消失或爆炸,从而导致训练不稳定。
我们通常使用 Xavier(Glorot)初始化,因为它的设计目标就是让层与层之间的激活值和梯度尺度尽量保持稳定,从而让训练过程更平滑。Flax 默认对 Dense、Conv 这类层就会使用 Xavier 初始化,因此多数情况下你不需要手动指定。
模型检查点
在训练过程中,定期保存模型参数通常很有帮助,这样你既能中断后继续训练,也能避免进度意外丢失。真实生产训练流水线往往会使用更完整的 checkpointing 策略,例如只保留表现最佳的检查点、保留版本历史等等,但对于本书里的教学示例来说,没有必要把复杂度拉得那么高。相反,我们提供的是一个轻量工具:只保存与恢复最近一次检查点。这样已经足够用来暂停和恢复训练,或者保留最终模型以供后续使用。后面的不少章节里,你都会看到它,因为这样能减少大量样板代码,让实验流程更简洁。
如果你是在为生产或正式研究项目构建训练循环,那么可以考虑升级到更完整的 checkpointing 方案,例如 Flax 较新的检查点系统 Orbax。
提前停止
在真实训练中,当验证集性能停止提升时,通常就应该及时停下来。这就是提前停止(early stopping)。它既能防止过拟合,也能节省算力。
本书中,我们经常会展示更长的训练过程,以便观察损失随时间的变化。但在你自己的项目里,实际训练时通常都会更倾向于加入提前停止。
Flax 自带了一个很简单的工具:
from flax.training.early_stopping import EarlyStopping
你可以持续监控验证集指标,并在若干 step 内不再提升时停止训练,这里的等待步数通常由 patience 参数控制。
选择工作环境
训练大型神经网络通常会明显受益于 GPU 加速。至于如何获得 GPU,要看你的预算、目标和技术舒适区。
一种选择,是在本地使用带 GPU 的机器,例如游戏台式机或自己搭建的工作站。这样你拥有完全控制权,也不会持续产生云成本,但需要前期硬件投入和环境搭建。
另一种选择,是从 AWS、GCP 或 Azure 这类云服务商租用 GPU。它们提供很强的灵活性和可扩展性,但随着训练规模变大,长期成本也会迅速上升。
对于很多初学者和小项目来说,Google Colab 是非常好的起点。它提供基于云端的 Jupyter notebook,并支持 GPU 或 TPU,同时几乎不需要任何额外配置。
下面几节里,我们会快速带你过一遍这些选择,从交互式 notebook 到更加定制化的 GPU 开发环境。
选择交互式 Notebook
Jupyter notebook 是交互式编码中非常流行、也非常强大的工具,因此特别适合运行本书中的代码示例。你可以在同一个地方写代码、按单元执行、可视化结果,并记录过程。这种交互性非常适合快速实验、调试和迭代。常见 notebook 环境包括 JupyterLab、带 Jupyter 扩展的 VSCode,以及 Google Colab。
尤其是 Google Colab,它提供基于浏览器的云端 notebook,并且附带免费 GPU 和 TPU 访问权限。如果你本地没有足够强的机器,它会是一个极好的起点。Colab 完全运行在浏览器里,除了一个 Google 账号之外,你几乎不需要额外做任何准备。你可以通过类似 !pip install jax flax optax 的命令安装库,也可以把 notebook 直接保存到 Google Drive。若要启用硬件加速,可以进入 Runtime 菜单,从下拉选项中选择 “Change runtime type”,然后再选择 GPU 或 TPU。
本书中的所有代码都会提供为 Google Colab notebook,方便你直接打开、运行和修改。
警告
Colab 会在长时间无操作后自动断开,因此请记得频繁保存你的工作。
不过,虽然 notebook 非常适合探索与原型验证,它们在版本控制、调试以及长期维护复杂项目时,往往会开始显得笨重。对于更长期的工作,搭建一个带 GPU 支持的专用开发环境,通常会给你更多控制力、可扩展性和可复现性。
为复用和调试组织代码
Notebook 很适合交互式尝试,但当你开始真正构建自己的项目时,越早思考代码结构越好。把代码组织成清晰、可复用的 Python 模块,例如数据集一个模块、模型一个模块、指标与评估一个模块。把这些部分分开,会让你的代码更容易调试、更容易扩展,也更容易在未来复用。
本书整体结构其实也在暗暗示范这种模块化思路。每章中的每个小节,通常都会专注于某一个明确构件,例如数据集、模型、训练循环等等。你在跟着书走的时候,也可以尝试把自己的代码组织成这种形态。把组件写干净,让它们可以被你以后继续拼装到新的项目里,你下一次做项目时自然就会更快。
尤其是一个写得好的 dataset class,会极大帮助你早期排错。项目中本来就有很多可能让人困惑的地方;如果你能确保数据集与指标模块既清晰分离,又易于检查,那么至少在排错时,你就能更快把它们排除在嫌疑之外。
提示
请频繁加 sanity checks。比如:
- 你的模型能不能在一个极小数据集上过拟合,例如 10 个样本?
- 当你打乱标签时,loss 和 accuracy 的行为是否符合预期?
还有一个非常实用的原则:能画的都尽量画出来。预测结果、损失曲线、输入样本,这些可视化常常会比最终一两个数字更早暴露问题,例如目标值整体错位、标签标错、张量为空,或者模型根本什么都没学到。
搭建 GPU 开发环境
随着模型逐渐复杂,你可能会想从 notebook 迁移到更强的 GPU 环境中,无论是在本地,还是在云上。一个可靠的开发环境能显著加快实验速度、简化调试过程,也会让整个流程更可复现。
如果是本地开发,我们推荐这样搭配:
- 使用 Docker 配合 NVIDIA Docker,创建能够无缝访问 GPU 的容器化环境。
- 再搭配类似 VSCode 这样的编辑器,它对 Docker 和远程开发支持都很好,工作流会更顺。
- 使用 Git 做版本控制,用来追踪改动、协作以及备份工作。
使用 Apple Silicon 的 Mac 用户,可以尝试 jax-metal,借助 Apple 的 Metal 后端获得 GPU 加速。不过它仍在快速演进中,并不是所有功能都已经完全支持,因此偶尔遇到兼容性问题是正常的。
提示
如果你没有本地 GPU,也可以使用 AWS、GCP、Azure 这类按需付费的云服务。对于规模更小的项目,Paperspace、Lambda Labs 或 RunPod 这类选择,往往提供更简单的配置流程,也可能更划算。
版本冲突
机器学习与科学计算库的演化速度非常快,而且经常不同步。你几乎迟早会遇到 NumPy、JAX、Flax、PyTorch,或者 Hugging Face Transformers 之间的版本冲突。一个比较健康的原则是:尽量使用足够新、能享受到改进的版本,但也不要新到把整个生态兼容性一起撞碎。
像 uv 这样的工具,可以在很多时候帮你越过兼容性问题。它是 pip 更快也更灵活的替代方案,即使某些包的元数据声称彼此不兼容,它有时也能帮你装起来。它当然不是永久解法,但往往能让你先继续工作,不至于完全卡死。
如果你不是在 notebook 里工作,请始终使用虚拟环境,例如 venv、conda 或 uv venv,把依赖隔离开。另一种方式,是直接把环境写进 Docker 容器里,从而获得跨机器的完整可复现性。尤其当你在远程 GPU 实例或云环境中工作时,这种方式会非常有价值,书后面还会再次提到。
如果你不确定出了什么问题,就去翻 GitHub issues 或论坛。版本不匹配是大家共同的痛点,至少在精神上你绝不会孤单。
如果你是在 notebook 里工作,版本问题往往更棘手。以 Google Colab 为例,它预装了很多包,但这些包未必足够新,也未必和最新 JAX / Flax 栈兼容。你可以直接在单元格里用 !pip install 安装或覆盖某些版本,但修改后往往还需要重启 runtime 才会真正生效,也就是 Runtime > Restart runtime。
一份持续演化的文档
本书当然努力去捕捉写作时这个领域的状态,但深度学习和生物学都仍然是快速变化中的前沿。印刷书是静态产物,而框架会变,API 会断,新想法也会不断涌现。
注记
我们已经尽力让示例具备尽可能长的有效期,并在可能发生破坏性变化的地方提前提醒你,例如 Flax 从 linen 向 nnx 的迁移。但随着时间推移,仍然可能出现一些不一致。如果你发现内容已经过时,或者你有修正、改进、建议与扩展,欢迎告诉我们。即便纸书是固定的,在线仓库仍然可以持续演化。
我们也鼓励你把视野放到这些页面之外。像 D2L.ai、fast.ai、JAX 生态,以及 bioRxiv、arXiv 上的预印本,都是继续深入的极好资源。
最重要的是:去实验,去构建,去搞坏一些东西,去训练一些糟糕模型,然后从中学习。在生物学中的深度学习这条路上,最好的成长方式,始终是亲手把手弄脏。
━━ END ━━