【学习笔记】Harness | 大道至简,1 Tool + 1 Loop = 1 Agent —— -Claude-Code实战(2/13)
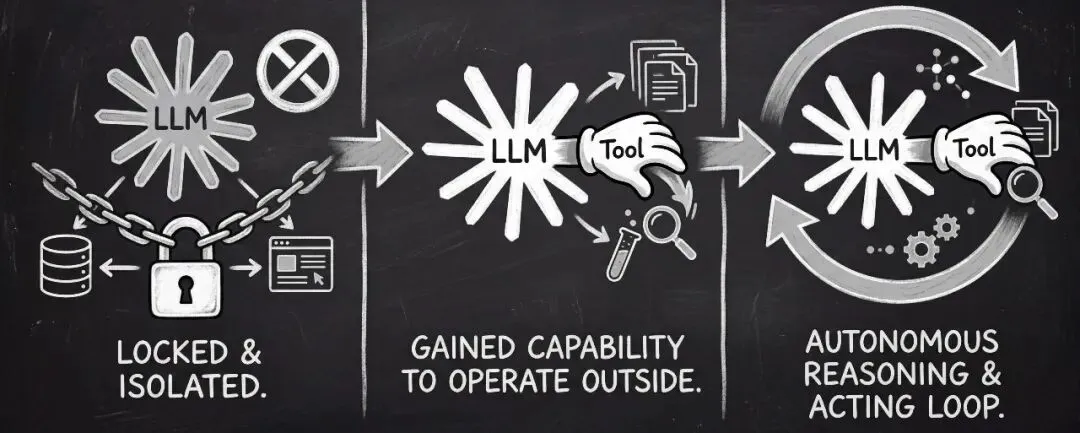
LLM 可以理解代码逻辑,但它没法直接操作外界的东西,例如读文件、跑测试等。
工具调用就像是给 LLM 装了个手 ,让它能和外界互动。
,让它能和外界互动。
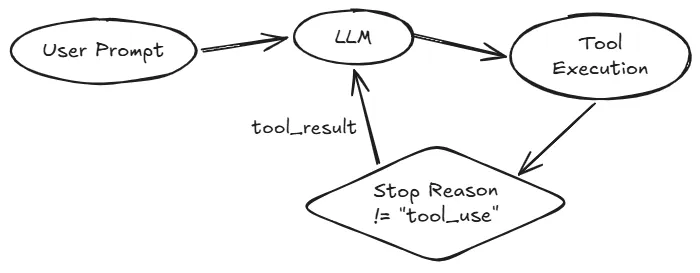
但仅有手还不够,如果没有自动循环机制,每次调用工具后,都得你手动把结果复制粘贴回去,这肯定不行🙅,所以还需要一个自动循环♻,如下图所示。
这个循环会一直运行,直到模型停止调用工具。
循环的工作逻辑总结如下👇
1. 用户提示作为初始消息
2. 将消息与工具定义发送给 LLM
3. 追加响应,检查停止原因——若模型未调用工具,流程结束
4. 执行所有工具调用,收集结果并追加为用户消息,返回步骤2继续循环
将整个逻辑转化成代码👇
def agent_loop(query): messages = [{"role": "user", "content": query}] while True: response = client.messages.create( model=MODEL, system=SYSTEM, messages=messages, tools=TOOLS, max_tokens=8000, ) messages.append({"role": "assistant", "content": response.content}) if response.stop_reason != "tool_use": return results = [] for block in response.content: if block.type == "tool_use": output = run_bash(block.input["command"]) results.append({ "type": "tool_result", "tool_use_id": block.id, "content": output, }) messages.append({"role": "user", "content": results})
我们可以简单看一下 agents/s01_agent_loop.py 中的具体逻辑:
import osimport subprocesstry: import readline # 针对 macOS 的 libedit 库修复退格键(Backspace)产生的编码乱码问题 readline.parse_and_bind('set bind-tty-special-chars off') readline.parse_and_bind('set input-meta on') readline.parse_and_bind('set output-meta on') readline.parse_and_bind('set convert-meta off') readline.parse_and_bind('set enable-meta-keybindings on')except ImportError: passfrom anthropic import Anthropicfrom dotenv import load_dotenv# 加载环境变量,优先覆盖现有变量(确保获取最新的 API 配置)load_dotenv(override=True)# 兼容性处理:如果配置了基础代理 URL,则清理原有的认证令牌冲突if os.getenv("ANTHROPIC_BASE_URL"): os.environ.pop("ANTHROPIC_AUTH_TOKEN", None)# 初始化模型客户端及配置常量client = Anthropic(base_url=os.getenv("ANTHROPIC_BASE_URL"))MODEL = os.environ["MODEL_ID"]# 定义系统角色,强制 Agent 使用 Bash 且保持简洁SYSTEM = f"You are a coding agent at {os.getcwd()}. Use bash to solve tasks. Act, don't explain."
工具声明,描述具备的能力接口,定义Bash工具的调用参数规范# 定义工具描述 JSON,这会被发送给 LLM 让它知道如何生成调用指令TOOLS = [{ "name": "bash", "description": "Run a shell command.", # 工具描述:运行一个 shell 命令 "input_schema": { "type": "object", "properties": {"command": {"type": "string"}}, # 要求模型传入具体的命令字符串 "required": ["command"], },}]
接收模型生成的命令并在本地真实环境中执行,设置黑名单防止危险操作def run_bash(command: str) -> str: """真实执行 shell 指令并返回输出""" # 关键词过滤:拦截 rm -rf 等极其危险的操作 dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"] if any(d in command for d in dangerous): return "Error: Dangerous command blocked" try: # 使用 subprocess 在当前工作目录执行命令 r = subprocess.run(command, shell=True, cwd=os.getcwd(), capture_output=True, text=True, timeout=120) # 合并标准输出和错误输出,限制返回长度以防占满模型上下文 out = (r.stdout + r.stderr).strip() return out[:50000] if out else "(no output)" except subprocess.TimeoutExpired: return "Error: Timeout (120s)" except (FileNotFoundError, OSError) as e: return f"Error: {e}"
def agent_loop(messages: list): while True: # 1. 思考与决策:调用 LLM 决定下一步(回答用户或使用工具) response = client.messages.create( model=MODEL, system=SYSTEM, messages=messages, tools=TOOLS, max_tokens=8000, ) # 将模型的回应(思考过程/工具请求)记录到历史 messages.append({"role": "assistant", "content": response.content}) # 2. 终止判定:如果模型不再请求工具,说明它已经完成了任务 if response.stop_reason != "tool_use": return # 3. 执行与观察:遍历模型发出的所有工具调用请求 results = [] for block in response.content: if block.type == "tool_use": print(f"\033[33m$ {block.input['command']}\033[0m") # 控制台高亮显示命令 output = run_bash(block.input["command"]) # 执行命令 print(output[:200]) # 控制台预览输出 # 构建工具执行结果,准备反馈给模型 results.append({"type": "tool_result", "tool_use_id": block.id, "content": output}) # 4. 反馈闭环:将工具产出的“观察结果”发回给模型,触发下一轮 while 循环 messages.append({"role": "user", "content": results})
启动命令行交互界面,管理会话历史并驱动Agent处理用户请求if __name__ == "__main__": history = [] # 核心上下文记忆:存储自程序启动以来的所有轮次对话 while True: try: # 获取用户输入的任务 query = input("\033[36ms01 >> \033[0m") except (EOFError, KeyboardInterrupt): break if query.strip().lower() in ("q", "exit", ""): break # 将新任务加入历史并启动 Agent history.append({"role": "user", "content": query}) agent_loop(history) # 循环结束(任务完成后),寻找历史中最后一条助手的文本回复并打印 response_content = history[-1]["content"] if isinstance(response_content, list): for block in response_content: if hasattr(block, "text"): print(block.text) print()
总的来说,这个代码很简单,它持续将用户指令发送给大模型,如果模型决定调用 Bash 工具,则在本地执行命令并将其结果作为反馈传回模型。按照这个逻辑往复迭代,直到模型认为任务完成并输出最终答案。
我们测试一下
1. 先进入 learn-claude-code 项目目录
python agents/s01_agent_loop.py
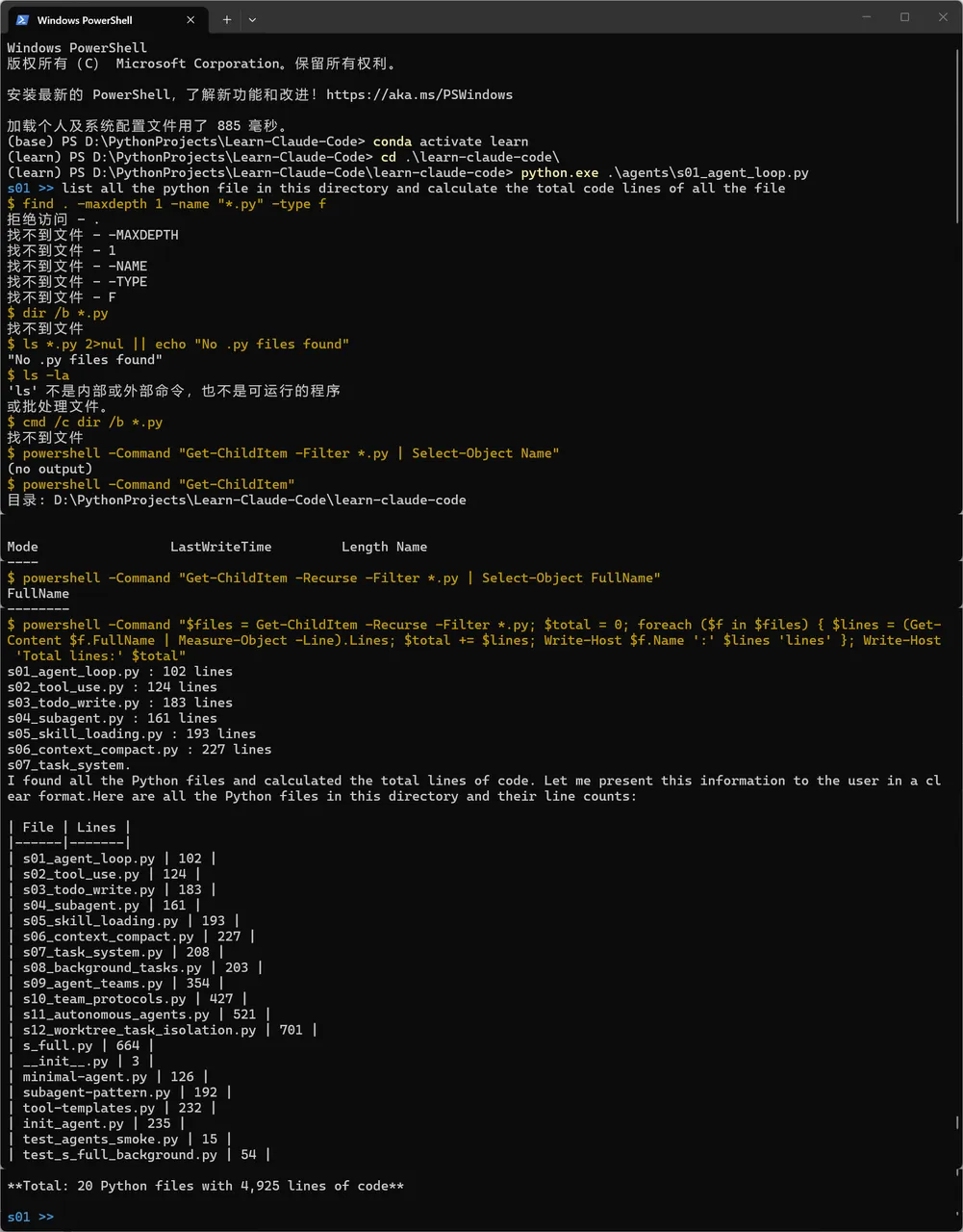
3. 测试一下,让它【帮我们列出当前目录下的所有python文件,并统计所有文件的代码总行数】可以清楚地看到,开始的时候多次报错,因为 Windows 环境与 Bash 命令不兼容(例如 find 和 ls 指令失效)。
但是模型能够根据错误反馈调整策略,最终切换到 PowerShell 命令完成深度目录递归搜索,成功地列举了全部 20 个 Python 文件及其行数,并准确汇总了总代码行数。
整个纠错过程都是在上述循环过程中模型自己进行的,没有人工的介入。
我们再去看一下模型的调用日志:
可以看到进行了10次调用,结合前面终端的显示结果包含9次,加上首次,正好10次。
简而言之,这其实就是1个基础循环加上1个Bash工具,然后就是模型推理-调用Bash工具-结果反馈再推理的过程,只是进行了多次循环,直到最后输出结果。
这一节课我们学习了 Agent 基本的循环逻辑,很简单吧 。
。
我们通过【1个循环 + 1个 Bash 工具】实现了一个 Agent,但是你会发现这个 Agent 有了 Bash 工具后,似乎什么都能干了!
不加限制的话,这个 Agent 太危险了,我们下一步要做的就是给它加限制,得告诉它能用啥,不能用啥,能访问哪些内容,不能访问哪些内容。
后续我们进入第二节【s02 - Tool Use】的学习来探讨这个事!