哈夫曼编码(Huffman Coding)是一种用于无损数据压缩的最优变长编码方法。它的核心思想非常直观:为出现频率高的字符分配较短的编码,为出现频率低的字符分配较长的编码,从而使得最终的总编码长度最短
核心概念
哈夫曼编码的实现依赖于哈夫曼树(Huffman Tree),它又被称为最优二叉树。
如何构建哈夫曼树
1. 初始化森林:
根据给定的 n 个权值,构造 n 棵仅含一个根节点的二叉树,形成一个森林。每棵树的根节点权值即为对应的字符频率。
2. 选择与合并:
在森林中选出两棵根节点权值最小的树,作为左右子树合并成一棵新树。新树的根节点权值等于其左右子树根节点权值之和。
3. 更新森林:
将步骤2中选出的两棵树从森林中删除,并将新构造的树加入森林。
4. 循环:
重复步骤2和3,直到森林中只剩下一棵树为止。这棵树就是哈夫曼树。 注意事项:在合并时,通常规定左子树权值小于右子树,或者规定左分支为0、右分支为1,以保证编码的唯一性参考实现
详细计算示例
以“helloworlds”为例
1. 计算字符频率
l 3o 2h 1e 1w 1r 1d 1s 1
2. 构建哈夫曼树
现在有 8 个不同的字符(8 个叶子节点)。根据哈夫曼树的构造规则,我们需要进行 7 次合并。
初始队列
根据频率从低到(按字符出现的时间)高进行排序
# 队列:[h(1), e(1), w(1), r(1), d(1), s(1), o(2), l(3)]
第一次合并
合并h(1)和e(1)为A(2)加入队列,并把这两个从队列中移除
# 队列:[w(1), r(1), d(1), s(1), o(2), A(2), l(3)]
第二次合并
合并w(1)和r(1)为B(2)加入队列,并把这两个从队列中移除
[d(1), s(1), o(2), A(2),B(2), l(3)]
第三次合并
合并d(1)和s(1)为C(2)加入队列,并把这两个从队列中移除
[o(2), A(2),B(2),C(2), l(3)]
第四次合并
合并o(2)和A(2)为D(4)加入队列,并把这两个从队列中移除
[B(2),C(2), l(3),D(4)]
第五次合并
合并B(2)和C(2)为E(4)加入队列,并把这两个从队列中移除
[l(3),D(4),E(4)]
第六次合并
合并l(3)和D(4)为F(7)加入队列,并把这两个从队列中移除
[E(4),F(7)]
第七次合并
合并E(4)和F(7)为根节点G(11)
3. 组成树
拆开还原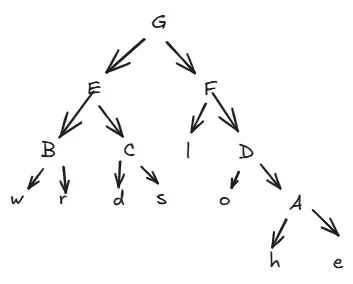
生成哈夫曼编码
遵守左0右1原则
l 3 10 (上层F是右子树,l本身是左子树,所以是10)o 2 110h 1 1110e 1 1111w 1 000r 1 001d 1 010s 1 011
计算总编码长度
编码长度可以理解为深度-1
高频字符 l (3次):编码长度 2,贡献 3×2=63×2=6中频字符 o (2次):编码长度 3,贡献 2×3=62×3=6低频字符 (h, e, w, r, d, s 共6个,各1次):编码长度 4,贡献 6×4=24总长度 (WPL) = 6+6+24=36 bit
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
