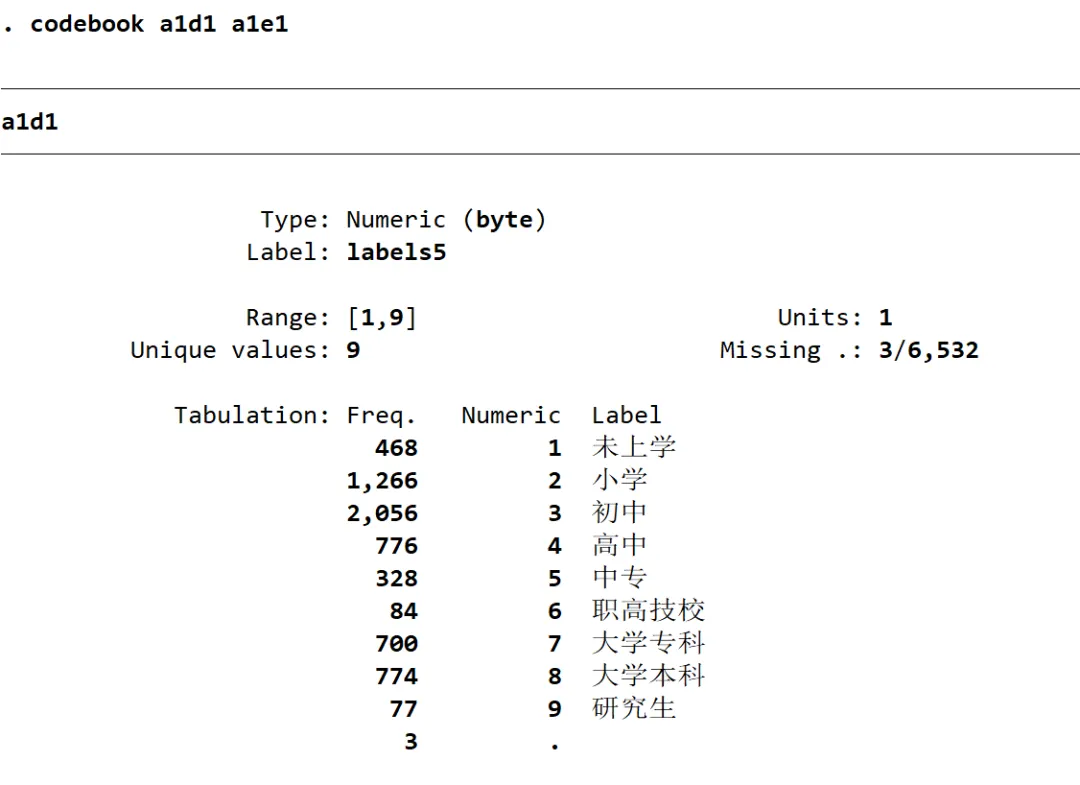
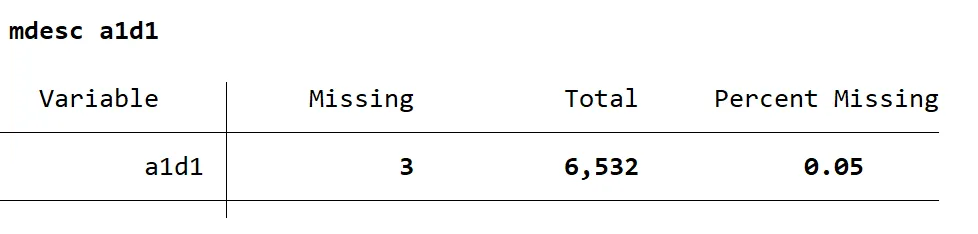
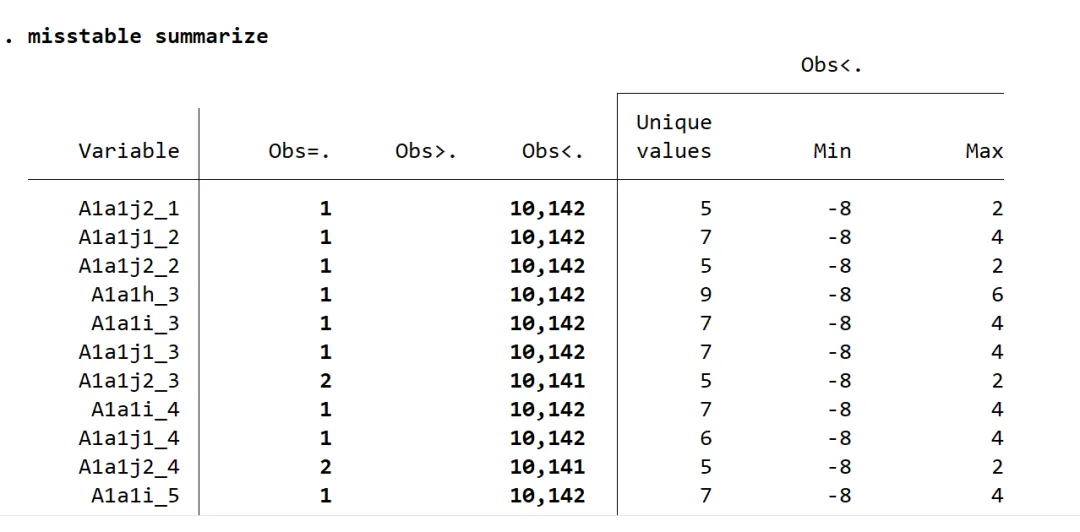
数据插补是一种通过填补缺失值来使数据集更加完整的方法。常见的数据插补方法包括均值插补法、中位数插补法、回归插补法、多重插补法(MI)等。
(1)均值插补法
用变量的均值替代缺失值。这种方法简单且易于实现,但在变量分布不对称的情况下可能引入偏差。
*方法1:手动计算均值后替换(推荐,可查看均值)
summarize var1 //先查看var1的均值(结果中Mean列)
replace var1=r(mean) if missing(var1) // 用均值填补var1的缺失值
*方法2:一行命令直接填补(无需手动看均值)
replace+聚合函数(mean()/median()/mode())
replace var1=mean(var1) if missing(var1) //直接填补
适用场景:连续变量用均值 / 中位数,分类变量用众数
(2)中位数插补法
用变量的中位数替代缺失值。相比均值插补法,中位数插补法更适用于分布不对称的数据。
*方法1:手动计算中位数后替换
summarize var1, detail // 查看var1的中位数(结果中50%列)
replace var1=r(p50) if missing(var1) // 用中位数填补
*方法2:一行命令直接填补,自动计算
replace var1=median(var1) if missing(var1)
注意:
分类变量(如性别变量gender)分组填补:
*分组均值插补
bysort gender:replace var1=mean(var1) if missing(var1)
*分组中位数插补
bysort gender:replace var1=median(var1) if missing(var1)
(3)回归插补法
利用回归模型预测缺失值,并用预测值替代缺失值。这种方法考虑了变量之间的关系,因此比均值插补和中位数插补更为精确。
将有缺失的变量作为因变量,选择若干完整的变量作为自变量构建回归模型,用模型预测值填补缺失值。
「简单回归插补」:直接用预测值填补(易低估方差);
* 方法1:简单回归插补
* 步骤1:用完整数据拟合回归模型(mpg为因变量,weight/foreign为自变量)
regress mpg weight foreign if e(sample) // 仅用无缺失的样本拟合
* 步骤2:预测缺失值(对所有样本生成预测值)
predict mpg_pred, xb // xb表示线性预测值
* 步骤3:用预测值填补缺失值
replace mpg = mpg_pred if missing(mpg)
「随机回归插补」:预测值 + 随机残差(更贴近真实数据分布)。
* 方法2:随机回归插补(带残差,更优)
sysuse auto_miss, clear // 重新加载带缺失值的数据
* 步骤1:拟合回归并提取残差
regress mpg weight foreign if e(sample)
predict mpg_pred, xb // 预测值
predict resid, residuals // 残差
* 步骤2:随机抽取残差并加到预测值上
summarize resid // 查看残差分布
gen rand_resid = resid[runiformint(1, _N)] // 随机抽取残差
* 步骤3:填补缺失值(预测值+随机残差)
replace mpg = mpg_pred + rand_resid if missing(mpg)
* 查看填补结果
list mpg weight foreign in 1/10 // 前10行原本是缺失值,已填补
(4)多重插补法(MI)
通过多次插补生成多个完整的数据集,并将这些数据集的分析结果进行综合。多重插补法能够充分利用数据,减少因缺失值导致的偏差。
核心步骤: