学习笔记|麻省理工-人工智能课11学习:识别树、无序度
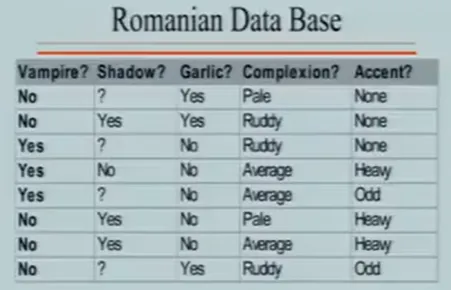
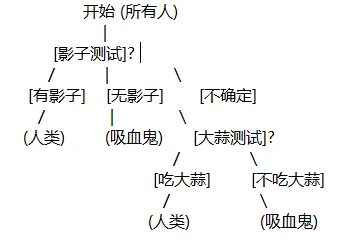
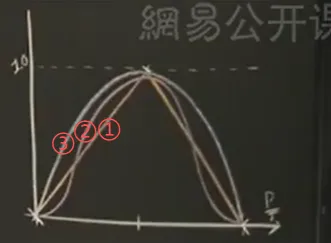
你好呀,我是希源,见字如面。(全文约2700字,阅读9分钟)B站有很多各个大学的公开课程,最近在学《麻省理工-人工智能》课程,2010年的,作为入门课程,开拓思维、训练逻辑能力很是合适。分享一下第11节课的内容,一些学到的生活道理和专业知识~ 今日问题:‘校园抓鬼’——你新转学到一个神秘的校园,周围人可能隐藏着吸血鬼。如何快速、低成本地把他们揪出来?这是一种生活智慧:关于如何在复杂世界里,用最小代价做出靠谱选择。你有一些测试方法(如“是否有影子”“是否怕大蒜”“口音如何”),第一个测试方法(比如影子测试/大蒜测试/口音等)假如有三种结果,得有且只有一种结果可以进行到下一步测试,继续...因此,这里我们希望构建一个测试集,得到不同的结果,然后可能还需要不同的测试,直到最终确定结果。这种通过一系列测试逐步缩小范围、最终完成分类的树状逻辑结构——称为识别树(Identification Tree)(不是决策树,但思想同源。)这个数据集和上节课最近邻数据集有区别,区别是什么呢?如果用最近邻去识别吸血鬼,会有什么问题?①这些特征不是数值的;这不是数值数据集而是符号,你不能说有0.7个影子,要么有影子要么没影子要么不能确定。④有些测试可能比其它代价更大;例如判断影子你需要让他走到阳光下这个行动,这个代价可能会更大一点。我们要建立一棵好的树。需要看哪种测试能最好的将事物分开,哪种能最好的在下面建立子集,让子集尽可能同质。每个测试有成本代价(比如让人走到阳光下可能打草惊蛇)。我们希望这是一棵好的测试树,最小代价,如果代价相同,那就是最小测试数。这套策略,用尽可能少、代价低的测试,得到可靠的结论。那么树的底端每一个叶子的测试所生成的集合都是均匀的,同质的。我们想要最后所有普通人在一起,吸血鬼在一起。希望这是棵小树,最简单的树,而不是大的。(大英博物馆算法就太大了。)那么如何安排这些测试方法才能让他成功识别呢?我们是如何确定先做影子测试?再做另一个测试?简单的想法就是看看有多少样本在同质子集中。看哪个测试能立即产生最多的同质子集(即该分支下样本已完全属于同一类)。例如“影子测试”:无影子→全是吸血鬼;有影子→全是人类;不确定→混合,需进一步测试。永远选择从最优的开始。但数据量大时呢?很难有测试能立刻得到任何同质子集,需要有更精密的方式去测量分支底端的这些集合有多无序,即无序度(Disorder)——借用了信息论中的熵的概念(信息的本质),用来衡量一个集合的“混乱程度”。良好生活的一大启发:碰到问题时问知道答案的人,这比谷歌(百度)还方便且工作量更小。设无序度集合D,是一个二进制的数据集合,数值要么正要么负,我们设定P是正,N是负,T=P+N总数,等式如下。画一条曲线,假设横轴测量的是正值数目同总数的比值,取值范围就是0到1。情况1:正数和负数是均分的,相等的个数,那么结果D=1。情况2:全是正数,结果D=0。(结果其实是-0*以2为底0的对数,不能直接想当然认为0乘以任何数都是0这样,需要用到洛必达法则去无限逼近,求导。不过结果确实是0)这三条曲线,①是直线,②是高斯曲线,③是无序度的结果曲线。(自然界并不一切都是高斯曲线)但是这个曲线表示的这个方法并不一定是最好的方法,上帝不会偏袒任何一种可能,我们用这个是因为他相对很合理,用来测集合的无序度很好用。当我们用熵值计算各测试的无序度时,发现“口音测试”熵值很高(效果差),而“影子测试”熵值很低(效果好)——这我们会突然发现,数学计算和我们的直觉选择是一样的,直觉也很重要。数学在这里不是推翻直觉,而是为直觉提供支撑。好的理论,常让模糊的感觉变得清晰可循。那么如何测量这整个测试的质量呢?我们现在求无序度只是对其中一个测试的集合的。方法1:每个集合的无序度进行求和。这种方法给的权重是一样的,哪怕分支下面什么都没有,权重等同于下面几乎什么都有。方法2:求和加权。加权,就是再乘一个比值——该分支下的样本量/样本总量。【也可以应用到数值数据上,老师举例说我去帮忙测体温,我得到了非常多样本的体温数据,假如吸血鬼集中102华摄氏度,而人类是98摄氏度,我测的样本有正常人类有发烧人类有吸血鬼。哦莫那我当然可以用这个识别树的方法。其实我感觉有一点点像二分查找,比如在0到9中找到7,那我就是设定界限。然后不断比较大小,看他在哪直到找到目标。不过实际上是无序的数据,我们是为了分出同质子集,我们可以用相同的方法处理不同的数据,成千上万次,直到出结果。识别树虽清晰,但在实际应用中,(如医疗诊断,有一些人可能不喜欢看这个树,假设一位医生要判定是否是甲状腺病人,给医生一个树让他进行二十多种测试,这不如直接给他一个规则。)每条规则对应从根到叶的一条路径。之后还可合并、简化,形成最精简的判断逻辑。总之最后我们能得到一个最简单的机制。基于种种种种这些规则所确定的行为能得到一个完成的结果。最后来看看上面的方法和之前的最近邻算法的对比。最近邻中我们采用决策边界(每两点之间的垂直平分线)来划分不同的区域。而在识别树中,我们会先确定一条线,分成两个子集,然后再对每个子集采用同样的方法划分,因此最后得到的区域就会与最近邻有所不同。你不需要使用所有的测试,只需使用看起来对你有用的测试。这意味着测量技术变简单了,代价也更小,结果更容易解释和转化为行动规则。
今日问题:‘校园抓鬼’——你新转学到一个神秘的校园,周围人可能隐藏着吸血鬼。如何快速、低成本地把他们揪出来?这是一种生活智慧:关于如何在复杂世界里,用最小代价做出靠谱选择。你有一些测试方法(如“是否有影子”“是否怕大蒜”“口音如何”),第一个测试方法(比如影子测试/大蒜测试/口音等)假如有三种结果,得有且只有一种结果可以进行到下一步测试,继续...因此,这里我们希望构建一个测试集,得到不同的结果,然后可能还需要不同的测试,直到最终确定结果。这种通过一系列测试逐步缩小范围、最终完成分类的树状逻辑结构——称为识别树(Identification Tree)(不是决策树,但思想同源。)这个数据集和上节课最近邻数据集有区别,区别是什么呢?如果用最近邻去识别吸血鬼,会有什么问题?①这些特征不是数值的;这不是数值数据集而是符号,你不能说有0.7个影子,要么有影子要么没影子要么不能确定。④有些测试可能比其它代价更大;例如判断影子你需要让他走到阳光下这个行动,这个代价可能会更大一点。我们要建立一棵好的树。需要看哪种测试能最好的将事物分开,哪种能最好的在下面建立子集,让子集尽可能同质。每个测试有成本代价(比如让人走到阳光下可能打草惊蛇)。我们希望这是一棵好的测试树,最小代价,如果代价相同,那就是最小测试数。这套策略,用尽可能少、代价低的测试,得到可靠的结论。那么树的底端每一个叶子的测试所生成的集合都是均匀的,同质的。我们想要最后所有普通人在一起,吸血鬼在一起。希望这是棵小树,最简单的树,而不是大的。(大英博物馆算法就太大了。)那么如何安排这些测试方法才能让他成功识别呢?我们是如何确定先做影子测试?再做另一个测试?简单的想法就是看看有多少样本在同质子集中。看哪个测试能立即产生最多的同质子集(即该分支下样本已完全属于同一类)。例如“影子测试”:无影子→全是吸血鬼;有影子→全是人类;不确定→混合,需进一步测试。永远选择从最优的开始。但数据量大时呢?很难有测试能立刻得到任何同质子集,需要有更精密的方式去测量分支底端的这些集合有多无序,即无序度(Disorder)——借用了信息论中的熵的概念(信息的本质),用来衡量一个集合的“混乱程度”。良好生活的一大启发:碰到问题时问知道答案的人,这比谷歌(百度)还方便且工作量更小。设无序度集合D,是一个二进制的数据集合,数值要么正要么负,我们设定P是正,N是负,T=P+N总数,等式如下。画一条曲线,假设横轴测量的是正值数目同总数的比值,取值范围就是0到1。情况1:正数和负数是均分的,相等的个数,那么结果D=1。情况2:全是正数,结果D=0。(结果其实是-0*以2为底0的对数,不能直接想当然认为0乘以任何数都是0这样,需要用到洛必达法则去无限逼近,求导。不过结果确实是0)这三条曲线,①是直线,②是高斯曲线,③是无序度的结果曲线。(自然界并不一切都是高斯曲线)但是这个曲线表示的这个方法并不一定是最好的方法,上帝不会偏袒任何一种可能,我们用这个是因为他相对很合理,用来测集合的无序度很好用。当我们用熵值计算各测试的无序度时,发现“口音测试”熵值很高(效果差),而“影子测试”熵值很低(效果好)——这我们会突然发现,数学计算和我们的直觉选择是一样的,直觉也很重要。数学在这里不是推翻直觉,而是为直觉提供支撑。好的理论,常让模糊的感觉变得清晰可循。那么如何测量这整个测试的质量呢?我们现在求无序度只是对其中一个测试的集合的。方法1:每个集合的无序度进行求和。这种方法给的权重是一样的,哪怕分支下面什么都没有,权重等同于下面几乎什么都有。方法2:求和加权。加权,就是再乘一个比值——该分支下的样本量/样本总量。【也可以应用到数值数据上,老师举例说我去帮忙测体温,我得到了非常多样本的体温数据,假如吸血鬼集中102华摄氏度,而人类是98摄氏度,我测的样本有正常人类有发烧人类有吸血鬼。哦莫那我当然可以用这个识别树的方法。其实我感觉有一点点像二分查找,比如在0到9中找到7,那我就是设定界限。然后不断比较大小,看他在哪直到找到目标。不过实际上是无序的数据,我们是为了分出同质子集,我们可以用相同的方法处理不同的数据,成千上万次,直到出结果。识别树虽清晰,但在实际应用中,(如医疗诊断,有一些人可能不喜欢看这个树,假设一位医生要判定是否是甲状腺病人,给医生一个树让他进行二十多种测试,这不如直接给他一个规则。)每条规则对应从根到叶的一条路径。之后还可合并、简化,形成最精简的判断逻辑。总之最后我们能得到一个最简单的机制。基于种种种种这些规则所确定的行为能得到一个完成的结果。最后来看看上面的方法和之前的最近邻算法的对比。最近邻中我们采用决策边界(每两点之间的垂直平分线)来划分不同的区域。而在识别树中,我们会先确定一条线,分成两个子集,然后再对每个子集采用同样的方法划分,因此最后得到的区域就会与最近邻有所不同。你不需要使用所有的测试,只需使用看起来对你有用的测试。这意味着测量技术变简单了,代价也更小,结果更容易解释和转化为行动规则。 这门2010年的课,至今仍闪耀着朴素而实用的光芒。它提醒我们:最好的算法,常源于对人类如何思考、如何决策的深刻洞察。在人工智能飞速进化的今天,我们更应珍惜自身那种权衡代价、筛选信息、在模糊中寻找清晰的决策能力——这不仅是算法,更是一种生存的能力。
这门2010年的课,至今仍闪耀着朴素而实用的光芒。它提醒我们:最好的算法,常源于对人类如何思考、如何决策的深刻洞察。在人工智能飞速进化的今天,我们更应珍惜自身那种权衡代价、筛选信息、在模糊中寻找清晰的决策能力——这不仅是算法,更是一种生存的能力。- 并非所有信息都值得获取:评估测试成本(时间、精力、风险),选择性价比最高的路径,是生活算法的重要一环。
- 接纳不确定,并继续前行:大的数据集不可能立刻得到好的结果,即使最好的测试,一开始也可能留下“不确定”分支。我们不必追求一击即中,而是准备好后续策略,在信息不完备时依然能向前推进。
- 规则是经验的沉淀:树可以转为规则,经历也可凝为原则。前人栽树后人乘凉。我们也要多多栽树呀。
学习之路,亦是选择之路。愿我们都能在心智的森林里,种下那棵清晰而坚韧的好树。参考课程:《Artificial Intelligence》2010
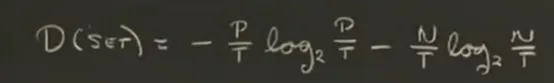



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
