版本: v2.0更新时间: 2026年4月适用人群: 医学生、临床医生、医学研究人员、公共卫生从业者、生物统计专业学生
费用: 不收费,但希望你请我喝杯奶茶😀
目录
前言:医学统计学的核心价值与学习路径
第一部分:统计学基础理论
第二部分:统计推断方法
第三部分:高级统计分析方法
第四部分:研究设计与样本量估算
第五部分:统计软件实操
第六部分:国际报告规范与质量控制
附录:常用速查表
前言:医学统计学的核心价值与学习路径
1.1 医学统计学的定义与价值
统计学(Statistics) 源于拉丁语"State",意为"数据收集、整理、分析、解释"的科学。现代统计学定义为:一门处理数据变异、通过收集、分类和分析数据获得可靠结果的科学和艺术。
“在理性的基础上,所有的判断都是统计学。” —— 统计学家C.R. Rao
医学领域相关统计学科
医学统计学在医学研究中的应用
医学实验室研究 → 实验数据分析临床研究 → 个体水平评价临床试验 → 治疗有效性和安全性评价流行病学研究 → 疾病病因探索(如吸烟与肺癌关系)公共卫生 → 群体健康评估
1.2 学习路径
本教程采用"基础→进阶→应用"三阶段学习路径:
第一阶段:基础理论(1-6章)├── 数据类型与统计学基础概念├── 研究设计方法├── 概率分布(二项分布、正态分布、Poisson分布)├── 抽样分布与中心极限定理├── 参数估计└── 假设检验原理第二阶段:核心方法(7-13章)├── t检验(单样本、配对、独立样本)├── 方差分析(完全随机、随机区组、重复测量)├── 卡方检验与非参数检验├── 相关与回归分析├── Logistic回归├── 生存分析└── 多元统计分析第三阶段:应用实践(14-22章)├── 高级统计专题(机器学习、贝叶斯、因果推断)├── 研究设计与样本量估算├── 统计软件实操(SPSS/R/SAS)├── 国际报告规范└── 统计质量控制
1.3 统计软件选择指南
第一部分:统计学基础理论
第1章:数据类型与统计学基础概念
1.1 统计学基本概念
1.1.1 总体与样本
总体(Population):根据研究目的确定的同质的所有个体某项观察值的集合。
总体参数:刻画总体特征的指标(通常未知)
样本(Sample):从总体中随机抽取的部分个体
样本量(Sample Size):样本中的个体总数 n
样本统计量:由样本数据计算的特征量
1.1.2 个体与变异
个体(Individual):根据研究目的确定的最基本的研究对象单位,又称观察单位。
个体变异(Individual Variation):同质个体的某指标之间的差异。
同质(Homogeneous):具有相同性质的观察单位异质(Heterogeneous):具有不同性质的观察单位
1.1.3 概率与频率
频率(Frequency):在n次观察中,事件A发生了m次,则 f = m/n
概率(Probability):描述随机事件发生的可能性大小,范围 0 ≤ P(A) ≤ 1
小概率事件原理:随机事件发生的概率 ≤ 0.05,在一次随机抽样中不会发生。
1.2 数据类型体系
医学数据的正确分类是统计分析的第一步。
1.2.1 计量资料(定量资料)
定义:用连续数值表示的资料,具有计量单位。
特征:
常见示例:
正态性判断方法:
正态性检验方法│├─ 图示法│ ├─ 直方图(钟形分布)│ ├─ P-P图(点贴近对角线)│ └─ Q-Q图(点贴近对角线)│├─ 统计检验│ ├─ Shapiro-Wilk检验(n<50,推荐)│ ├─ Kolmogorov-Smirnov检验(n≥50)│ └─ Anderson-Darling检验│└─ 经验法则 ├─ 偏度(Skewness)绝对值 < 2 └─ 峰度(Kurtosis)绝对值 < 7
1.2.2 计数资料(定性资料)
定义:按事物属性分组清点数目得到的资料。
1.2.3 等级资料(有序资料)
定义:具有等级顺序但非定量的资料。
特点:
⚠️ 特别注意:等级资料的统计分析应选用非参数检验,不能简单当作计数资料处理。
1.3 误差与偏倚
1.3.1 误差类型
1.3.2 偏倚类型与控制
第2章:研究设计方法
2.1 研究设计分类体系
研究设计类型├── 描述性研究│ ├── 横断面研究(现况调查)│ ├── 病例报告/系列病例│ └── 生态学研究│├── 分析性研究│ ├── 病例对照研究(回顾性,从结果到原因)│ ├── 队列研究(前瞻性,从原因到结果)│ └── 嵌套病例对照研究│└── 实验性研究 ├── 随机对照试验(RCT) ├── 非随机对照试验 ├── 自身对照试验 └── 交叉试验
2.2 各类研究设计特点
2.3 随机对照试验(RCT)
2.3.1 RCT三要素
临床试验核心要素│├─ P(Patient/Population):受试对象│ └─ 同质性、代表性、对处理因素敏感│├─ I/C(Intervention/Control):处理因素│ └─ 处理因素 vs 非处理(混杂)因素│└─ O(Outcome):实验效应/结局指标 ├─ 主要指标(主要终点) ├─ 次要指标(次要终点) └─ 需客观、灵敏、特异
2.3.2 RCT三原则
1. 随机化原则
2. 对照原则
3. 重复原则
足够的样本含量(sample size),目的:控制和估计试验误差。
2.3.3 盲法原则
2.4 观察性研究设计
2.4.1 横断面研究
横断面抽样调查│├─ 优点:│ ├─ 了解患病流行情况│ ├─ 广泛探索病因│ └─ 周期短、成本低│└─ 缺点: ├─ 时点研究,无法推断因果 ├─ 不适合患病率低的疾病 └─ 不能得到发病率情况
2.4.2 病例对照研究
由果溯因的回顾性研究。
病例对照研究│├─ 优点:│ ├─ 适用于罕见病│ ├─ 可快速得到危险因素估计│ └─ 可做明确或不明因素探索│└─ 缺点: ├─ 易产生回忆偏倚 ├─ 选择性偏倚 └─ 不能估计患病率、死亡率
2.4.3 队列研究
由因到果的前瞻性研究。
队列研究│├─ 前瞻性队列:从现在开始随访└─ 回顾性队列:利用历史资料│├─ 优点:│ ├─ 由因到果,结论较可靠│ ├─ 可获得发病率资料│ └─ 无记忆偏倚│└─ 缺点: ├─ 周期长 └─ 需要预试验研究支持
2.5 抽样方法
2.5.1 概率抽样
2.5.2 抽样误差比较
整群抽样 ≥ 简单抽样 ≥ 系统抽样 ≥ 分层抽样(抽样误差由大到小)
第3章:概率分布基础
3.1 二项分布
3.1.1 Bernoulli试验与二项分布
Bernoulli试验:
二项分布:n次独立重复试验中,成功次数X的概率分布。记作 X ~ B(n, π)
3.1.2 二项分布公式
P(X=k) = C(n,k) × π^k × (1-π)^(n-k)其中:- n:试验总次数- k:成功次数(0 ≤ k ≤ n)- π:单次成功概率- C(n,k):组合数 = n!/(k!(n-k)!)
3.1.3 二项分布特征
期望与方差:E(X) = n × πVar(X) = n × π × (1-π)分布特征:- 离散分布- 高峰在 μ = nπ 处- π 接近 0.5 时,图形对称- n 增大时,分布趋于对称- n → ∞ 时,趋向正态分布
3.1.4 二项分布的正态近似
条件:n较大,且 nπ 和 n(1-π) 均 ≥ 5 时,可用正态分布近似。
X ~ N(n×π, n×π×(1-π))标准化:Z = (X - n×π) / √(n×π×(1-π))
3.1.5 医学应用
3.2 正态分布
3.2.1 正态分布定义
正态分布(高斯分布):最常见的连续型概率分布。
概率密度函数:f(x) = (1/(σ√(2π))) × e^(-(x-μ)²/(2σ²))参数:- μ:总体均数(位置参数)- σ:总体标准差(形状参数)- σ²:总体方差
3.2.2 正态分布曲线特征
正态分布曲线特点│├─ 钟形曲线,关于均值μ对称├─ 在x=μ处取得最大值├─ 曲线下面积分布:│ ├─ μ±1σ:包含68.27%的数据│ ├─ μ±1.96σ:包含95%的数据│ └─ μ±2.58σ:包含99%的数据├─ 曲线两端无限接近横轴└─ 偏度=0,峰度=0
3.2.3 标准正态分布
μ=0, σ=1的正态分布,记为 N(0,1)
标准正态变换:Z = (X - μ) / σ常用界值:- Z₀.₀₅ = 1.96(双侧95%)- Z₀.₀₁ = 2.58(双侧99%)- Z₀.₁ = 1.64(单侧90%)
3.2.4 医学应用
3.3 Poisson分布
3.3.1 定义与公式
Poisson分布:单位时间/空间内随机事件发生次数的离散型概率分布。
适用条件:- 事件独立发生- 事件发生率λ恒定- 事件可数且为非负整数公式:P(X=k) = (λ^k × e^(-λ)) / k!其中:- k:事件发生次数(0, 1, 2, ...)- λ:单位时间内事件发生的期望次数- e:自然常数(约2.71828)
3.3.2 Poisson分布特征
期望与方差:E(X) = λVar(X) = λ分布特点:- 离散分布- λ 较小时呈右偏态- λ 增大时趋于对称- 可加性:X₁~Po(λ₁), X₂~Po(λ₂) → X₁+X₂~Po(λ₁+λ₂)
3.3.3 医学应用
3.4 分布间关系
概率分布家族│├─ 离散型分布│ ├─ 二项分布(n次试验中的成功次数)│ ├─ Poisson分布(单位时间/空间事件数)│ ├─ 超几何分布(不放回抽样)│ └─ 几何分布(首次成功所需的试验次数)│└─ 连续型分布 ├─ 正态分布(最常见,连续型基础) ├─ 标准正态分布(Z分布) ├─ t分布(小样本推断) ├─ 卡方分布(方差推断) ├─ F分布(方差比推断) └─ 指数分布(生存时间)
第4章:抽样分布与中心极限定理
4.1 抽样分布概念
抽样分布:从同一总体中反复抽取样本,样本统计量的概率分布。
核心概念│├─ 样本均数 x̄│ └─ 样本均数的抽样分布:x̄ ~ N(μ, σ²/n)│├─ 样本方差 s²│ └─ (n-1)s²/σ² ~ χ²(n-1)│└─ 样本率 p̂ └─ p̂的抽样分布(n大时近似正态)
4.2 中心极限定理
4.2.1 定理内容
中心极限定理(CLT):从任意总体中抽取的样本,当样本量n足够大时,样本均数的分布近似正态分布。
中心极限定理│├─ 原始总体:任意分布(不必正态)├─ 样本量:n ≥ 30(大样本)├─ 样本均数分布:x̄ ~ N(μ, σ²/n)└─ 近似程度:n越大,近似越好
4.2.2 中心极限定理的意义
- 均数推断基础
- 置信区间
- 假设检验
4.3 标准误
4.3.1 标准误定义
标准误(Standard Error, SE):样本统计量分布的标准差。
均数的标准误:σx̄ = σ / √n样本标准误:Sx̄ = s / √n标准误与标准差的区别:- 标准差:描述个体观察值的离散程度- 标准误:描述样本统计量的离散程度
4.3.2 率的标准误
σp = √(π(1-π)/n)样本率的标准误:Sp = √(p̂(1-p̂)/n)
4.4 t分布
4.4.1 t分布定义
用于小样本(n<30)总体均数的推断。
t分布特点│├─ 形态:类似正态分布,但尾部更厚├─ 自由度:df = n-1├─ 自由度越大,越接近正态分布│ ├─ df=1:最厚尾│ ├─ df=10:接近正态│ └─ df=30:几乎等同正态└─ t分布表:查tα(df)值
4.4.2 t统计量
t = (x̄ - μ) / (s/√n) ~ t(n-1)
4.5 卡方分布
4.5.1 卡方分布定义
k个独立标准正态变量平方和的分布。
χ²分布特点│├─ 形状:正偏态(右偏)├─ 自由度:df = n-1├─ 应用:总体方差推断、分类资料分析└─ 可加性:χ²(m) + χ²(n) = χ²(m+n)
4.5.2 卡方分布应用
卡方统计量:χ² = Σ((O-E)²/E)其中:- O:观察频数- E:期望频数自由度计算:ν = (行数-1) × (列数-1)
4.6 F分布
4.6.1 F分布定义
两个卡方分布变量之比的分布。
F分布特点│├─ 形状:正偏态├─ 参数:两个自由度 df₁(分子), df₂(分母)├─ 应用:方差齐性检验、方差分析└─ 关系:F(α, df₁, df₂) = 1/F(1-α, df₂, df₁)
第5章:参数估计
5.1 点估计
5.1.1 概念
点估计:用样本数据计算出一个数值,作为总体参数的估计值。
5.1.2 估计量评价标准
5.2 区间估计
5.2.1 置信区间的概念
置信区间:包含未知总体参数的概率区间。
置信区间的解读│├─ 95%置信区间含义:│ └─ 100次抽样构建的100个置信区间中,│ 约95个包含总体参数真值│├─ 常用置信水平:│ ├─ 90% CI│ ├─ 95% CI(最常用)│ └─ 99% CI│└─ 注意: ├─ 置信区间不是"有95%的概率包含真值" └─ 总体参数要么在区间内,要么不在
5.2.2 总体均数的置信区间
已知σ时(大样本):
μ的95%CI = x̄ ± 1.96 × (σ/√n)
未知σ时(小样本):
μ的95%CI = x̄ ± tα/2(n-1) × (s/√n)
5.2.3 总体率的置信区间
大样本时(np≥5且n(1-p)≥5):
π的95%CI = p̂ ± 1.96 × √(p̂(1-p̂)/n)
小样本时(精确法):
查二项分布表获得精确置信区间
5.2.4 置信区间与假设检验的关系
| |
|---|
| 95% CI不包含0 | |
| 95% CI包含0 | |
| 99% CI不包含0 | |
第6章:假设检验
6.1 假设检验基本原理
6.1.1 反证法思想
假设检验步骤│├─ 1. 建立假设│ ├─ H₀(原假设/无效假设):通常是"无差异"或"无效"│ └─ H₁(备择假设):通常是"有差异"或"有效"│├─ 2. 选择检验水准 α│ ├─ α = 0.05(常规)│ └─ α = 0.01(需更高置信度)│├─ 3. 计算检验统计量│ └─ 根据数据选择:t值、χ²值、F值、z值等│├─ 4. 确定P值,作出推断│ ├─ P < α → 拒绝H₀,有统计学意义│ └─ P ≥ α → 不拒绝H₀,无统计学意义│└─ 5. 结合专业意义解释结果
6.1.2 单侧检验与双侧检验
双侧检验:研究者只关心是否相同,不关心谁大谁小
单侧检验:研究者不仅考虑有无差异,更关心差异的方向
选择原则:- 专业背景支持方向性假设 → 单侧检验- 不确定方向或只关心差异 → 双侧检验- 双侧检验较保守、稳妥
6.2 两类错误
错误类型矩阵 真实情况 H₀为真 H₀为假检验 拒绝H₀ Ⅰ类错误(α) 正确结果 不拒绝H₀ 正确 Ⅱ类错误(β)
检验效力(Power):1-β,正确拒绝错误H₀的概率。
检验效力影响因素│├─ α增大 → β减小 → Power增大├─ 样本量n增大 → 标准误减小 → Power增大├─ 效应量增大 → 更容易检测到差异 → Power增大└─ 总体变异减小 → 标准误减小 → Power增大
6.3 P值的正确理解
⚠️ P值不等于效应大小
P值反映的真正含义:
- 不能告诉你效应有多大、临床是否重要、结果是否可重复
正确报告方式:
降压效果:-12 mmHg(95% CI: -16 to -8 mmHg),P < 0.001
P值常见误解:
6.4 假设检验注意事项
- 资料可比性
- 方法选择
- 统计学意义≠专业意义
- 结论不能绝对化
- P值附近慎重
第二部分:统计推断方法
第7章:t检验
7.1 t检验概述
7.1.1 适用条件
共同条件:
7.1.2 t检验类型
t检验家族│├─ 单样本t检验│ └─ 样本均数与已知总体均数比较│├─ 两独立样本t检验│ └─ 两组独立样本均数比较│├─ 配对样本t检验│ └─ 配对样本或自身前后比较│└─ 校正t检验(Welch's t检验) └─ 方差不齐时使用
7.2 单样本t检验
7.2.1 适用场景
7.2.2 公式
t = (x̄ - μ₀) / (s/√n)其中:- x̄:样本均数- μ₀:已知总体均数(检验值)- s:样本标准差- n:样本量自由度:df = n-1
7.3 两独立样本t检验
7.3.1 适用场景
7.3.2 公式
t = (x̄₁ - x̄₂) / Sx̄₁-x̄₂其中:- Sx̄₁-x̄₂ = √[s²c(1/n₁ + 1/n₂)]- s²c = [(n₁-1)s₁² + (n₂-1)s₂²]/(n₁+n₂-2)(合并方差)自由度:df = n₁ + n₂ - 2
7.3.3 方差不齐时的校正
Levene检验:检验两组方差是否齐性(P>0.05为齐性)
Welch’s t检验:
t' = (x̄₁ - x̄₂) / √(s₁²/n₁ + s₂²/n₂)校正自由度:df = [(s₁²/n₁ + s₂²/n₂)²] / [(s₁²/n₁)²/(n₁-1) + (s₂²/n₂)²/(n₂-1)]
7.4 配对样本t检验
7.4.1 适用场景
7.4.2 公式
t = d̄ / (sd/√n)其中:- d̄:差值的均数- sd:差值的标准差- n:配对数自由度:df = n-1
7.5 SPSS操作指南
7.5.1 独立样本t检验
操作路径:分析 → 比较均值 → 独立样本T检验对话框设置:1. 检验变量:放入要比较的变量2. 分组变量:放入分组变量,点击"定义组" - 组1:输入第一组编码(如0) - 组2:输入第二组编码(如1)3. 点击确定结果解读:1. 先看Levene检验P值 - P > 0.05:方差齐性,看第一行t检验结果 - P ≤ 0.05:方差不齐,看第二行(校正t'检验结果)2. 再看t检验P值3. 报告:t值、自由度、P值、均数差值、95%CI
7.5.2 配对样本t检验
操作路径:分析 → 比较均值 → 配对样本T检验对话框设置:1. 选入配对变量(成对选入)2. 点击确定结果解读:1. 看配对差值的均数和标准差2. 看t值、自由度和P值3. 报告:配对差值均数±标准差、t值、P值
第8章:方差分析
8.1 方差分析概述
8.1.1 基本思想
方差分析(ANOVA):比较多组(≥3)样本均数,判断各组总体均数是否有差异。
方差分解思想│├─ 总变异 = 组间变异 + 组内变异│├─ 组间变异:反映处理因素效应 + 随机误差│└─ 组内变异:反映随机误差(个体差异)F = MS组间 / MS组内- F值大 → 组间变异大 → 处理因素有作用- F值小 → 组间变异小 → 处理因素无作用
8.1.2 方差分析类型
方差分析家族│├─ 单因素ANOVA│ └─ 一个分组因素(如药物剂量)│├─ 两因素ANOVA│ └─ 两个分组因素(如药物类型 + 剂量)│ 可分析主效应和交互作用│├─ 重复测量ANOVA│ └─ 同一对象多次测量(如治疗前后多个时间点)│├─ 协方差分析(ANCOVA)│ └─ 控制混杂因素后比较│└─ 多元方差分析(MANOVA) └─ 多个结局指标同时比较
8.2 完全随机设计方差分析
8.2.1 适用条件
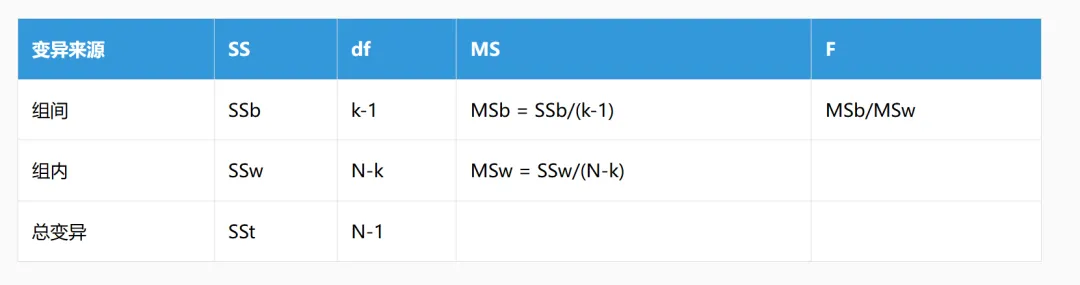
8.2.2 ANOVA表
8.3 两两比较方法
8.3.1 多重比较问题
当ANOVA拒绝H₀后,需要知道具体哪些组之间有差异。
多重比较校正必要性│├─ 比较次数:k(k-1)/2├─ 若每次比较α=0.05,5组需要10次比较│└─ 校正方法: ├─ Ⅰ类错误膨胀:α' = 1-(1-α)^(比较次数) │ 10次比较:α' ≈ 0.40 └─ 需要多重比较校正
8.3.2 常用两两比较方法
| | |
|---|
| Bonferroni | | |
| Tukey HSD | | |
| SNK-q检验 | | |
| Dunnett-t | | |
| LSD | | |
8.4 随机区组设计方差分析
8.4.1 设计概述
随机区组设计(Randomized Block Design):将受试对象按对效应指标有影响的非研究因素配成区组,每个区组内有k个受试对象随机分配到k个处理组。
设计特点│├─ 按两个因素分组(区组因素 + 处理因素)├─ 区组内受试对象同质性好├─ 与完全随机设计相比更好地控制混杂因素└─ 缺点:区组内受试对象数需与处理数相等
8.4.2 变异分解
SS总 = SS处理 + SS区组 + SS误差自由度:ν总 = ν处理 + ν区组 + ν误差ν总 = b×k - 1ν处理 = k - 1ν区组 = b - 1ν误差 = (k-1)(b-1)
8.5 重复测量方差分析
8.5.1 适用场景
8.5.2 分析内容
重复测量ANOVA分析内容│├─ 时间效应:各时间点均数是否有差异├─ 组间效应:各处理组均数是否有差异└─ 交互效应:时间×组别交互作用
8.6 SPSS操作指南
8.6.1 单因素ANOVA
操作路径:分析 → 比较均值 → 单因素ANOVA对话框设置:1. 因变量列表:放入要比较的变量2. 因子:放入分组变量3. 选项: - 勾选"描述性"、"方差齐性检验"4. 两两比较: - 勾选"Tukey"、"Bonferroni"5. 点击确定结果解读:1. 先看方差齐性检验(P>0.05方差不齐时用校正F)2. 看ANOVA表F值和P值3. 若P<0.05,看两两比较结果
8.6.2 重复测量ANOVA
操作路径:分析 → 一般线性模型 → 重复测量设置步骤:1. 主体内因子:定义测量时间点(如3个时间点)2. 主体内变量:放入各时间点的变量3. 主体间因子:放入分组变量4. 选项:勾选"描述统计"、"效应量估算"5. 点击确定
第9章:卡方检验与非参数检验
9.1 卡方检验
9.1.1 适用条件
9.1.2 卡方检验类型
卡方检验家族│├─ 四格表χ²检验│ └─ 2×2表,两组率的比较│├─ 行×列表χ²检验│ ├─ 多组率比较(R×2表)│ └─ 构成比比较(R×C表)│├─ 配对χ²检验(McNemar检验)│ └─ 配对设计的两分类数据│└─ χ²分割法 └─ 多个样本率的两两比较
9.1.3 四格表χ²检验
公式:
χ² = Σ(O-E)²/E其中:- O:观察频数- E:期望频数 = (行合计×列合计)/总合计自由度:df = (行数-1)×(列数-1) = 1
连续性校正(Yates correction)(样本量较小时使用):
χ² = Σ(|O-E|-0.5)²/E
适用条件:
9.1.4 配对χ²检验(McNemar检验)
适用场景:同一批患者用两种诊断方法的结果比较。
配对χ²检验表 方法B 阳性 阴性方法A 阳性 a b 阴性 c d
公式:
χ² = (|b-c|-1)²/(b+c)
条件:b + c ≥ 40,否则用精确概率法
9.2 Fisher精确检验
9.2.1 适用条件
9.2.2 原理
直接计算观察频数及更极端情况出现的概率:
P = [a+b]![c+d]![a+c]![b+d]! / (a!b!c!d!N!)
9.3 非参数检验
9.3.1 适用条件
9.3.2 非参数检验vs参数检验
9.3.3 常用非参数检验
Wilcoxon符号秩检验:
目的:比较配对样本或单样本中位数原理:比较各观测值与中位数的正负离差秩和
Mann-Whitney U检验:
目的:比较两独立样本原理:比较两组秩次分布
Kruskal-Wallis H检验:
目的:比较多组(≥3)独立样本原理:比较各组秩次分布
Friedman检验:
目的:随机区组设计的多个样本比较原理:配伍组内编秩,比较各处理组秩和
9.4 SPSS操作指南
9.4.1 卡方检验
操作路径:分析 → 描述统计 → 交叉表对话框设置:1. 行:放入分组变量2. 列:放入结果变量3. 统计量:勾选"卡方"4. 单元格:勾选"实测"、"期望"频数,勾选"行百分比"5. 点击确定
9.4.2 Fisher精确检验
操作路径:分析 → 描述统计 → 交叉表设置:1. 同卡方检验步骤2. 点击精确,勾选"精确"(默认计算)3. 点击确定
第10章:相关与回归分析
10.1 相关分析
10.1.1 Pearson相关系数
适用:双变量正态分布计量资料公式:r = Σ(xi-x̄)(yi-ȳ) / √[Σ(xi-x̄)²Σ(yi-ȳ)²]取值范围:-1 ≤ r ≤ 1
相关系数解读:
⚠️ 相关≠因果
10.1.2 Spearman秩相关系数
适用:不满足正态分布的资料、等级资料计算:将数据转换为秩次,计算秩次间的Pearson相关系数符号:rs,表示相关方向
10.2 直线回归分析
10.2.1 回归方程
目的:描述两变量间的数量依存关系方程:Ŷ = a + bX其中:- b = Σ(xi-x̄)(yi-ȳ) / Σ(xi-x̄)²(回归系数)- a = ȳ - bx̄(截距)回归系数解读:- b > 0:X增加,Y增加- b < 0:X增加,Y减少- b = 0:X与Y无直线关系
10.2.2 适用条件
10.3 多元线性回归
10.3.1 模型
目的:分析多个自变量与一个连续因变量的数量关系方程:Ŷ = b₀ + b₁X₁ + b₂X₂ + ... + bpXp用途:- 控制混杂因素- 识别独立影响因素- 预测
10.3.2 多重共线性诊断
方差膨胀因子(VIF):
VIF = 1/(1-R²)VIF > 10:存在多重共线性
容忍度(Tolerance):
Tolerance = 1/VIFTolerance < 0.1:存在多重共线性
10.4 SPSS操作指南
10.4.1 相关分析
操作路径:分析 → 相关 → 双变量对话框设置:1. 放入变量2. 选择相关系数: - Pearson(正态计量资料) - Spearman(偏态或等级资料)3. 显著性检验:双侧4. 点击确定
10.4.2 线性回归
操作路径:分析 → 回归 → 线性对话框设置:1. 因变量:放入Y变量2. 自变量:放入X变量3. 方法:Enter(全部进入)4. 统计量: - 勾选"回归系数"的"估算值"、"置信区间" - 勾选"模型拟合"、"共线性诊断"5. 点击确定
第三部分:高级统计分析方法
第11章:Logistic回归
11.1 Logistic回归概述
11.1.1 适用条件
| |
|---|
| 二分类(也适用于多项Logistic、有序Logistic) |
| |
| |
11.1.2 模型原理
方程:logit(P) = ln[P/(1-P)] = b₀ + b₁X₁ + ... + bpXp其中:- P:阳性结局的概率- b₀:截距- b₁,...,bp:回归系数优势比(OR)计算:OR = exp(b)OR解读:- OR = 1:无影响- OR > 1:危险因素- OR < 1:保护因素
11.2 Logistic回归类型
Logistic回归家族│├─ 二元Logistic回归│ └─ 因变量为二分类│├─ 有序Logistic回归│ └─ 因变量为有序多分类│├─ 多项Logistic回归│ └─ 因变量为无序多分类│└─ 条件Logistic回归 └─ 配对病例对照研究
11.3 变量筛选方法
| | |
|---|
| 前向选择(Forward) | | |
| 后向剔除(Backward) | | |
| 逐步法(Stepwise) | | |
| Enter(强制纳入) | | |
11.4 模型评价
11.4.1 模型拟合评价
11.4.2 预测能力评价
| | |
|---|
| | |
| | |
| | |
| | 0.5-0.7较低,0.7-0.9中等,>0.9较高 |
11.5 SPSS操作指南
操作路径:分析 → 回归 → 二元Logistic对话框设置:1. 因变量:放入结局变量(1=阳性,0=阴性)2. 协变量:放入自变量3. 方法:选择Enter/Wald/Stepwise等4. 分类协变量:若有无序分类变量,在此定义5. 选项: - 勾选"EXP(B)的置信区间"(95%) - 勾选"Hosmer-Lemeshow拟合度"6. 点击确定
第12章:生存分析
12.1 生存分析基本概念
12.1.1 生存数据特点
12.1.2 基本函数
| | |
|---|
| 生存函数 S(t) | | |
| 风险函数 h(t) | | |
| 累计风险函数 H(t) | | |
12.2 Kaplan-Meier生存曲线
12.2.1 方法原理
Kaplan-Meier法│├─ 原理:分时间段计算生存概率├─ 适用:随访时间不等、截尾数据├─ 生存率计算:│ S(t) = Π(ti≤t) (ni-di)/ni│ 其中:ni为ti时刻的有效观察数│ di为ti时刻的死亡数└─ 中位生存时间:S(t)=0.5对应的时间
12.2.2 生存曲线比较(Log-rank检验)
Log-rank检验│├─ 目的:比较两条或多条生存曲线是否有差异├─ 原理:比较各组在各时间点的观察死亡数与期望死亡数├─ H₀:各组的生存曲线相同└─ χ²检验:χ² = ΣΣ(观察-期望)²/期望
12.3 Cox比例风险回归
12.3.1 模型原理
Cox回归(比例风险模型)│├─ 方程:h(t) = h₀(t) × exp(b₁X₁ + b₂X₂ + ... + bpXp)├─ 特点:半参数模型│ ├─ 不需要知道基线风险函数h₀(t)│ └─ 假设比例风险(PH假设)└─ 风险比(HR)= exp(b)
12.3.2 PH假设检验
12.3.3 HR解读
示例:HR = 2.5(某危险因素)解读:该因素阳性者的死亡风险是阴性者的2.5倍HR < 1:保护因素HR = 1:无影响HR > 1:危险因素
12.4 竞争风险模型
竞争风险概念:当存在其他结局事件可能阻止感兴趣事件发生时,需用竞争风险模型。
12.5 SPSS操作
Kaplan-Meier法:操作路径:分析 → 生存函数 → Kaplan-Meier- 时间:放入生存时间- 状态:放入结局变量,定义事件(1=死亡)- 因子:放入分组变量- 比较因子:勾选"对数秩"- 选项:勾选"生存分析表"、"生存函数"Cox回归:操作路径:分析 → 生存函数 → Cox回归- 时间:放入生存时间- 状态:放入结局变量,定义事件- 协变量:放入自变量- 方法:Enter/Wald/Forward等- 选项:勾选"CI for exp(B)"(95%)
第13章:多元统计分析方法
13.1 主成分分析(PCA)
13.1.1 基本思想
主成分分析│├─ 目的:用少数综合指标代替多个原始变量├─ 原理:降维,将相关变量转换为不相关的主成分├─ 主成分定义:│ └─ 第一主成分:方差最大│ └─ 第二主成分:与第一主成分正交,方差次大└─ 选择标准:累计贡献率≥80-85%
13.1.2 医学应用
13.2 因子分析
13.2.1 基本思想
因子分析│├─ 目的:探索变量背后的潜在因子结构├─ 与PCA区别:│ ├─ PCA:主成分是原始变量的线性组合│ └─ 因子分析:原始变量是因子的线性组合├─ 模型:X = μ + AF + ε│ ├─ A:因子载荷矩阵│ └─ F:公共因子,ε:特殊因子└─ 因子旋转:使因子更易解释(Varimax最大方差旋转)
13.2.2 医学应用
13.3 聚类分析
13.3.1 聚类方法
聚类分析│├─ 系统聚类法(层次聚类)│ ├─ 距离定义:欧氏距离、马氏距离│ └─ 类间距离:最近距离法、最远距离法、类平均法、Ward法│├─ 快速聚类法(K-means)│ ├─ 指定K个初始聚类中心│ └─ 迭代重新分类│└─ 有序样品聚类(最优分割法) └─ 用于有序数据的聚类
13.3.2 医学应用
13.4 判别分析
判别分析│├─ 目的:根据已知分类建立判别函数,判别新样本归属├─ 方法:│ ├─ 距离判别:计算样本与各类中心的距离│ ├─ Bayes判别:计算后验概率│ └─ Fisher判别:最大化类间距离/类内距离└─ 验证:刀切法(Jackknife)、交叉验证
13.5 典型相关分析
典型相关分析│├─ 目的:研究两组变量之间的相关性├─ 原理:分别在两组变量中提取典型变量│ └─ 使两个典型变量之间的相关最大├─ 典型变量:是原始变量的线性组合└─ 应用:综合评估两组变量间的整体关联
13.6 方法对比
第14章:高级统计专题
14.1 机器学习方法在医学研究中的应用
14.1.1 常用机器学习方法
| | |
|---|
| 线性回归 | | |
| Logistic回归 | | |
| 决策树 | | |
| 随机森林 | | |
| 支持向量机 | | |
| 神经网络 | | |
| 生存分析(Cox) | | |
14.1.2 模型评价指标
14.2 贝叶斯统计
贝叶斯统计│├─ 核心公式:P(θ|data) ∝ P(data|θ) × P(θ)│ ├─ P(θ):先验分布│ ├─ P(data|θ):似然函数│ └─ P(θ|data):后验分布│├─ 与频率学派区别:│ ├─ 频率派:将参数视为固定值│ └─ 贝叶斯派:将参数视为随机变量│└─ MCMC方法:马尔可夫链蒙特卡洛法,用于复杂后验分布的抽样
14.3 因果推断
因果推断主要框架│├─ 潜在结果框架(Rubin因果模型)│ ├─ 因果效应:E(Y₁) - E(Y₀)│ ├─ 核心问题:无法同时观测到Y₁和Y₀│ └─ 识别策略:随机化、匹配、工具变量│├─ 因果图(Causal Diagram)│ ├─ DAG(有向无环图)│ └─ 区分混杂、碰撞、管道│└─ 结构因果模型(Pearl因果模型)
14.4 孟德尔随机化
孟德尔随机化(MR)│├─ 原理:利用基因型作为工具变量推断因果关系│├─ 基因型作为工具变量的优势:│ ├─ 在配子形成时随机分配(类似RCT)│ ├─ 通常与混杂因素无关│ └─ 先于疾病发生(时间顺序正确)│├─ 三基因假设:│ ├─ 1. 相关性:基因与暴露强相关│ ├─ 2. 独立性:基因与混杂无关│ └─ 3. 排他性:基因只通过暴露影响结局│└─ 应用:从GWAS汇总数据推断因果
第四部分:研究设计与样本量估算
第15章:实验设计
15.1 实验设计基本原则
15.1.1 随机化原则
15.1.2 对照原则
15.1.3 盲法原则
15.2 常用实验设计类型
15.2.1 完全随机设计
完全随机设计│├─ 特点:最简单,各组样本量可相等或不等├─ 优点:设计简单、实施容易├─ 缺点:混杂因素可能不均衡└─ 分析方法:t检验、ANOVA
15.2.2 配对设计
配对设计│├─ 特点:配对后随机分配├─ 配对方式:│ ├─ 自身配对(前后比较)│ ├─ 同源配对(双胞胎)│ └─ 条件配对(年龄、性别等匹配)├─ 优点:减少个体差异└─ 分析方法:配对t检验
15.2.3 随机区组设计
随机区组设计│├─ 特点:先分区组,区组内随机分配├─ 区组因素:如医院、年龄段├─ 优点:保持区组内同质性└─ 分析方法:区组设计的ANOVA
15.2.4 交叉设计
交叉设计(Washout设计)│├─ 特点:每个受试者先后接受两种或多种处理├─ 洗脱期:消除前一种处理的影响├─ 优点:减少样本量└─ 分析方法:交叉设计的ANOVA
第16章:调查设计
16.1 抽样方法
16.1.1 概率抽样
16.2 问卷设计要点
第17章:样本量估算
17.1 样本量估算重要性
⚠️ 样本量不是越多越好
17.2 样本量估算要素
17.3 常用样本量估算公式
17.3.1 两样本均数比较
n = 2 × [(Zα/2 + Zβ)² × σ²] / δ²其中:- Zα/2:双侧α对应的Z值(α=0.05时,Z=1.96)- Zβ:单侧β对应的Z值(β=0.2时,Z=0.84)- σ:两总体标准差(假设相等)- δ:两总体均数之差
17.3.2 两样本率比较
n = [(Zα/2 + Zβ)² × (p₁(1-p₁) + p₂(1-p₂))] / (p₁-p₂)²其中:- p₁, p₂:两总体率- δ = p₁ - p₂
17.3.3 配对设计
n = [(Zα/2 + Zβ)² × σd²] / δd²其中:- σd:配对差值的标准差- δd:配对差值的均数
17.4 样本量估算注意事项
第五部分:统计软件实操
第18章:SPSS统计实战
18.1 SPSS界面介绍
SPSS界面组成│├─ 数据视图:类似Excel,存放原始数据│ └─ 行=个案(case)│ └─ 列=变量(variable)│├─ 变量视图:定义变量属性│ ├─ 名称(Name)│ ├─ 类型(Type)│ ├─ 标签(Label)│ ├─ 值标签(Values)│ └─ 度量标准(Measure)│├─ 输出窗口:显示分析结果│└─ 语法窗口:编写和运行SPSS命令
18.2 统计检验实战
18.2.1 独立样本t检验
结果报告模板:治疗组血压为 145.2 ± 12.3 mmHg,对照组为 152.8 ± 11.8 mmHg,两组差异有统计学意义(t=3.45, P=0.001),治疗组血压低于对照组。
18.2.2 配对样本t检验
结果报告模板:治疗前血压为 165.5 ± 15.2 mmHg,治疗后为 145.2 ± 12.3 mmHg,差值为 20.3 ± 8.5 mmHg,差异有统计学意义(t=8.92, P<0.001)。
18.2.3 卡方检验
结果报告模板:实验组有效率为 78.5%(78/99),对照组有效率为 62.6%(62/99),两组差异有统计学意义(χ²=5.87, P=0.015)。
18.3 回归分析实战
18.3.1 Logistic回归报告模板
结果报告模板:以是否发生心血管事件为因变量,进行多因素Logistic回归分析,结果如下:变量 B SE Wald χ² P值 OR(95%CI)年龄(岁) 0.05 0.02 6.25 0.012 1.05(1.01-1.09)高血压(是) 0.78 0.35 4.97 0.026 2.18(1.10-4.32)糖尿病(是) 0.92 0.38 5.85 0.016 2.51(1.19-5.29)BMI(kg/m²) 0.08 0.04 4.00 0.045 1.08(1.00-1.17)模型评价:χ²=28.65, P<0.001,Hosmer-Lemeshow P=0.567预测符合率:73.2%
18.3.2 Cox回归报告模板
结果报告模板:Cox回归分析结果:变量 B SE Wald χ² P值 HR(95%CI)年龄(岁) 0.03 0.01 9.00 0.003 1.03(1.01-1.05)肿瘤分期(III期) 1.25 0.32 15.26 <0.001 3.49(1.87-6.51)手术类型(根治) -0.85 0.28 9.22 0.002 0.43(0.25-0.74)模型评价:C-statistics = 0.72PH假设检验:均满足(P>0.05)
第19章:R语言统计实战
19.1 R语言基础
# 查看当前工作目录getwd()# 设置工作目录setwd("D:/data")# 安装包(首次使用)install.packages("tidyverse")# 加载包library(tidyverse)library(ggplot2)library(survival)library(survminer)
19.2 数据导入
# 导入CSVdata <- read.csv("data.csv", header =TRUE)# 导入Excellibrary(readxl)data <- read_excel("data.xlsx", sheet =1)# 导入SPSSlibrary(haven)data <- read_sav("data.sav")
19.3 统计检验
# t检验t.test(weight ~ group, data = data)# 独立样本t.test(before, after, paired =TRUE, data = data)# 配对样本# 方差分析aov(outcome ~ factor, data = data)%>% summary()# 卡方检验chisq.test(table(data$group, data$outcome))fisher.test(table(data$group, data$outcome))# Fisher精确检验# 非参数检验wilcox.test(outcome ~ group, data = data)# Mann-Whitney Ukruskal.test(outcome ~ group, data = data)# Kruskal-Wallis H
19.4 回归分析
# 线性回归lm(outcome ~ var1 + var2 + var3, data = data)%>% summary()# Logistic回归glm(outcome ~ var1 + var2, data = data, family = binomial())%>% summary()# 计算OR和95%CIexp(cbind(OR = coef(model), confint(model)))# Cox回归library(survival)coxph(Surv(time, status)~ var1 + var2, data = data)%>% summary()
19.5 生存分析
library(survival)library(survminer)# Kaplan-Meier生存曲线fit <- survfit(Surv(time, status)~ group, data = data)# 绘制生存曲线ggsurvplot(fit, data = data, pval =TRUE,# 显示P值 conf.int =TRUE,# 显示置信区间 risk.table =TRUE,# 显示风险表 ggtheme = theme_minimal())# Log-rank检验survdiff(Surv(time, status)~ group, data = data)
第20章:SAS统计实战基础
20.1 SAS基础
SAS程序结构│├─ DATA步:数据导入和整理│ └─ PROC步:统计分析│├─ 基本语句:│ ├─ DATA 数据集名;│ ├─ INPUT 变量列表;│ ├─ CARDS;│ ├─ PROC 过程名;│ └─ RUN;│└─ 注释:/* 注释内容 */
20.2 数据导入
/* 方法1:直接输入 */DATA clinic;INPUT id age sex $ bps bpd group $;CARDS;001 56 M 145 92 treat002 63 F 158 95 control...;RUN;/* 方法2:导入外部数据 */PROC IMPORT OUT=clinic DATAFILE="D:\data.csv" DBMS=CSV REPLACE;RUN;
20.3 描述性统计
/* 计量资料 */PROC MEANS DATA=clinic MEAN STD MIN MAX; VAR age bps bpd;RUN;/* 频数表 */PROC FREQ DATA=clinic; TABLES sex group;RUN;
20.4 统计检验
/* t检验 */PROC TTEST DATA=clinic; CLASS group; VAR bps;RUN;/* 卡方检验 */PROC FREQ DATA=clinic; TABLES group*outcome / CHISQ;RUN;/* Logistic回归 */PROC LOGISTIC DATA=clinic; MODEL outcome = age bps bpd group;RUN;
第六部分:国际报告规范与质量控制
第21章:国际报告规范
21.1 CONSORT规范(随机对照试验)
核心条目
报告要点
CONSORT报告要点│├─ 标题包含"RCT"字样├─ 摘要结构化(目的、方法、结果、结论)├─ 明确研究目的├─ 详细描述纳入排除标准├─ 干预措施详细描述├─ 主要和次要结局指标明确├─ 样本量计算详细说明├─ 随机化方法具体描述├─ 盲法实施情况详细报告├─ Flow图展示受试者流程└─ 所有分析方法的清晰描述
21.2 STROBE规范(观察性研究)
队列研究核心条目
21.3 PRISMA规范(系统评价/Meta分析)
21.4 STARD规范(诊断准确性研究)
第22章:统计质量控制
22.1 数据质量管理
22.1.1 数据录入与核对
22.1.2 数据清洗
数据清洗步骤│├─ 1. 缺失值检查│ └─ 缺失比例、缺失机制判断│├─ 2. 异常值识别│ ├─ 统计方法:IQR、Z分数│ └─ 专业判断:临床合理性│├─ 3. 数据转换│ ├─ 正态性转换│ └─ 标准化│└─ 4. 变量编码 ├─ 分类变量编码 └─ 创建衍生变量
22.2 分析质量控制
22.2.1 分析前检查
22.2.2 模型诊断
22.3 结果报告规范
22.3.1 统计结果报告模板
连续变量:
计量资料以 x̄ ± s 表示,组间比较采用t检验/方差分析。如:治疗组收缩压为 145.2 ± 12.3 mmHg,对照组为 152.8 ± 11.8 mmHg,差异有统计学意义(t=3.45, P=0.001)。
分类变量:
计数资料以n(%)表示,组间比较采用χ²检验/Fisher精确检验。如:实验组有效率为 78.5%(78/99),对照组有效率为 62.6%(62/99),差异有统计学意义(χ²=5.87, P=0.015)。
22.4 常见统计错误
附录:常用速查表
附录A:统计方法选择决策树
研究问题 → 数据类型 → 组数 → 设计 → 统计方法【计量资料比较】│├─ 单样本/配对│ ├─ 正态 → 单样本t检验 / 配对t检验│ └─ 非正态 → Wilcoxon符号秩检验│├─ 两组独立│ ├─ 正态+方差齐 → 独立样本t检验│ └─ 非正态/方差不齐 → Mann-Whitney U检验│├─ 三组及以上│ ├─ 正态+方差齐 → 单因素ANOVA → 两两比较Tukey/LSD│ └─ 非正态/方差不齐 → Kruskal-Wallis H检验│└─ 重复测量 ├─ 正态 → 重复测量ANOVA └─ 非正态 → Friedman检验【计数资料比较】│├─ 2×2表│ ├─ n≥40,E≥5 → χ²检验│ └─ n<40或E<5 → Fisher精确检验│├─ R×C表│ ├─ 无序 → χ²检验│ └─ 有序/等级 → Mann-Whitney / Kruskal-Wallis│└─ 配对设计 └─ 配对χ²检验 / McNemar检验【生存分析】│├─ 单因素 → Kaplan-Meier + Log-rank└─ 多因素 → Cox回归【诊断试验】│└─ ROC曲线 + AUC【回归分析】│├─ 因变量连续 → 多元线性回归├─ 因变量二分类 → Logistic回归└─ 因变量生存时间 → Cox回归
附录B:常用统计公式速查
| |
|---|
| |
| |
| |
| |
| |
| r = Σ(xi-x̄)(yi-ȳ)/√[Σ(xi-x̄)²Σ(yi-ȳ)²] | |
| |
| |
| |
附录C:样本量估算要点速查
附录D:常用统计软件快捷命令
SPSS快捷语法
/* 描述性统计 */DESCRIPTIVES VARIABLES=age bps bpd /STATISTICS=MEAN STDDEV MIN MAX./* 独立样本t检验 */T-TEST GROUPS=group(1,2) /VARIABLES=bps./* 卡方检验 */CROSSTABS /TABLES=group BY outcome /STATISTICS=CHISQ /CELLS=COUNT EXPECTED.
R常用函数速查
# 基础统计mean(x); sd(x); median(x); quantile(x)table(x); prop.table(x)# 检验t.test(); chisq.test(); cor.test()aov(); lm(); glm(); coxph()# 生存分析survfit(); survdiff(); ggsurvplot()# 包装library(dplyr)# 数据操作library(ggplot2)# 图形library(haven)# 导入SPSS/SAS/Statalibrary(survival)# 生存分析
附录E:参考资源
经典教材
在线资源
版权声明: 本教程整合自孙振球《医学统计学》、方积乾《生物统计学》、《卫生统计学》教材(人卫出版社)及相关统计学课程讲义。版本: v2.0 | 更新日期: 2026年4月
为了方便大家交流学习,本公众号已建立交流群,欢迎各位读者与我们一起探讨生物信息学分析、孟德尔随机化、机器学习、临床预测模型、医学统计学、及研究设计等知识。
公众号:Abel统计
微信号:Abel_Biostats
请扫码关注&加好友了解更多内容!