Mysql学习笔记六:表的查询select基础加强
- 2026-05-30 13:24:22
Mysql学习笔记六:表的查询select基础加强内容小结:where子句,group by子句,limit子句 代码使用:where子句中提及日期数据也可以运用比较运算符,模糊查询和升降序操作,group by子句与聚合函数的捆绑使用规律,以及having与where的区分,limit子句介绍了分页查询的两种基本形式 一、where条件子句说明 上篇文章Mysql学习笔记五末尾提及了where子句中常常会用到比较运算符和逻辑运算符,这里再进行一个补充, 下面是在sqlyog软件中操作得到的结果: 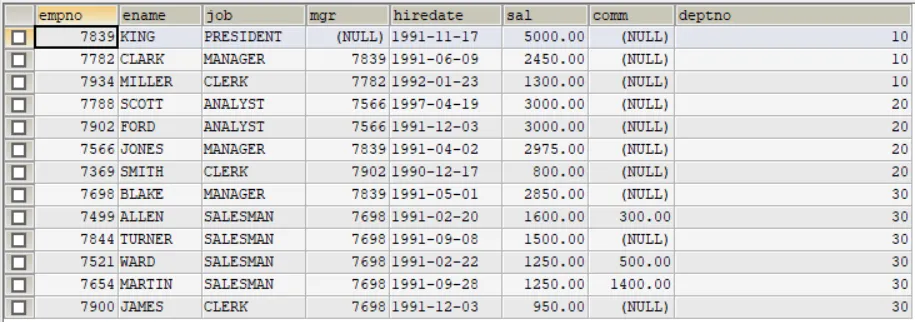
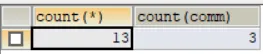
按部门排序,并进行升序操作 二、group by (1)显示每种岗位的雇员总数、平均工资。 (2)显示雇员总数,以及获得补助的员工数。 (3)显示管理者的总人数。 (4)显示雇员工资的最大差值。 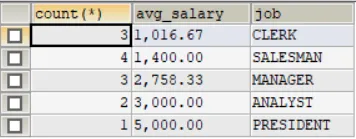

三、limit分页查询 limit是上篇内容中总结的完整 SELECT 语句里最后执行的子句。它的核心作用有两个,一是限制查询返回的数据条数,二是实现分页查询。因此它包含两个基本的语句 下面举个例子说明, 按雇员的id号升序取出,每页显示3条记录,请分别显示 第1页,第2页,第3页, 
第1页 
第2页 
第3页 四、多子句连用 上面已经介绍了select相关的子句及其用法,下面给出一个多子句联合使用的例子。
-- 使用where子句-- ?如何查找1992.1.1后入职的员工SELECT * FROM empWHERE hiredate > '1992-01-01';-- 如何使用like操作符 (模糊查询)-- %: 表示0到多个任意字符, _: 表示单个字符-- ?如何显示首字符为S的员工和工资SELECT ename, sal FROM empWHERE ename LIKE 'S%' ;-- ?如何显示第三个字符为大写o的所有员工的姓名和工资SELECT ename, sal FROM empWHERE ename LIKE '__o%';-- 如何显示没有上级的雇员的情况SELECT * FROM empWHERE mgr IS NULL-- 查询表结构DESC emp-- 使用order by子句, 默认为ASC升序-- ?如何按照部门号由低到高的排序【升序】,显示雇员信息SELECT * FROM empORDER BY deptno ASC;-- ? 按照部门号升序,且雇员工资降序排列,显示雇员信息SELECT * FROM empORDER BY deptno ASC, sal DESC;
GROUP BY 是mysql中进行分级统计操作的语句,即把表中「特征相同」的数据归为一组,然后对每一组做统计计算。核心要点是,GROUP BY 不能单独用,必须配合聚合函数做统计!常用 5 个聚合函数为COUNT(*)、SUM(字段)、AVG(字段)、MAX(字段)、MIN(字段)。下面来看四个例子:-- (1)显示每种岗位的雇员总数、平均工资。SELECT COUNT(*),FORMAT(AVG(sal),2) AS avg_salary,jobFROM empGROUP BY job
-- (2)显示雇员总数,以及获得补助的员工数。-- 思路:获得补助的雇员数,就是comm列为非null,就是count(列)-- 如果该列值为null,不会统计SELECT COUNT(*),COUNT(comm)FROM emp-- (2.1)拓展:统计没有获得补助的雇员数SELECT COUNT(*),COUNT(IF(comm IS NULL, 1, NULL))FROM empSELECT COUNT(*), COUNT(*)-COUNT(comm)FROM emp
-- (3)显示管理者的总人数。SELECT COUNT(DISTINCT mgr)FROM emp-- (4)显示雇员工资的最大差值。SELECT MAX(sal) - MIN(sal)FROM emp
其实上面的几个例子并没有完全围绕GROUP BY 来设计,反而给出了不少聚合函数的使用。
我们针对GROUP BY再补充两个要点,要点一是goup by子句如果要搭配筛选条件,过滤分组统计结果,其实就是用聚合函数作为条件,必须由having引导,因为having可以搭配聚合函数,而where则不能,where只可以过滤原始数据;要点二是,SELECT 选择要显示的字段,只能是ROUP BY 后面的分组列和聚合函数包裹的列。
SELECT COUNT(*),FORMAT(AVG(sal),2) AS avg_salary,jobFROM empGROUP BY job-- 提炼成标准语句SELECT 聚合函数, 分组列FROM 表名GROUP BY 分组列
-- 用法一,取前N条数据LIMIT 数字;-- 用法二,分页显示从第几条数据开始,一页显示多少条LIMIT 起始位置, 每页条数;
关于用法二中的参数,起始位置 = (当前页码 - 1) × 每页显示条数
-- 第1页SELECT * FROM empORDER BY empnoLIMIT 0, 3-- 第2页SELECT * FROM empORDER BY empnoLIMIT 3, 3-- 第3页SELECT * FROM empORDER BY empnoLIMIT 6, 3
select ... limit start, rows; 表示从start+1行开始取,取出rows行,start 从0开始计算
应用: 统计各个部门中哪些部门的平均工资avg大于1000,按照平均工资从高到低排序,并取出前两行记录。我们可以对这个问题进行拆解,
(1) 统计各个部门y的平均工资avg,需要group by
(2)并且大于1000的,需要having
(3)还要按照平均工资从高到低排序,需要order by
(4)取出前两行记录,需要 limit
SELECT deptno, AVG(sal) AS avg_salFROM empGROUP BY deptnoHAVING avg_sal > 1000ORDER BY avg_sal DESCLIMIT 0, 2
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

