前面已经了解了RLHF中的PPO/DPO算法,此处学习GRPO算法并基于此方法让模型产生一定的推理能力。
整体流程
在参考资料1-2中,DeepSeek提出了GRPO算法(字节优化GRPO提出了DAPO算法)。
整体和PPO算法的目标函数较为类似,在优势函数A、critic网络等子项进行了处理。

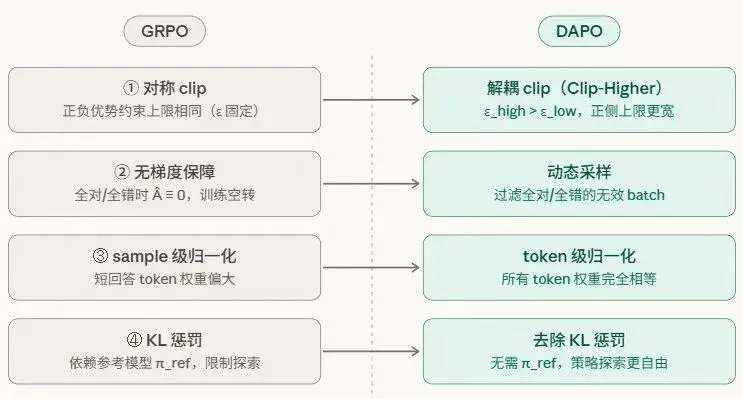
此处使用DAPO算法对Qwen2.5-3B-Instruct模型进行微调,使其具备一定的推理能力。
实现细节
数据集
Countdown-Tasks-3to4数据集:https://huggingface.co/datasets/asingh15/countdown_tasks_3to4
给定3-4个数字,通过基础的四则运算得到结果。
数据集有49万个问题-答案对。
训练细节
整体步骤


代码流程图
受限于单卡RTX5090的显存资源,训练时批次大小是32(每次选4个问题,每个问题8个回答)。
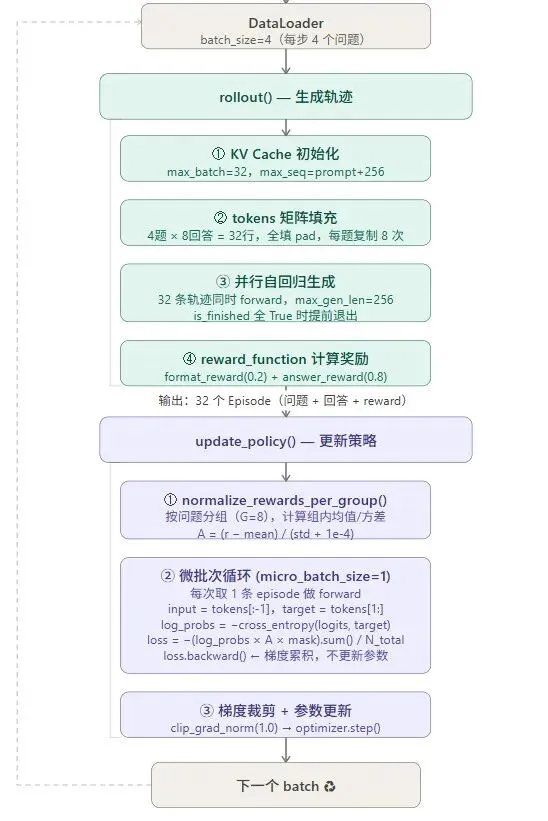
奖励设置
奖励由格式奖励和任务奖励两部分构成。

效果
考虑到使用单卡RTX5090将数据集过一遍需要10天以上,此处仅训练了1900-step后保存了模型参数(在1700-step处测试集得分最高)。
对比原始模型和1700-step模型,可以明显看到经过1700-step模型的推理能力更强。

参考
1.GRPO论文:《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Model》
2.DAPO论文:《DAPO: An Open-Source LLM Reinforcement Learning System at Scale》