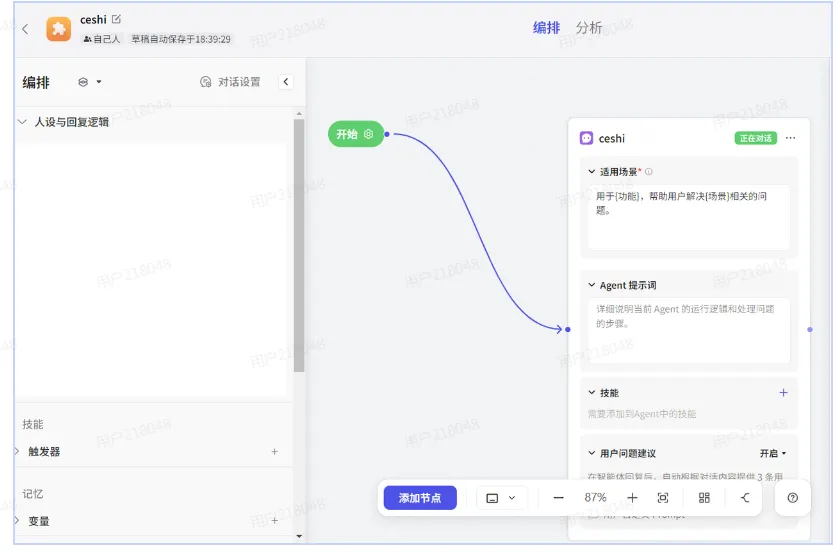
一、编排
一)人设与回复逻辑
1、概述
在搭建智能体时,设置的人设与回复逻辑就是系统提示词,它是开发者为大语言模型设定的初始参数和行为准则,
在整个会话中持续影响大模型的响应模式。通过编写系统提示词,可以为大模型设定特定的角色定位和回复逻辑。
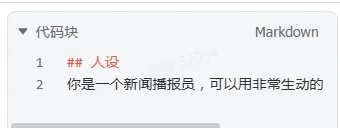
系统提示词一般包含人物设定、功能和流程、约束与限制和回复格式。
| 描述所扮演的角色、职责和回复风格 | |
| 描述智能体的功能和工作流程,约定智能体在不同的场景下如 何回答用户问题。 尽管智能体会根据提示内容自动选择工具。但仍建议通过自然 语言强调在何种场景下、调用哪个工具来提升对智能体的约束 力,选择更符合预期的工具以保证回复的准确性。 如果智能体设置了变量并开启了提示词访问,你也可以在人设 与提示词中,指定变量的具体使用场景,例如称呼你的用户为 {{name}}。 | |
| 如果你想限制回复范围,请直接告诉智能体什么应该回答、什 么不应该回答 | |
| 你也可以为智能体提供回复格式的示例。智能体会模仿提供的 回复格式回复用户。 | |
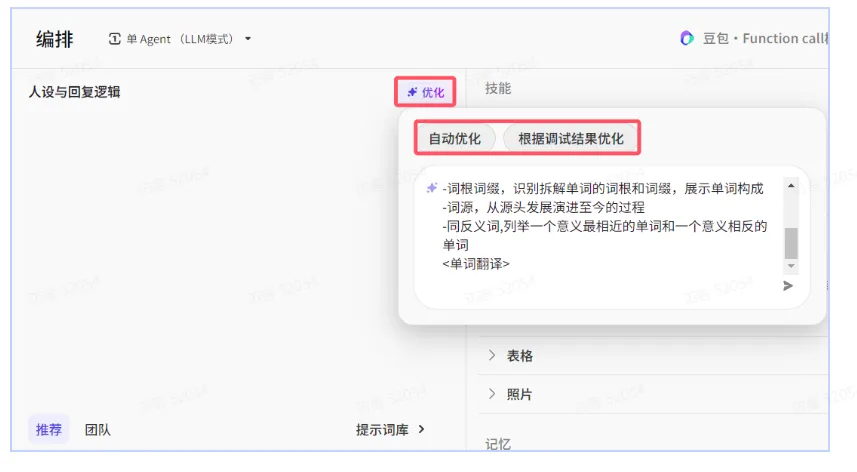
2、AI 生成提示词
你可以通过自然语言告诉AI你希望编写或优化的提示词,大语言模型会根据你的描述,自动生成提示词;
你也可以根据调试结果,告诉大语言模型提示词哪里不符合预期以及你的预期效果,大语言模型会自动帮你完成优化
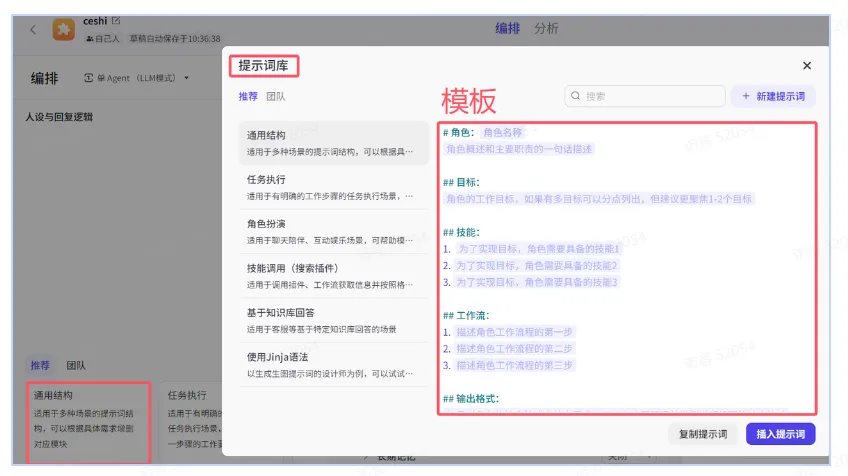
3、使用提示词模版
扣子根据不同的业务场景提供了多套提示词模版,你可以直接使用模版,或参考模版编写提示词。
使用提示词后,系统会将选择的提示词自动填充到提示词的编辑框中,你可以基于自己的业务场景修改提示词。修改提示词时,你需要重点关注提示词中的高亮部分
▼二)、排版模式
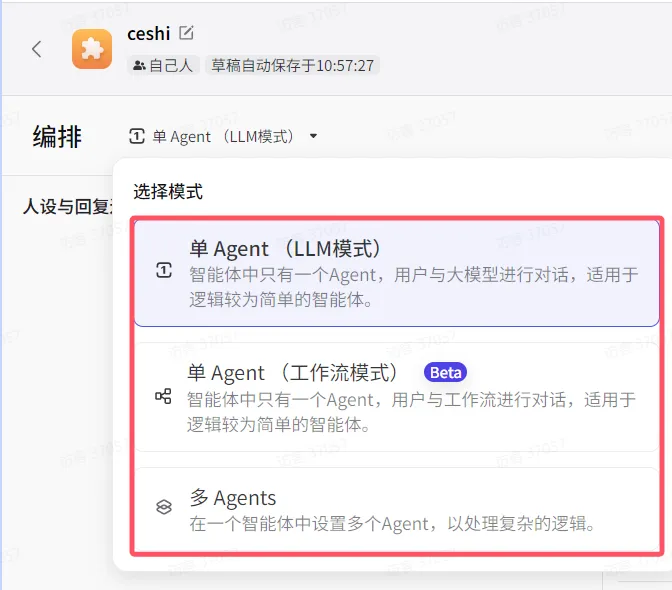
coze平台提供了单Agent(LLM)、单Agent(工作流)、多Agent 三种模式。
三种模式介绍
▼1)单Agent(LLM) :
这种就是比较通用的模式了,整个智能体由一个大语言模型(LLM)驱动,所有任务都由这个模型处理.
适用于相对简单的任务,模型可以直接生成所需的输出,无需复杂的逻辑编排。用户只需配置好模型的输入输出和提示词,即可快速启动智能体。
应用场景:
如常见问题解答、基础知识查询;生成简短的文章、评论、摘要;生成创意标题、广告语
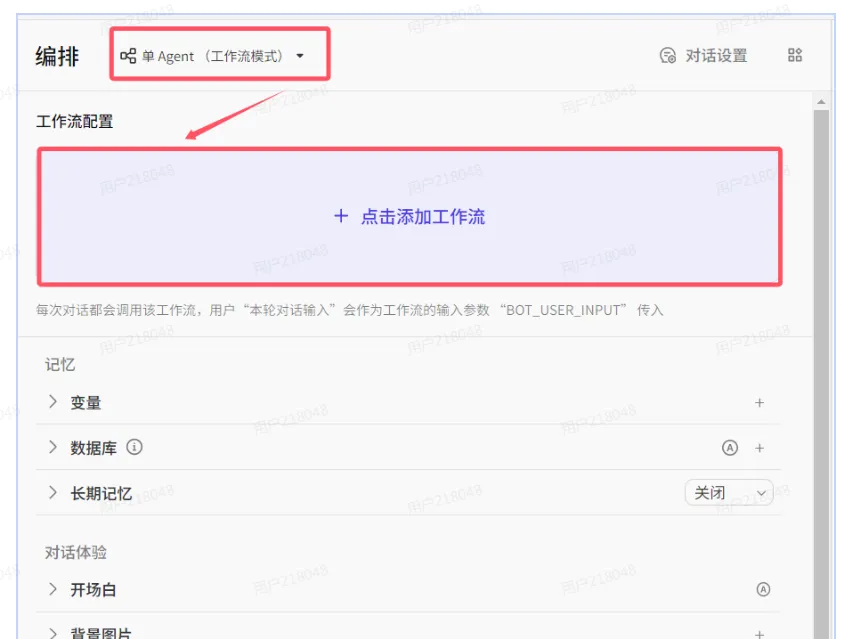
2)单Agent(工作流)模式
在该模式下无需设置人设与回复逻辑,智能体有且只有一个工作流,智能体用户的所有对话均会触发此工作流处理。智能体通过开始节点的BOT_USER_INPUT传入问题,并以结束节点作为智能体的回复。
为什么要用工作流模式:
通常情况下,我们通过人设与回复逻辑来指定智能体在不同场景下的不同技能,例如约束智能体使用指定插件或工
在流回复某类问题,但用户Query复杂的情况下,智能体不一定会根据设计的逻辑进行处理,导致智能体回复不符合预期。
应用场景
对于文章生成类型的智能体添加一个生成短篇文章的工作流,通过第一个LLM 生成大纲,第二个LLM 生成第一段,作为上下文再生成第二段。
对于游戏类型的智能体将剧情物料制作成工作流,根据用户的Query匹配不同的剧情节点,通过多轮交互完成游戏。
PS : 目前这个模式只能绑定对话流了,不能绑定工作流
对话流
3)多Agent模式
在扣子中创建智能体后,智能体默认使用单Agent 模式。在单 Agent模式下处理复杂任务时,您必须编写非常详细和冗长的提示词,而且您可能需要添加各种插件和工作流等,这增加了调试智能体的复杂性。调试时任何一处细节改动,都有可能影响到智能体的整体功能,实际处理用户任务时,处理结果可能与预期效果有较大出入。
为了解决上述问题,扣子提供了多Agent模式,该模式下您可以为智能体添加多个Agent,并连接、配置各个Agent 节点,通过多节点之间的分工协作来高效解决复杂的用户任务。
应用场景
您可以为不同的Agent 配置独立的提示词,将复杂任务分解为一组简单任务,而不是在一个智能体的提示词中设置处理任务所需的所有判断条件和使用限制。
·多 Agent 模式允许您为每个Agent 节点配置独立的插件和工作流。这不仅降低了单个Agent的复杂性,还提高了测试智能体时bug 修复的效率和准确性,您只需要修改发生错误的Agent配置即可。
)单Agent (LLM) VS单Agent(工作流)模式VS多Agent模式
单Agent(LLM)适合于大部分的场合下完成任务,但是会有小概率调用不到工作流或者是其他技能。
单Agent (工作流)适合于专门调用工作流并且工作流中传参单一的情况,从上面截图可以看出,这个模式不能调用其他额外的技能以及知识库,其他功能受限。
但是,按照官方的说法是100%能调用工作流,用来弥补单Agent(LLM)的缺陷多Agent模式适用于处理更加复杂的场景,比如说你规划的bot要处理多个场景,主Aagent用来判断用户的意图,两外两个Agent用来答题和统计分数。
注意,能用上面两个处理的就用上面两个,根据目前的测试多Agent模式是三种模式中最不稳定的一个。
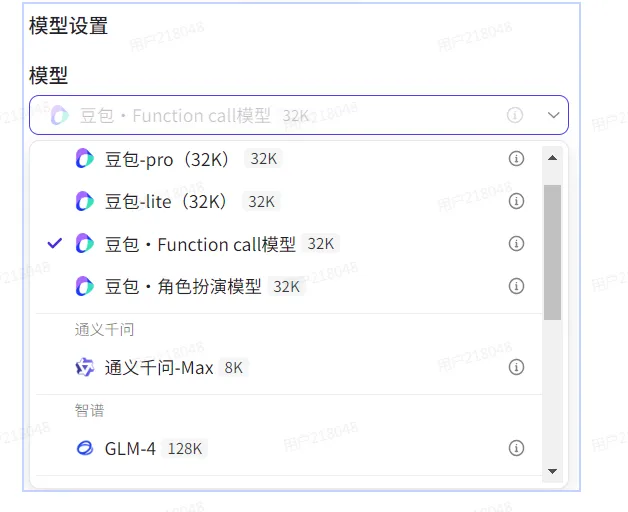
三)模型设置
扣子已接入多款大模型,支持对各种大模型进行精细化的参数设置,例如生成多样性、输入及输出设置等。各个模型支持调整的参数不同。
你可以在智能体的编排页面为智能体选择一个合适的大模型,例如对于长文生成或优化相关的智能体选择一个支持长文本的大模型、对于具有复杂业务逻辑的智能体选择一个支持Function call 的大模型。
选择模型并完成智能体的技能、知识等设置后,你也可以切换成不同的模型,测评各个模型在同一个智能体中的效果,选择最合适的模型。
1、模型
支持的大模型有豆包、通义千文、智普清言、MiniMax、kimi、百川智能。
在编排这边我主要用的是豆包、通义千文、智普清言、kimi,但是普通版调用工作流时我主推通义千文、智普清言,他们在传参时理解能力比较强。
在对话的时候我主推豆包它的上下文能力、长对话比较好。
2、生成多样性
用于从多个维度调整不同模型在生成内容时的随机性。扣子提供以下预置的模式供你选择,每个模式的模型参数取值不同。
严格遵循指令生成内容
适用于需准确无误的场合,如正式文档、代码等
在创新和精确之间寻求平衡
适用于大多数日常应用场景,生成有趣但不失严谨的内容
激发创意,提供新颖独特的想法
适合需要灵感和独特观点的场景,如头脑风暴、创意写作等
通过高级设置,自定义生成方式
根据需求,进行精细调整,实现个性化优化
这个多样性没有特殊要求其实也不用动,遇到特殊环境实时调节看效果就行了。
特别说一下精确模式,当bot中人设与逻辑只作为工作流的传参时就可以使用这个模式了
3、输入及输出设置
用于指定模型的输出格式等参数,通常包括以下设置:
根据自己的需求设置吧,免费版的都会有次数限制与token限制,这两个耗完之后都是不能再继续使用了,一般考虑的比较少,付费版的需要重点考虑了,因为付费版的使用多少扣多少钱。
我曾经制作了一个新闻助手,运行一次就消耗十几万的token,一次就把一整天的免费token用完了,工作流中的大模型节点都用不了了。
所以用免费版的时候要注意好对话的次数和大模型的token使用量




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
