本文基于 demo 代码,初步认识 Agent 如何通过三层记忆体系实现上下文管理。
一、上下文管理是什么
在与大语言模型(LLM)交互时,上下文指的是当前对话窗口中包含的所有信息,以 messages 列表的形式存在:
~/ai-agent
messages = [
{"role": "system", "content": "你是一个有帮助的助手"},
{"role": "user", "content": "我叫张三"},
{"role": "assistant", "content": "你好张三!"},
...
]
什么是上下文?归根结底,驱动"上下文工程"概念兴起的根本原因,是 LLM 的上下文窗口限制。若窗口无限,一切工程皆可免——尽数灌入即可。正是有限的视野,迫使我们不断锤炼这一技艺:在有限的 Tokens 内,如何筛选、组织、压缩、动态填充最相关、最完整、最有序的信息?这包含了:
- 信息优先级判断:何为当前任务的关键?
- 信息完整性维护:如何在分块 / 压缩中最大保留语义?(如摘要、结构保留)
- 信息动态组合:如何实时整合外部数据源(API/RAG)与内部状态(历史 / 记忆)?
- 信息交互:洞悉大语言模型与人脑对信息处理的微妙差异。
在大语言模型应用中,上下文(Context)指的是模型在生成回复时所依赖的所有历史信息,包括但不限于:
- 用户与 AI 之间的完整对话历史(messages)
- 用户的个人偏好、性格特征、情感状态
- 之前的决策、承诺或未完成的任务
- 外部知识或记忆片段(如过往聊天记录摘要)
这些信息共同构成了 AI 理解当前对话的"背景",决定了它能否做出合理、连贯、个性化的回应。而"上下文工程"的核心追求,正是在 LLM 有限的上下文窗口内,精准注入使其高效工作所必需的完整信息——这也是 AI 应用开发从第一天起就面临的核心挑战。
LLM 本身是无状态的——它不会自动记住之前的对话,每次请求都需要将完整的历史作为输入。这就引出了上下文管理的核心问题。
二、上下文管理的三大挑战
| 问题 | 描述 | 后果 |
|---|
| 上下文窗口限制 | 每个 LLM 都有最大 token 数(如 4K、128K) | 对话过长时触发截断或报错 |
| 信息淹没 | 早期重要信息被冗余对话稀释 | 回复质量下降,答非所问 |
| 跨会话丢失 | 程序重启后内存清空,模型完全"失忆" | 无法构建长期用户认知 |
如何动态地、智能地构建和维护整个上下文窗口(Context Window)?常见的方法有三种:
- 上下文压缩(Context Compression):在保持关键信息的同时,删减不重要或冗余的内容,以节省空间。
- 对话历史管理(Conversation History Management):在多轮对话中,如何有效地总结和管理之前的对话历史,确保对话的连贯性,同时避免上下文窗口被陈旧信息占满。
- 动态上下文注入(Dynamic Context Injection):根据对话的进展或用户的行为,实时地从外部源(如用户画像数据库、实时传感器数据等)拉取信息并注入到上下文中。
向量数据库 + 检索增强(RAG for Memory)是目前最主流的长期记忆方案:将用户的历史对话、关键事件、情感状态等信息向量化存储,并在需要时通过语义检索召回相关记忆。
技术流程如下:
- 记忆编码:将每条重要对话或事件通过嵌入模型(如 BGE、text-embedding-3-small)转化为向量,存入向量数据库(如 Pinecone、Weaviate、Milvus)。
- 记忆检索:当用户发起新对话时,根据当前输入语义检索最相关的记忆片段。
- 上下文注入:将检索到的记忆作为补充上下文插入 prompt,辅助生成回复。
本 demo 就基于向量数据库 + 检索增强 + 上下文压缩方案编写。
三、三层记忆体系架构
本 Agent 通过三层记忆机制解决上述问题:
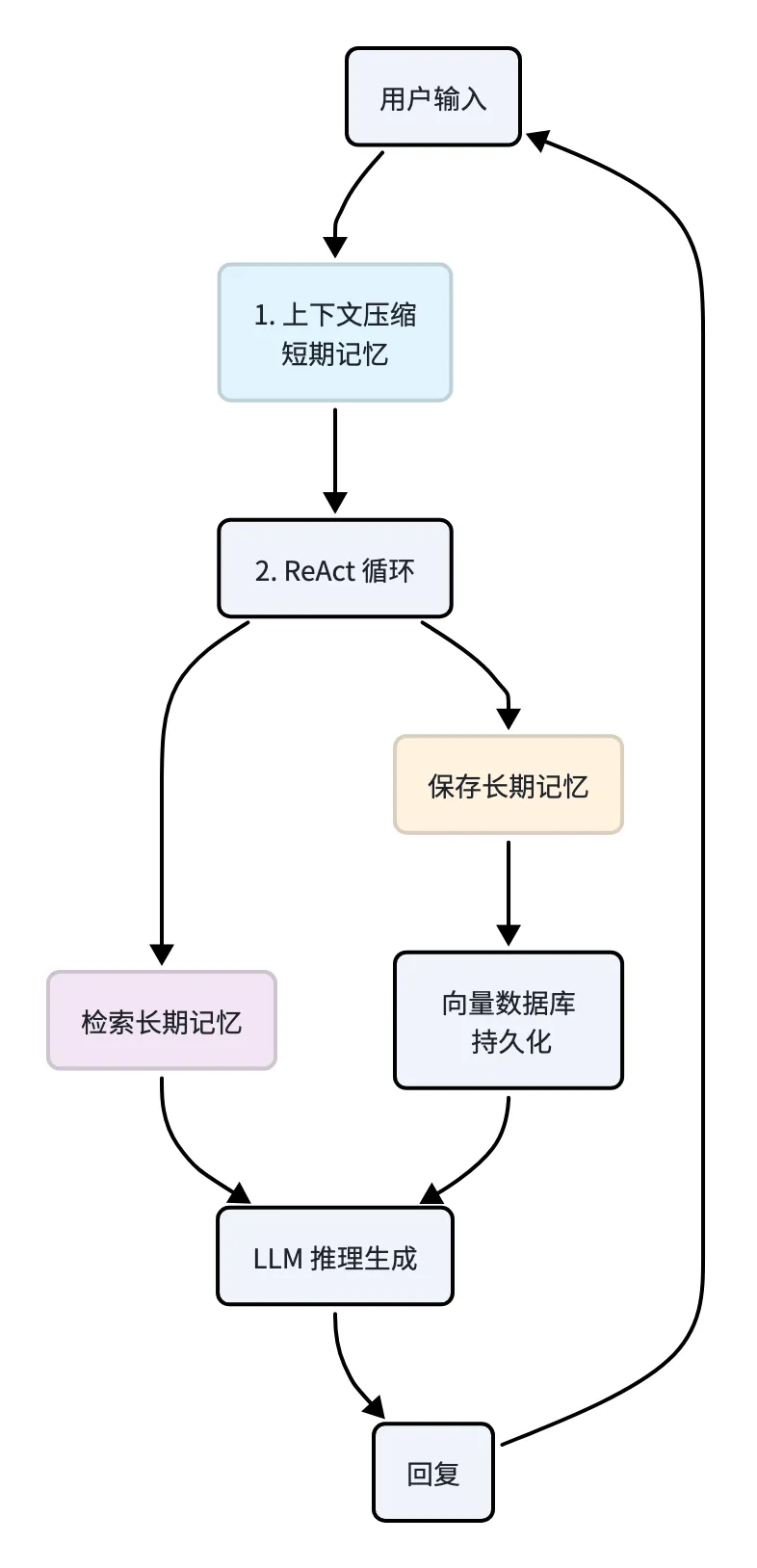
| 层级 | 机制 | 存储位置 | 作用范围 |
|---|
| 短期记忆 | messages 列表 | 内存 | 当前会话 |
| 长期记忆 | save_long_memory / query_long_memory | JSON + Embedding | 跨会话持久化 |
| 上下文压缩 | compact_context | 内存替换 | 当前会话,节省 token |
四、核心代码实现解析
4.1 长期记忆存储:save_long_memory
当用户提到重要偏好、习惯、规则时,LLM 自动调用此工具将信息持久化:
~/ai-agent
def save_long_memory(content: str) -> str:
data = load_memory_db()
data["docs"].append(content)
data["embeddings"].append(get_embedding(content))
save_memory_db(data)
return f"✅ 记忆已保存:{content[:30]}..."
流程:
- 从
long_memory_db.json 加载已有记忆 - 调用 Ollama Embedding API(
bge-m3 模型)将文本转为向量 - 原文本和向量分别存入
docs 和 embeddings 列表 - 持久化到本地 JSON 文件
关键设计:由 LLM 自主判断何时该保存,而非由用户手动触发。工具描述中明确定义了触发条件——用户提到偏好、习惯、规则、秘密等需要长期记住的内容。
4.2 长期记忆检索:query_long_memory
当回答需要历史信息时,通过语义相似度召回相关记忆:
~/ai-agent
def query_long_memory(query: str, top_k=2) -> str:
data = load_memory_db()
if not data["docs"]:
return "暂无长期记忆"
q_emb = get_embedding(query)
db_embs = data["embeddings"]
scores = np.dot(q_emb, db_embs.T) / (
np.linalg.norm(q_emb) * np.linalg.norm(db_embs, axis=1) + 1e-8
)
top_idx = np.argsort(scores)[::-1][:top_k]
memories = [data["docs"][i] for i in top_idx if scores[i] > 0.5]
return "📌 相关记忆:
" + "
".join(memories) if memories else "未找到相关记忆"
检索策略:
- 余弦相似度:语义相近的文本会得到高分
- 阈值过滤:
scores[i] > 0.5 过滤低相关度结果 - top_k 限制:默认返回最相关的 2 条记忆
4.3 上下文压缩:compact_context
当对话历史过长时,调用 LLM 将其压缩为精简摘要:
~/ai-agent
def compact_context(messages: list):
message_json = json.dumps(messages, ensure_ascii=False)
if len(message_json) <= 100:
return messages
compact_prompt = (
"将以下对话历史压缩为精简摘要,"
"保留核心信息和关键事实,去除冗余,"
"压缩后不能超过100个字符:
" + message_json
)
compact_response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": compact_prompt}]
)
return [{"role": "assistant", "content": f"【历史对话摘要】{compact_response.choices[0].message.content}"}]
触发方式:
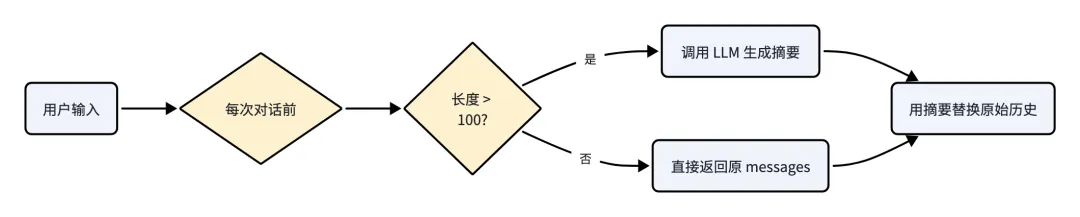
- 自动触发:每次对话前自动检查并压缩
- 手动触发:用户输入
/compact 指令强制压缩
注意:这是有损压缩——工具调用过程等细节会被丢弃,仅保留核心事实。压缩后无法恢复原始对话。
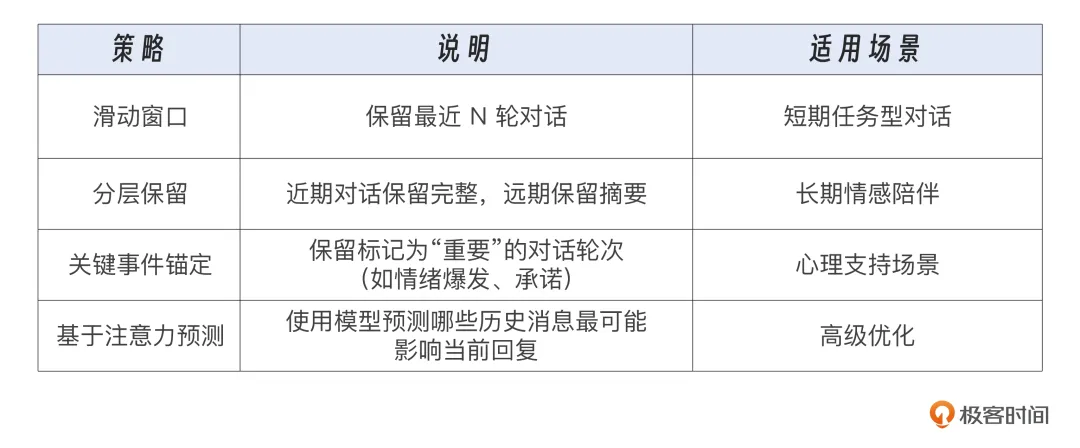
除本例的实现方式外,还有几种上下文裁剪策略可供参考:
五、ReAct 循环与工具调用
Agent 的核心循环采用 ReAct(Reasoning + Acting)模式:
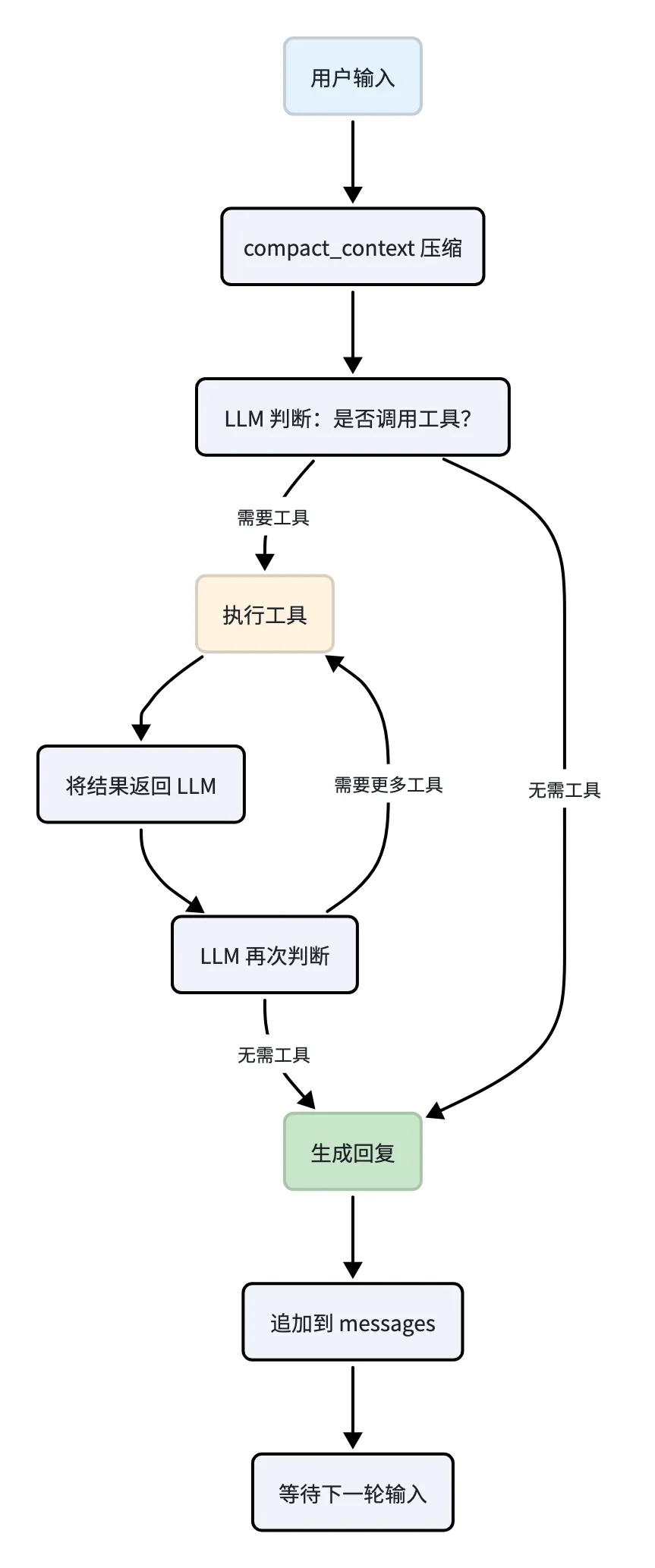
代码核心逻辑:
~/ai-agent
while True:
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=TOOLS,
tool_choice="auto"
)
message = response.choices[0].message
if hasattr(message, 'tool_calls') and message.tool_calls:
messages.append(message.to_dict())
for tool_call in message.tool_calls:
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
tool_result = TOOL_MAP[tool_name](**tool_args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_name,
"content": tool_result
})
else:
reply = message.content
break
六、完整消息流转示例
- 用户输入:"我叫张三,我喜欢用 Python"
- 压缩上下文(如需要):
messages = compact_context(messages) - 加入用户消息:
messages.append({"role": "user", "content": "..."}) - 第一次 LLM 调用:LLM 判断需要调用
save_long_memory - 执行工具:向量化 → 保存到 JSON → 返回结果
- 将工具结果返回给 LLM
- 第二次 LLM 调用:生成最终回复
- 完成闭环:回复追加到 messages
七、工具定义与 LLM 自主调用
工具的 description 字段是让 LLM 自主决策的关键:
~/ai-agent
TOOLS = [
{
"type": "function",
"function": {
"name": "save_long_memory",
"description": "当用户提到重要偏好、习惯、规则、秘密等需要长期记住的内容时,自动保存",
"parameters": {
"type": "object",
"properties": {"content": {"type": "string", "description": "要记住的内容"}},
"required": ["content"]
}
}
},
{
"type": "function",
"function": {
"name": "query_long_memory",
"description": "当回答用户问题需要历史偏好、习惯、规则时,先检索记忆",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string", "description": "检索关键词"}},
"required": ["query"]
}
}
},
]
设计技巧:description 描述的是触发场景而非技术细节。LLM 会根据用户意图自主判断何时调用、调用什么工具,实现近似于"智能助理"的体验。
八、总结
| 函数 | 记忆类型 | 触发方式 | 存储介质 | 核心价值 |
|---|
save_long_memory | 长期记忆 | LLM 自主调用 | JSON + Embedding | 跨会话持久化 |
query_long_memory | 长期记忆 | LLM 自主调用 | 向量相似度检索 | 语义召回历史信息 |
compact_context | 短期记忆 | 自动 + 手动 | 内存替换 | 节省上下文窗口 token |
核心理念:短期记忆不溢出、长期记忆不丢失。上下文压缩避免窗口耗尽,向量检索实现语义记忆召回,共同支撑 Agent 的长期交互能力。
源码路径:
https://github.com/mambo-wang/AI-Agent/blob/main/agent%2Ffirst_agent%2Fagent_ollama.py
Embedding 模型:Ollama bge-m3
LLM 模型:MiniMax-M2.7


