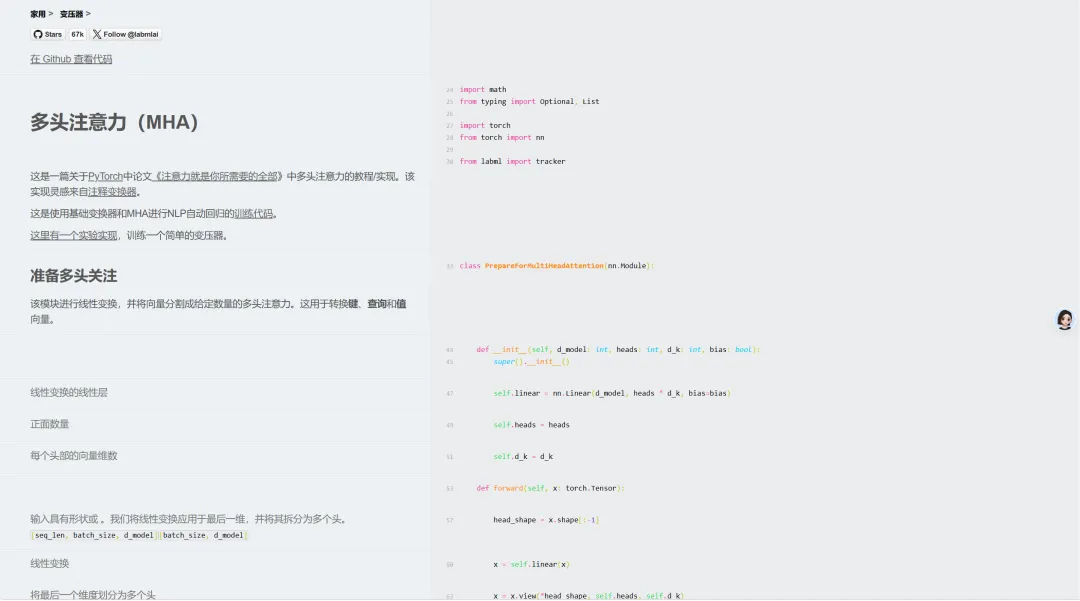
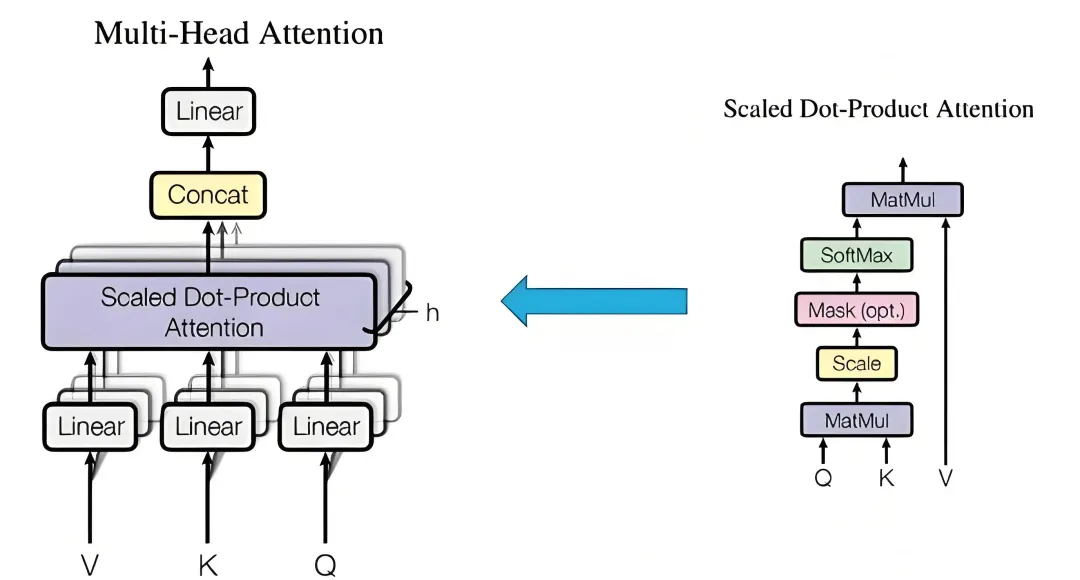
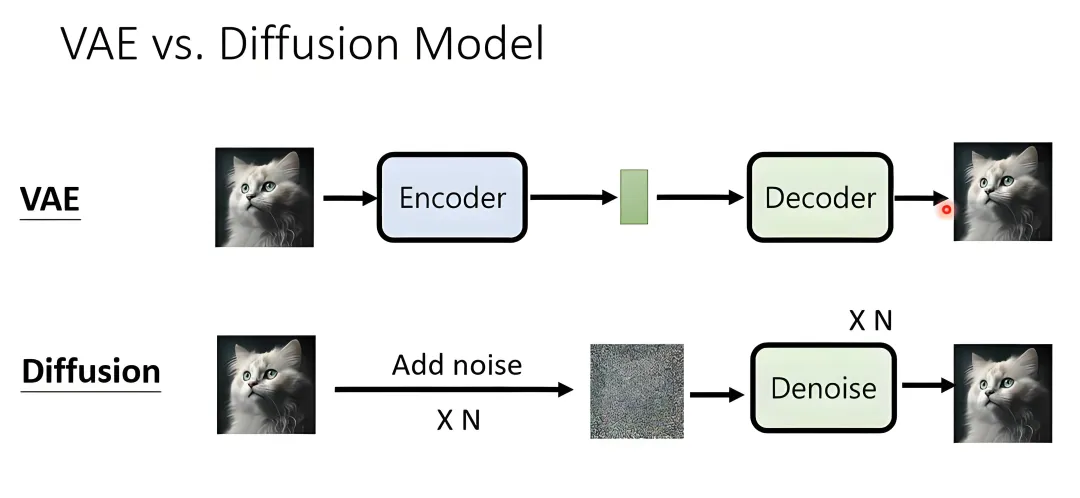
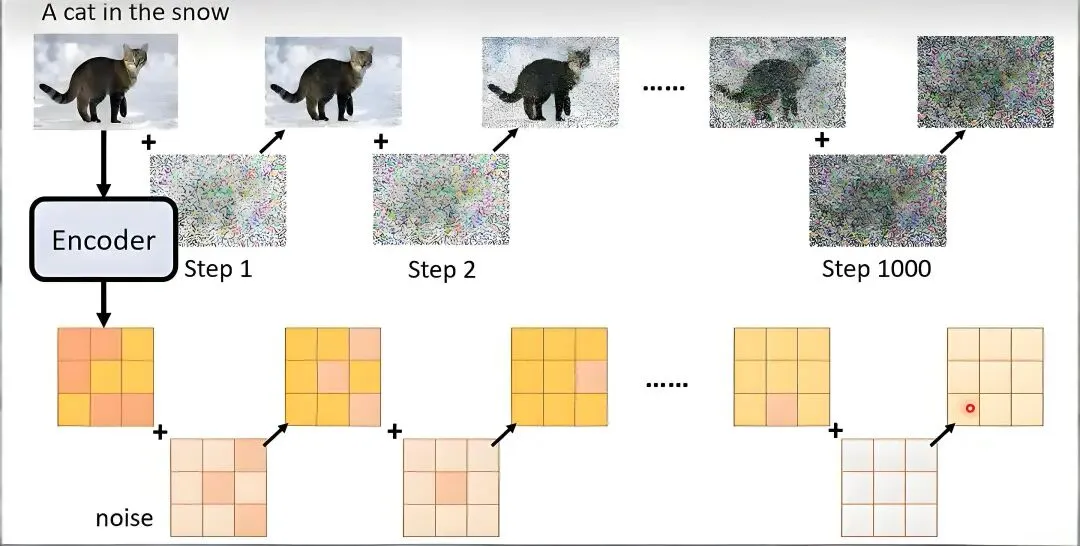
很多同学在学习深度学习的时候,想要根据数学公式去复现一些模块,比如多头注意力机制、旋转注意力编码以及ViT等,通过复现这些模块确实有助于提升对理论的理解以及代码能力如果你还不知道什么模块可以拿来复现练手,那这一篇内容非常适合你深度学习里面大部分模型模块都涉及到,除了可以拿来复现练手,还可以作为模型代码库,直接调用即可,省去部分的代码工作量这一期主要是给大家推荐一个爆火的深度学习模块复现项目,适合新手小白,也适合想要做科研的同学将其作为代码模板知识库注意:每一个模块都有理论和代码对应的解释,非常方便,比如下面的多头注意力机制,左边是对应数学理论,右边是相应的代码,结合来看就行这一部分集合了大量和Transformer相关的内容,包括JAX, 多头注意力机制,Flash attention,transformer blocks,旋转位置编码,GPT模型结构,FNet, 免注意力的Transformer变体,掩码语言模型,Vision Transformer等,学完这些内容,达到了AI入门的初级水平,后续可以做一些项目去巩固DDPM 是基础像素域扩散模型,通过千步随机加噪与去噪实现图像生成,推理速度慢;DDIM 沿用 DDPM 训练权重,优化采样策略大幅缩减迭代步数、提升生成效率;LDM 引入 VAE 将图像压缩至隐空间做扩散运算,大幅削减计算开销,适配高分辨率生成;Stable Diffusion 基于 LDM 架构,融合 CLIP 文本编码、交叉注意力与 CFG 约束,搭配高效采样器,成为落地普及的文生图模型
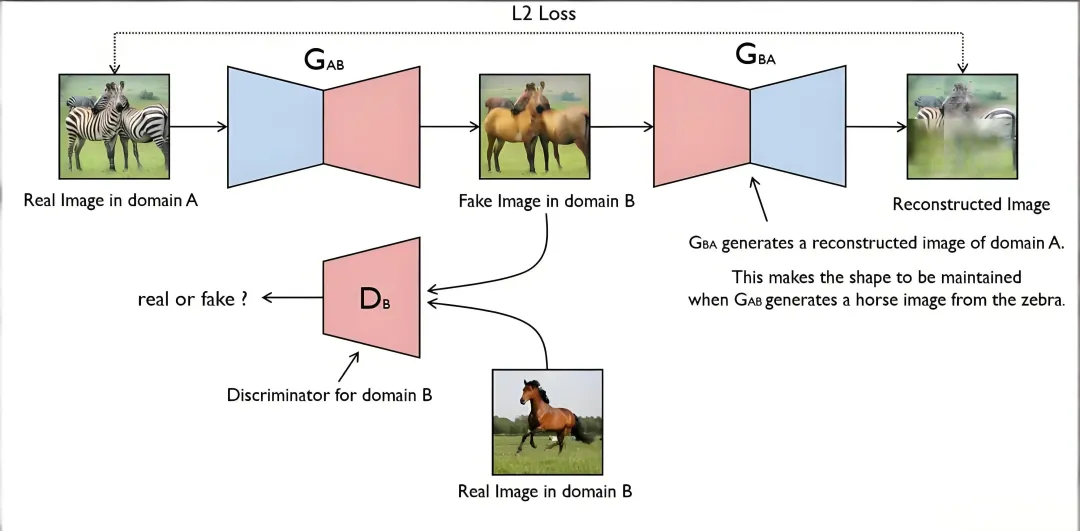
Original GAN 是对抗生成网络开山模型,依靠生成器与判别器相互博弈学习数据分布;深度卷积 GAN 将卷积结构引入网络,替代全连接层,大幅提升图像生成画质;CycleGAN 新增循环一致性约束,无需配对样本即可实现无监督图像风格转换;还有WGAN, WGAN-GP和StypleGAN2模型,学完这些生成对抗模型,基本上就掌握了这个领域的主要内容
第四部分:优化器
这一部分主要介绍Adam, AMSGrad, Noam, Rectfied Adam Optimizer,AdaBelief Optimizer和Sophia-G Optimizer,这些优化器大家日常训练深度学习模型的时候都会用到,是深度学习的基础内容
第五部分:归一化
这一部分主要介绍批量归一化,层归一化,实例归一化,群组归一化,权重标准化,DeepNorm几种常见的深度学习归一化方式,在大厂面试中,也经常会问到类似的问题,以及进行对比分析
贪心采样每次直接选取概率最高的词,生成结果规整但易重复刻板;温度采样通过温度系数缩放概率分布,数值越低输出越保守确定,越高随机性越强;Top-k采样仅从概率靠前的k个候选词里随机挑选,平衡流畅度与多样性;核采样限定累积概率阈值筛选候选集,动态选取合理范围词汇,兼顾生成质量与自然度,四类均为大模型文本解码常用策略。此外,还有LSTM模型,ResNet, U-Net,GAT模型等模型的介绍,基本上包括了深度学习各方面的内容,适合想要入门以及系统学习深度学习的同学进行学习资料获取:
1. 关注本公众号
2. 发送口令“深度学习模块”领取(人工回复可能有时差,都会发给大家的,不用着急)